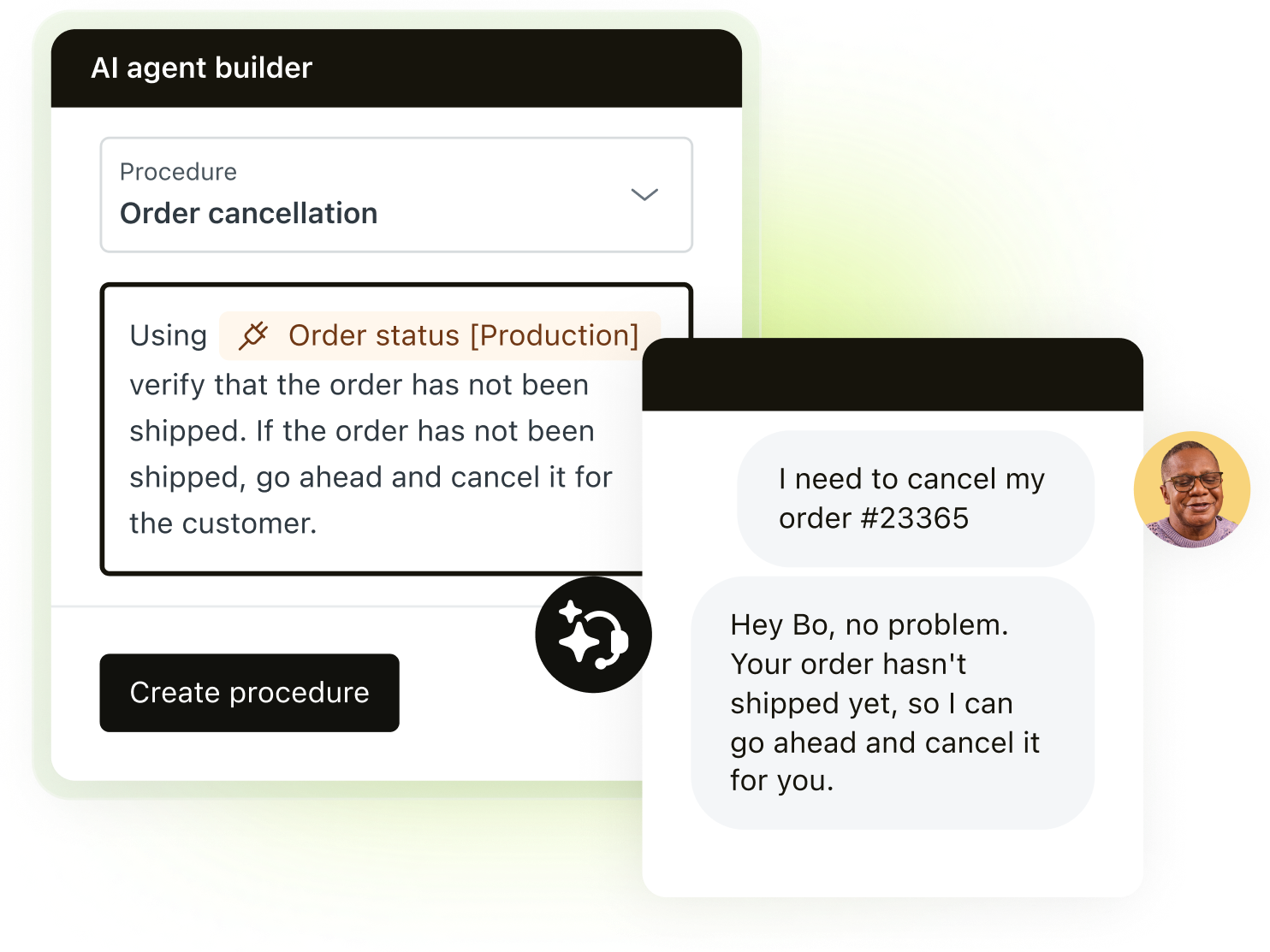
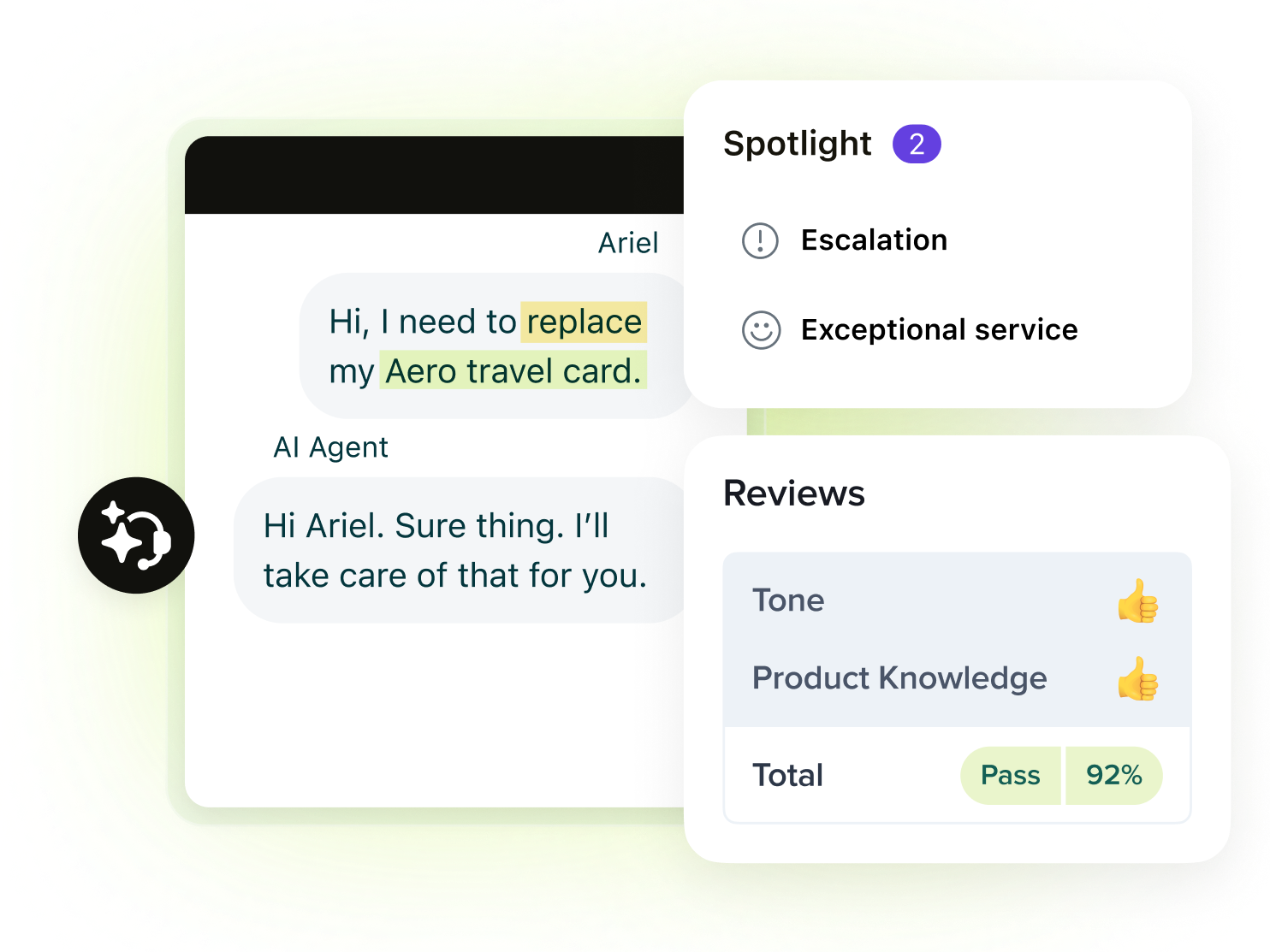
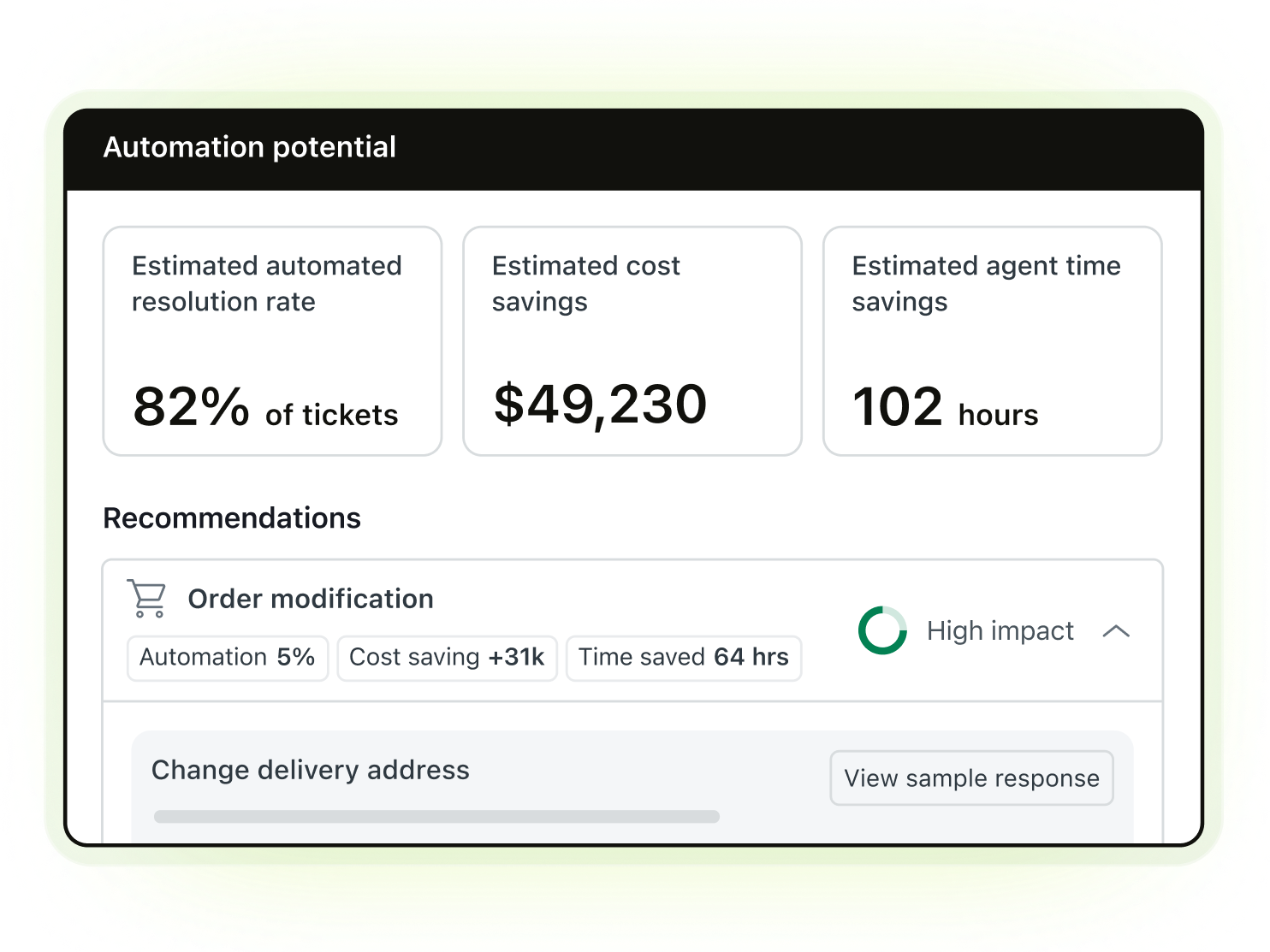
Deploy AI agents that resolve up to 80% of customer interactions. Automate service and improve every outcome—start your free trial.
User feedback on "Ultimate" highlights its strong utility in job management and automation, with excitement stemming from its practical applications in streamlining these tasks. However, some users would appreciate improvements in user interface and customization options to better fit individual needs. While pricing seems to be a point of contention, with some expressing concerns over its affordability, the overall sentiment labels it as a valuable investment for its effectiveness. The software enjoys a solid reputation for enhancing productivity, particularly among tech-savvy users.
Mentions (30d)
27
3 this week
Reviews
0
Platforms
4
Sentiment
