We've compiled a list of the most common questions we get asked.
SlidesAI is highly rated with scores between 4.5 and 5 stars, highlighting its impressive language support and features like image recommendations and translation capabilities. Users appreciate its ability to rapidly generate presentations in multiple languages, which enhances user efficiency. While there are minor complaints about development pace due to it being managed by a solo developer, the sentiment towards pricing seems positive, implying that users perceive it as offering good value. Overall, SlidesAI has an excellent reputation for improving presentation creation speed and ease across diverse user groups.
Mentions (30d)
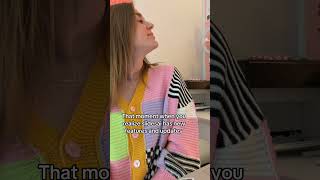
20
Avg Rating
4.6
4 reviews
Platforms
3
Sentiment
9%
10 positive

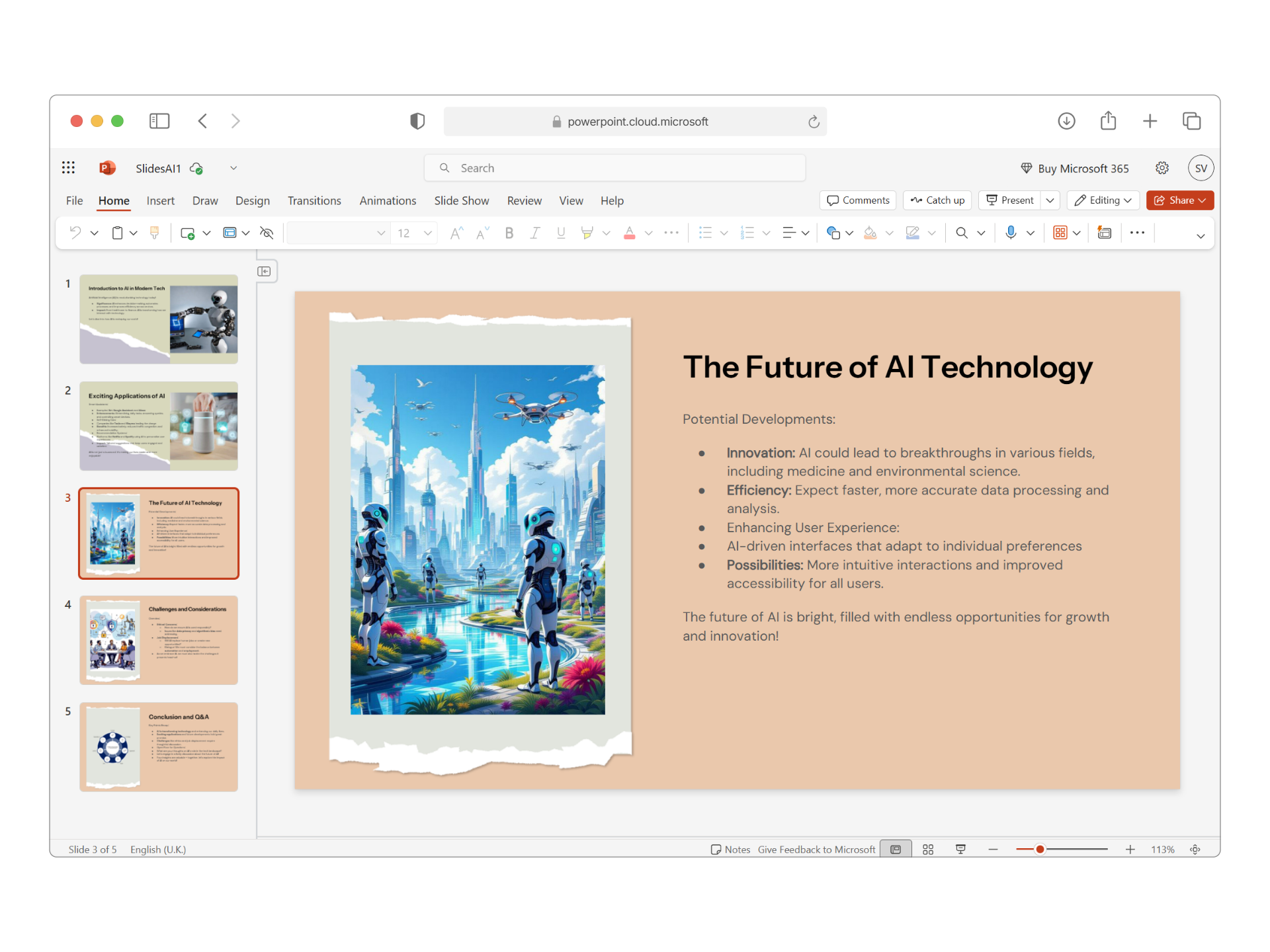

SlidesAI is highly rated with scores between 4.5 and 5 stars, highlighting its impressive language support and features like image recommendations and translation capabilities. Users appreciate its ability to rapidly generate presentations in multiple languages, which enhances user efficiency. While there are minor complaints about development pace due to it being managed by a solo developer, the sentiment towards pricing seems positive, implying that users perceive it as offering good value. Overall, SlidesAI has an excellent reputation for improving presentation creation speed and ease across diverse user groups.