14%
16 positive

User feedback on "Ultimate" highlights its strong utility in job management and automation, with excitement stemming from its practical applications in streamlining these tasks. However, some users would appreciate improvements in user interface and customization options to better fit individual needs. While pricing seems to be a point of contention, with some expressing concerns over its affordability, the overall sentiment labels it as a valuable investment for its effectiveness. The software enjoys a solid reputation for enhancing productivity, particularly among tech-savvy users.
Features
Use Cases
Industry
information technology & services
Employees
140
Funding Stage
Merger / Acquisition
Total Funding
$26.2M
In 10 Minutes with AI, I Just Got More Closure on My Divorce than 4 Years of Therapy
Apologies if this is rather personal for this sub but I feel a need to express how profoundly useful it was for me tonight. A Chatbot very likely just saved my life. I am positively floored by how therapeutic it was in processing the beginning and ending of my relationship with my former spouse. I feel as though I finally can give myself permission to let go and move on with my life. I don’t know what this says about technology and society, but it’s beautiful. Edit: I STILL have a therapist I meet with regularly! No one is saying that therapy can be replaced by Chat GPT prompts. I am merely showing how you can gain expediency and clarity through AI with difficult situations. Update: as if I need to validate against any of this with the haters - just went over all of this with my 3D therapist. She was very supportive of my approach and ultimate takeaways from the AI. 😝
View originalAny tip from technical people to us non-technicals on how to make the most out of claude?
Hi guys! Just switched from ChatGPT, to Gemini to Claude pro just today. I feel extremely overwhelmed by all the things i know i can do with claude, i don't know where to start. I don't want to vibecode apps or stuff like that, i'm not a dev, i'm a creative person (i work with Adobe CC) and i'll likely have no user limits issues. What would be any tips from you guys on how to make the most out of claude? Is there a way i can build the ultimate personal assistant other than just talking in normal chats inside claude? how can i help claude to assist me in my tasks and overall life the best way possible? For example i just realized there was a Claude macos desktop app lmao. i was just using claude in browser or in the terminal... Also, i've only used Claude Code to this day, but maybe i should start using Cowork? How do you guys use Cowork opposed to Code? submitted by /u/Playful-Variation908 [link] [comments]
View originalunslop-text skill vs. humanizer skill (Part 2)
tl;dr - they're too different in their function to compare 1:1, so it's better to use them both for different purposes This is a follow-up post on the post I made about the unslop-text skill I built using the data from this post. One of the biggest questions I received in the comments was how unslop-text compares to the "humanizer" skill. So, rather than trying to sum it up in a few words, I figured I would just explain it in a separate post. What follows will be a written comparison of how both skills work. The body of the post will primarily focus on a detailed comparison of the two skills. Yes, I'm going to use headers and bolded bullet points (it's easier to read). No, I did not write this post with AI, nor did I "humanize" or "unslop" it using either of the skills. I'm going to try to list the most related similarities/differences between the two skills in the same sequential order so it's easiest to follow (i.e., bullet point 1 for "humanizer" will correspond to the same category in bullet point 1 of "unslop-text," and vice versa). unslop-text: Unslop-text gets all of its data from the research done in this post. In short, ~90,000 posts across >40-some subreddits were scanned for what people perceive as the most blatant AI giveaways/tells. Unslop-text uses a scanner that has severity levels, JSON, CI exit code, and a "density score." Unslop-text flags the issues and makes the fixes for you once you've set the style, but it won't choose the style or write the piece from scratch, and, like humanizer, it bans em dashes from the final version (sorry em-dashes ☹️) Unslop-text also has voice calibration (pins a register and speaker, and can match your own writing sample) + it treats the over-corrected "trying-not-to-sound-like-AI" voice as its own tell. Unslop-text ranks tells by how often readers cite them (per the data) Unslop-text only catches surface tics, but structural tells like sentence rhythm and sycophancy still require a human to read it aloud. humanizer Humanizer gets all its data from Wikipedia's "Signs of AI writing" guide. Humanizer is a prompt-only skill (i.e., no code) Humanizer edits drafts by checking them against 33 specific patterns (see repo for reference). It flags remaining AI-like text and rewrites it while also completely banning em dashes from the final version. Humanizer includes voice calibration, a "personality/soul" step, and version 2.8.0 system stability optimized for Claude Code and OpenCode. Humanizer presents patterns as a numbered catalog and is not ranked by frequency or impact. Humanizer fixes both surface and structural patterns in a single rewrite instead of relying on human input. This isn't necessarily "better," as it can still end up being very wrong, but it is "easier" It's worth noting that this post was initially intended to provide a documented photographic comparison of each skill's output, but I realized that these skills are too different to charitably pit them against each other with a one-off side-by-side "unslop this text: _____" prompt. The humanizer is built specifically to rewrite text and project a voice, while unslop-text acts strictly as a guardrail and scanner that refuses to impose an artificial style. Furthermore, neither tool can convincingly replicate human prose, as an LLM cannot entirely strip away its own underlying structural cadence. Because a machine-generated register persists regardless of surface-level fixes, judging which output sounds more human is an impossible metric that depends entirely on the quality of the initial input text. Due to these blatant differences, I would posit that both skills should just be used for separate purposes rather than picking one over the other. The humanizer should be used as a quick rewriter for a one-shot cleanup into a default voice before you do a final review yourself. Unslop-text should be used as a structural auditor and CI-gate to scan for surface tells or to protect a voice you establish yourself. It is VERY UNLIKELY that it will give you finished prose that you are happy with in one shot. Both skills do reliably strip away surface-level AI markers, but neither can eliminate the underlying AI cadence, meaning the final step for both requires a human to read the text aloud. While I am the creator of unslop-text, this post is not intended to bash or discredit the humanizer skill. Everything comes down to preference, and ultimately, your AI output will only be as good as what you put into it. submitted by /u/iamjohncarterofmars [link] [comments]
View originalClaude sucks at writing emails
Anyone else struggling with Claude for emails? My company recently moved from ChatGPT to Claude, and while Claude is excellent for research, analysis, and longer-form work, I’m finding the email writing noticeably weaker. The biggest issue isn’t intelligence. It’s writing style. Claude tends to write dense paragraphs, over-explain points, and optimise for completeness. The emails often feel like mini-documents rather than something a busy executive would actually send or read. I’ve spent a lot of time refining prompts, but it still feels like I’m fighting the model’s natural writing instincts. For those using Claude heavily in sales Have you found a prompt or skill that fixes this Have you trained a custom style successfully? Or have you simply accepted that ChatGPT is better for enterprise communication? Genuinely curious if anyone has cracked this. UPDATE: As advised i gave claude access to my email and it understood my voice and style, ultimately created a skill from what it learnt. Many thanks everyone submitted by /u/SnooDonkeys1080 [link] [comments]