Features
Use Cases
Industry
information technology & services
Employees
9
1,000
Twitter followers
Pricing found: $0 /month, $8.33 /month, $100 /year, $16.67 /month, $200 /year
g2
What do you like best about SlidesAI?I really like how it understands the context of my presentation. It even asks for a few details, such as the type of presentation and the number of slides, which makes the results more accurate. The best part is that it can generate presentations in multiple languages based on your preference. Plus, it works with ChatGPT, PowerPoint, and Google Slides. When I’m in a hurry, I find it especially useful—I can simply provide text, and it creates a full presentation along with a detailed outline. If I want to make changes, it allows easy editing, and if I’m not satisfied with the outline, it can regenerate a new one instantly. Review collected by and hosted on G2.com.What do you dislike about SlidesAI?Sometimes the generated slides need a bit of manual tweaking to perfectly match my style or formatting preferences. However, that’s a small step compared to the time it saves overall. Review collected by and hosted on G2.com.
What do you like best about SlidesAI?incredibly simple process and fast output with multiple theme and template options Review collected by and hosted on G2.com.What do you dislike about SlidesAI?Sometimes the AI-generated slides need a bit of manual tweaking or resizing to fit according to design Review collected by and hosted on G2.com.
What do you like best about SlidesAI?It can automate that saves a lot of time , it can generate slides and suggest designs. It suggest content based on keywords or topics that I love about it. One more great thing about it is that it supports multiple languages. Review collected by and hosted on G2.com.What do you dislike about SlidesAI?It looks a bit generic or uninspiring slides, there's a concern about privacy and security of sensitive data that we put on this.Pricing and subscription model is a bit concerning for me. Review collected by and hosted on G2.com.
What do you like best about SlidesAI?I love how easy it is to integrate while working out of Google Slides. Sometimes with the amount of content I need to utilize I struggle to lay it out and design. Review collected by and hosted on G2.com.What do you dislike about SlidesAI?It's not as intuitive as you'd hope it to be. I'm sure there's a way to finesse the tool however, I'm still in the learning process of how to do so. Review collected by and hosted on G2.com.
Find the best open-source OCR models in one place at Papers with Code [P]
Hi, I've created an overview of the most important OCR benchmarks, along with the top open models, and links to their paper and code: https://paperswithcode.co/tasks/ocr. This week, new OCR models were released by Baidu and Mistral. Baidu released Unlimited OCR, a 3B-parameter model that introduces a key innovation called Reference Sliding Window Attention (R-SWA) and builds on top of DeepSeek OCR. Mistral released OCR 4, which is available via an API. OCR, or Optical-Character Recognition, is the task of digitizing PDFs or scanned documents. There's, of course, a huge interest in this task, as it enables ingestion of all company data for agentic use cases. AI agents love Markdown; it can be valuable to turn all those messy PDF documents into a standardized, machine-readable format. This enables use cases like agentic RAG (retrieval-augmented generation), which powers chatbots, both internally and for external customer support. With a large number of OCR releases on Hugging Face over the last few months, it may be hard to know which one to use. Hence, I've built this page, which lists the major OCR benchmarks, along with the top-performing models and links to their code. This is obviously made available on Papers with Code, the website I'm maintaining (it's a revival of the old website, which was taken down). The top recommended benchmarks are OlmOCRBench, created by Ai2, and OmniDocBench, created by Shanghai AI Laboratory. Current top recommendations are Chandra OCR 2 by Datalab and Mistral OCR v4. The former is openly available, hence you can either self-host it or use their serverless API. Let me know which other tasks you want to see major benchmarks for now! Cheers, Niels open-source @ HF submitted by /u/NielsRogge [link] [comments]
View originalI stopped babysitting my AI: I gave my Claude Cowork project a brain and it started running the work. Open-sourced it.