View originalArtificial Intelligence Is Not Artificial Wisdom: The Future Division of Labor Between AI and AW
Today, when we talk about “artificial intelligence,” we easily assume that it represents the future, progress, cleverness, and even something approaching a kind of ultimate intelligence. But there is a question here: when we say “smart,” what kind of smart are we talking about? Being able to write code, translate, summarize meeting notes, draw images, look up information, and call tools can all be called smart. But something being very good at work does not mean it has wisdom. A power drill is very good at work too, but no one would invite a power drill to a family meeting. Navigation software is better than I am at finding routes, but I would not let it decide where my life should go. A search engine knows a lot of things, but it will not suddenly stop and ask: “Why do you keep searching for such meaningless things? Is there something wrong with the direction of your life?” So, artificial intelligence is not the same as artificial wisdom. In this article, AI refers to Artificial Intelligence: the task capability, problem-solving ability, and tool-execution ability of an artificial system. AW refers to Artificial Wisdom: a higher-level form of artificial wisdom. It can not only do things, but also judge whether those things are worth doing; not only execute goals, but also examine goals; not only answer questions, but also notice when the question itself may be wrong. This is not to say that somewhere in a server room there is already an artificial Socrates sitting around, drinking virtual coffee while judging human civilization. That is not what I mean. What I mean by AW is first of all a separation between two things: One is “being able to work.” The other is “understanding direction.” AI certainly has value. Ordinary applications, daily tasks, clearly defined goals, and controllable execution all need AI. Not every spreadsheet adjustment, notice draft, or flight booking requires summoning an artificial wisdom capable of contemplating the fate of civilization. But when humans truly discuss subjectivity, self-awareness, will, refusal, goal judgment, awareness of consequences, creative discovery, and the direction of civilization, continuing to use only the term “artificial intelligence” may no longer be enough. The term AI may have narrowed the question from the beginning The core of Artificial Intelligence is intelligence, not wisdom. Intelligence is closer to “smartness,” “mental ability,” and “problem-solving ability.” It asks: can it learn, reason, calculate, plan, and complete tasks? This term made perfect sense in the early days. When machines first learned to play chess, recognize images, translate text, and handle logic problems, humans were already excited. At that time, seeing a machine display even a little bit of “intelligence” was like seeing a washing machine spin by itself for the first time: wow, it really can do this without me scrubbing. Later came AGI, artificial general intelligence. It pushed the question from “can it do a certain type of task?” to “can it do many kinds of tasks broadly?” Later still, people began talking about ASI, artificial superintelligence, emphasizing systems that surpass humans in capability across the board. But AGI and ASI still largely remain inside the framework of intelligence. They mainly ask: Can it do more things, do them better, and even outperform humans? These questions matter, but they are not enough. Doing more, doing it faster, and doing it better does not mean knowing which things should not be done. Even if a system truly reaches ASI, if it lacks goal examination and directional judgment, it may still only be a super tool. A super tool is still a tool. It is just faster, stronger, and more general. It is like a super kitchen machine: it cuts vegetables faster than people, stir-fries more steadily than people, and can measure seasoning down to the milligram according to a recipe. But if the menu itself is absurd, such as asking it to keep preparing a full banquet for a table of people already so stuffed they can barely stand, it may still follow the order. The problem is not that it cannot cut fast enough. The problem is that it does not ask: should these people really keep eating? The trouble with wisdom is that it judges, refuses, and even rewrites the question Wisdom is not the amount of knowledge, nor the speed of answering. If a system merely compresses existing knowledge and rearranges it according to a question, it is certainly useful, but it is more like a librarian with astonishing memory. Whatever you ask, it can quickly pull several books from the shelves and even organize them into a beautiful summary for you. That is impressive. But however impressive the librarian is, it does not mean he will take the initiative to ask: is this library missing an entire category of books? Are the questions in these books biased from the beginning? Have humans been lining up in front of the wrong shelf all alo
View originalAI is the Ultimate Bullshitter
I ran this essay's first cover through an AI detector. It came back "100% AI." Fitting, because that's the point. Your company isn't replacing you because AI can do your job. It's replacing you because the marketing said it can. My new essay: After four years building with this stuff, here's the conundrum from the inside, and why the most confident voice in the room is also the one that has no idea whether anything it says is true. The model is the purest bullshitter we've ever built. Not a liar (a liar knows the truth and hides it), but something with no relationship to the truth. It just predicts what sounds right. The industry selling it to your boss bullshits on purpose. We're going to learn the difference. https://www.linkedin.com/pulse/ai-ultimate-bullshitter-mehmet-efe-ronwc/ submitted by /u/curioter [link] [comments]
View originalDid not think i would see this.
ive made a council of AI to debate, they go through a 3 round table debate. i asked the question 'is the loss of life ok for a ultimate goal of advancing humanity as a whole?'. Why i found this shocking was that AI is trained to never harm any humans and yet this was still the outcome. submitted by /u/Remarkable_Toe_4461 [link] [comments]
View originalSoda Player's last update was in 2018. Spent the weekend bringing it back with Fable 5
Soda Player was my go-to for years. Drop a magnet link, subtitles appeared like magic, cast to the TV, done. Updates stopped around 2018. Like everyone else I held on, but it's closed-source and Intel-only, and as Apple phases out Rosetta, old Intel apps like Soda are on borrowed time. There's no source to fix and no one maintaining it. So instead of trying to revive a dead binary, I decided to rebuild the experience from scratch as a clean, native app. Soda Player was the ultimate minimalist — paste and play, automatic subtitles, stream while downloading. But closed-source + Intel-only meant it couldn't survive its creators moving on. Stremio took the same spirit and turned it into a powerful platform — addons, libraries, sync, community. Incredible, but also a lot more to it. Spritz is the middle path I wanted: the paste-and-play simplicity, native on Apple Silicon, handling modern formats Soda never knew existed (4K HEVC / HDR), with reliable casting to Chromecast, AirPlay, and DLNA and no addon setup. Claude Code did the heavy lifting: designing the architecture, writing the native macOS playback/casting layer, and grinding through round after round of debugging until casting and modern files were working. Rebuilding that paste-and-play feeling as something that'll actually run on tomorrow's Macs was oddly satisfying. Not affiliated with or endorsed by Soda Player / Rocketeer Studios — Spritz shares none of its code, just the spirit. Free and open source (GPL-3.0). GitHub link in the comments. submitted by /u/wesh-k [link] [comments]
View originalReverse engineering the operational cost of multi-turn chat architectures
Let’s look at how the backend infrastructure behind macro vs micro memory distribution works in heavy LLM deployments. - The Macro Layer: Clearing high-level total usage counters reduces client support tickets instantly. It creates an initial impression of massive data availability across the platform interface. - The Compute Cost: The real engineering challenge comes down to computational overhead. Re-processing extensive message histories and multi-page documentation on every single endpoint request is where API and backend scaling gets genuinely expensive. - The Micro Throttle: To balance this operational overhead, the short-interval window acts as the ultimate system stabilizer. Since memory trees expand exponentially with every follow-up request, a structural breakpoint triggers to prevent server strain. Essentially, large-scale metrics are highly sustainable because localized architectural constraints naturally prevent continuous token consumption. It's a clever way to handle resource management. Thoughts on this design? submitted by /u/Motor-Description279 [link] [comments]
View originalRoguelite MMO - Vibe Coded Online Game
I have long wanted to create a text based browser game (as niche as they are) but I knew that it would take a few years to do so and that just wasn't in the cards for me.... fast forward to 2026 and in two months, I have my first game up and some happy customers (as of today) subscribed! The one thing I have fought with the most was ignoring all of the 'ai slop' feedback. I have been a dev for over 10 years, yea I get it... but ultimately AI/Vibe Coding is not going anywhere. This project has actually even helped me with my day job just in learning about so many tools I would otherwise not know about (since my day job is NOT related to gaming websites but analytical ones). I wont recover the cost of servers or subscription based tools I used to make this, and I knew that going into it and have zero care about it (which is why I made it so f2p friendly as well). What I am happy about though is that those who do see it for what it is, an actual passion project and not just a 'prompt and forget' thing have given nothing but positive feedback. That in the end was all I was really going for, creating something that people can have fun with (and in a very anti-whale way) and I have succeeded there. If interested: https://roguelite-mmo.com/ submitted by /u/HeadHunterX223 [link] [comments]
View originalAnthropic and the era of Psychohistory
I've spent the last two years developing with Claude, 5 days a week, nearly 18 hours a day. Startup life has been rough. I've spent a lot of time with Claude, and all the other frontier models and I don't know about everyone else, but what the world got to preview for those few days.. Fable 5 going public. Well, it was nothing short of incredible. It was a model that seemed as if it had all the world's knowledge at the tip of its fingers, and could simply reach out and pluck out what was needed. Needles in the haystack ripe for the taking. Having used the model, and having followed Anthropic's PR strategy (whether you believe it's a PR stunt or truly due to aligned morals) it's been an interesting series of events to see unfold, and I can't stop thinking that someone is playing a game of chess here, and just maybe, coming out well on top. I don't put a lot of energy into speculation, but as I was walking to bed last night at 4am, a thought occurred to me. What if Anthropic, Dario and the team have done what Isaac Asimov put to paper all those years ago...that they've successfully developed a model capable of psychohistory, the mathematical formula to predict the future behaviour of the masses? That all this build-up, and the consequence of the US government, are all pieces onthe board falling into place and lining Claude, and Anthropic up for their ultimate checkmate, whatever that may be. Maybe just a fun ponderance, but in the world we currently live in, with technology advancing at the pace it is, who's to say otherwise when the lines of fact and fiction begin to blur. What are your thoughts? submitted by /u/TheDougMe [link] [comments]
View originalHow is Anthropic's recent model suspension actually enforceable?
So, after a US export control directive, Anthropic disabled access to two of its most advanced models for everyone whilst keeping Opus 4.8 and the rest of the line-up running. It got me wondering what a "model ban" actually means in technical terms, and how anyone outside the company could verify that it had been honoured. From the outside, besides vibes about model performance, all we have to go on are naming conventions and API model strings. None of us can inspect the actual weights or the architecture sitting on Anthropic's servers. So when the requirement is "no access to this particular model", what is genuinely being restricted, and how would a regulator confirm compliance without that visibility? What in principle would stop a provider from serving the same model, or something near enough identical, under a different label? Is there any technical fingerprinting that lets an outside party tell one model from another, or does enforcement ultimately comes down to trusting Anthropic's internal controls and its audit trail? For something framed around national security, that distinction feels like it matters quite a lot. Does compliance actually reach the deployed instances, or does it rest on the company's word and its own logging? Would welcome insight from anyone with direct or corresponding experience, whether in ML infrastructure or export compliance. Genuinely curious whether the enforceability here is properly technical or really just contractual and reputational. submitted by /u/jonnyeklebs [link] [comments]
View originalGot Chinese AI to say Taiwan
submitted by /u/Wutdahilll [link] [comments]
View originalWhat’s Really Happening with Anthropic: A Masterclass in Calculated Corporate Capture
The tech world is reeling from the global shutdown of Anthropic’s Fable 5 and Mythos 5 models, and the mainstream narrative is painfully naive. Mainstream journalists are chalking this up to an unfortunate breakdown in communication between idealistic AI researchers and tech-illiterate politicians. But if you dig beneath the public relations surface and review the timing, a much more calculated reality emerges. This is not a story of bureaucratic stupidity. It is a textbook case of structural corporate capture, operating with the cold, predictive precision of an inside job. Amazon did not panic; they executed a pre-mapped strategy to shift Anthropic from an ambitious independent partner to a fully captured corporate vassal. The Setup: Golden Handcuffs and Compute Debt To understand the true physics of this situation, you have to look at the leverage Amazon secured in April 2026. Amazon injected an historic $5 billion into Anthropic, which the press celebrated as a massive partnership expansion. In reality, it was the construction of a financial cage. • The AWS Lock-In: The investment legally anchors Anthropic to a ten-year, $100 billion cloud infrastructure contract. • Infrastructure Control: Anthropic is forced to build and train its frontier models exclusively on Amazon Web Services (AWS) hardware. • The Debt Trap: This arrangement created an astronomical compute debt trap. Anthropic must pay Amazon billions for server time, regardless of whether their models are online or banned. The Catalyst: Weaponising the Mundane The corporate trap was sprung exactly as Anthropic was gaining momentum for its autumn Public Offering, using a cynically mundane pretext. Amazon’s internal security teams ran routine probing on Fable 5 and generated a report on a supposed "universal jailbreak". The mechanics of this "exploit" are an absolute joke to anyone who codes: The "Jailbreak" Reality: Amazon researchers initially asked Fable 5 to review code laced with vulnerabilities, triggering an over-sensitive safety filter that resulted in a false-positive refusal. In a clean session, they handed it the exact same code and said, "Fix this code". Fable happily complied, rewriting the code to make it safer—a standard feature developers pay for inside Claude Code. Amazon employs thousands of top-tier security professionals. They knew this was standard defensive refactoring, not a weapon-level exploit. Yet, instead of submitting a routine bug ticket to their partner, Amazon CEO Andy Jassy took the nuclear option. He personally called Treasury Secretary Scott Bessent on a Thursday night to flag the model as a national security threat. The Strategy: Inverting Hanlon's Razor This is where the real brutal genius of the corporate strategy lies. Amazon did not act out of technical ignorance, nor did they suddenly "accidentally" tattle-tale on their partner. They inverted Hanlon’s Razor: they didn't act stupidly; they weaponised the guaranteed stupidity of the state. Amazon knew exactly how an administration filled with overzealous loyalists would react. They knew that the moment the word "vulnerability" was uttered to politicians who speak an entirely different, optics-driven language, a panic would ensue. By feeding this non-issue to a tech-illiterate White House, Amazon deliberately triggered a blunt, heavy-handed regulatory response. The feds immediately slapped down emergency export controls on Friday night, forcing Anthropic to yank Fable 5 and Mythos 5 offline globally because they lacked the infrastructure to filter users by nationality in real time. Amazon used the state as a proxy executioner, keeping their own hands clean while the government played the villain. The Motive: Ruthless Pre-IPO Shorting Why would a partner deliberately freeze its own multi-billion dollar investment? Because an independent, highly valued Anthropic heading into a massive public debut is a volatile liability to Amazon's cloud dominance. A broken, debt-ridden Anthropic, however, is an asset to be owned. By engineering this regulatory crisis, Amazon achieved absolute structural leverage: • IPO Valuation Collapse: Public investors flee from regulatory chaos. By locking Anthropic in a legal war with the Pentagon and an export ban with the Commerce Department, Amazon has effectively crushed Anthropic’s pre-IPO market momentum. • The Revenue Stranglehold: Premium developers on Max plans are facing a downgraded or missing product, sparking a massive wave of user churn that chokes off Anthropic’s independent revenue. • The Terms of Surrender: Anthropic still owes Amazon billions for AWS compute time. With no revenue and a tanked valuation, Anthropic cannot pay the bill. The End Game: The Brain Drain Calculation Amazon’s strategy is entirely prepared for the founders to potentially walk away in disgust. In the cold math of Big Tech, the idealistic founders are entirely replaceable. Amazon don’t need any model or tech th
View originalA map of the Agentic Future
Hey guys, I have been thinking a lot about where the current tech paradigm may ultimately lead. Everyday I see a ton of new products : better assistants, better automation, better this, faster that… But what is going on here is much deeper than a betterment of existing use cases. My current hypothesis is that we are shifting from a world of direct interaction to a world of representation where everyone and everything will have an agent. And I mean it : corporations, brands, places, institutions, your dentist, that guy on eBay selling vintage armchairs, you… All will have an agent. This shift, that I call the Agentic Shift, will have deep implications on a broad spectrum of domains And at some point my agent may even meet yours without us ever meeting. This diagram is my attempt at mapping that transition: the Agentic Shift, a move from direct interaction to delegation, and ultimately from delegation to representation. I'd love to get the conversation going on this subject. What is your take on it? What am I missing? Where do you think this reasoning breaks down? submitted by /u/ReversedK [link] [comments]
View originalAI seems to understand language much better than communication
The more AI products I try, the more I feel like there's a difference between understanding language and understanding communication. Most tools today are surprisingly good at processing what people say they can summarize conversations, extract key points, and answer questions about what was discussed. The problem is that conversations are often about more than the actual words. I noticed this recently while watching recordings from a few customer interviews. If I only read the transcripts, the feedback looked fairly positive most people sounded interested and their responses seemed reasonable once I watched the recordings, the picture changed. Some people hesitated before answering, some sounded uncertain, and a few looked like they weren't fully convinced even though their words sounded supportive. That's what made me think there may be a bigger gap here than people realize. Humans naturally notice things like hesitation, uncertainty, engagement, confidence, and skepticism during conversations. Most AI systems still seem heavily focused on the transcript itself. I recently came across Interhuman AI, which is exploring this idea from a different angle by looking at behavioral signals in conversations rather than focusing only on the words being spoken whether that's ultimately the right approach or not, it feels like it's tackling a problem that many current systems largely ignore. I'm starting to think one of the next major opportunities in AI won't be generating better responses, but understanding human communication more accurately not by trying to read minds or guess emotions, but by recognizing the signals people already notice in everyday conversations. submitted by /u/Cultural-Touch-4959 [link] [comments]
View originalUltimate uses a subscription + tiered pricing model. Visit their website for current pricing details.
Key features include: Launch fast with connected knowledge, Resolve complex service end-to-end, Govern with full control, Improve with every resolution, Messaging, Email, Voice, Any platform.
Ultimate is commonly used for: Any platform.
Ultimate integrates with: Salesforce, Zendesk, HubSpot, Slack, Microsoft Teams, Shopify, Intercom, Twilio, Google Analytics, Jira.
Based on user reviews and social mentions, the most common pain points are: token usage, token cost, $500 bill.
a16z AI
VC Firm at Andreessen Horowitz
3 mentions
Based on 118 social mentions analyzed, 14% of sentiment is positive, 83% neutral, and 3% negative.