Full disclosure: I'm a founder and I built this, so flag me if this isn't the place. I never had a "the model isn't smart enough" issue but rather that tt was that I had to stand over it. It would finish a task, stop, and wait for me to point at the next one. Market analysis, then brand, then pricing, then UI drafts. Every step, I was the bottleneck. I didn't need an assistant to manage. I needed something that knew the plan and kept going. I also looked at the fully autonomous agents going around, and honestly I didn't trust handing over actions I couldn't see or verify. I wanted to stay in the loop. So instead of telling it how to work, I asked it how it wanted to work, and let it build its own structure of markdown files (context, decisions, marketing, and so on). I started calling it the brain. Every important task ends with a short "Memory Update" that writes back what changed: decisions, open questions, assumptions. The next session reads them. Once it had that persistent context, it stopped waiting. It set up and now runs my Google Ads end to end (I hate that UI and know little about ads), tracks SEO health on my site, writes my daily and weekly briefs, watches trends, handles the inbox. The first real deals came in from it (B2B is slow, some are still closing, but they are real). When a company asked me for a four-day training on three days notice, around 180 slides, it built the whole thing from a single prompt without losing the thread, and pulled in know-how of mine I'd half-forgotten. The ugly truth: the brain is just markdown files I can open and correct. No black box, nothing acting behind my back. I removed the private stuff and included a sanitized real workspace so you can see what "good" looks like. MIT. Repo: https://github.com/yempik-ai/cowork-os (MIT). Built for Claude Cowork. If you try it, tell me what felt clunky, I'm iterating. Genuinely curious how others here run multi-step work across Cowork sessions, and where this breaks down at scale. submitted by /u/sim0of [link] [comments]
View originalHi Reddit, I posted my Build Your Own LLM workshop to Youtube teaching ML, LLM and math intuition [P]
Hi internet friends, I recorded a workshop about building your own LLM without any math / ML prerequisites. It covers everything from machine learning fundamentals, deep neural networks, transformer architecture, and pre/post-training. The only prerequisite is being comfortable with learning through code & excel examples. Sampling Large Language Models Reverse Engineering Large Language Model Perceptrons: wx+b Activation Functions: ReLU, GELU, SwiGLU GPU Coding: PyTorch, torch.compile(), fused kernels, CUDA, Triton MLPs/FFNs: Multi-input, Multi-Layer Perceptrons, Feed-Forward Networks Loss Functions: Residual errors, RMSE, Cross Entropy, Loss Landscapes Backpropagation: Training loops, Optimizers, Learning Rate, Batch Size Saving & Loading Models Initialization: Kaiming, Glorot Residuals: Addition, Scaling, Gated, Concatenation Normalization: Pre-norm vs. Post-norm, RMSNorm, BatchNorm, LayerNorm Regularization: Dropout, Gradient Clipping, Weight Decay SoftMax Tokenizers: By Character, By Word, BPE, SentencePiece Embeddings: Absolute vs. Learned, Sinusoidal vs. RoPE Attention: MHA, GQA, MQA, MLA Transformers Pre-training: Data Sources, Datasets, HTML Cleaning, Quality Filtering, Sharding Evaluation: Leaderboards, Benchmarks, Verifiers vs LLM-as-Judge Instruction Tuning: Alpaca & Other Formats, Self Instruct, Capabilities Reinforcement Learning: Policy Optimization, SimPO What We Didn't Cover: Scaling Each section has slides teaching the concepts, followed by excel-by-hand developing intuition for the math, and then coding examples. The goal is able to grok all parts of modern LLM development. We did this workshop in-person in San Francisco last month and hopefully the spaciousness of watching online works for everyone. If don't like watching videos, you can get the slides and exercises and work self-paced. submitted by /u/JustinAngel [link] [comments]
View originalClaude design skills?
Does anyone know if there's a way to get custom skills (or anything of the same nature) installed in claude.ai/design? I want to be able to have it create slide decks while following a very specific standard (something we could use to generate written education content to slide decks 100+ times). I don't know the best way to do that since it looks like custom skills can't be installed. submitted by /u/andwerd404 [link] [comments]
View originalboard prep used to eat a full saturday for me, the gathering more than the writing
counted it once last quarter: roughly 3 hours just pulling inputs before i opened a single slide. Last month's metrics out of notion, the roadmap state from linear, founder check-in notes sitting in granola, the open investor threads in gmail. None of it is hard work, it's just scattered across five tabs and i'm the courier carrying it between them. The actual writing was never my bottleneck. a chat assistant drafts the narrative fine once everything is pasted in, but i'm still the one doing the gather step by hand first. what changed it for me was letting a desktop agent do the cross-app read in one pass, notion plus linear plus granola plus gmail, and hand back an assembled draft before i touch slides. The deck quality wasn't the surprise. Not spending the morning as a copy-paste machine was. The gathering is the tax nobody budgets for, and honestly it's the part i least want a human doing. written with ai submitted by /u/Deep_Ad1959 [link] [comments]
View originalMaking slides
I know university professors are strict about AI and use AI detector when it’s essay writing, but what about powerpoint slides? Are there any ways for them to detect AI-made slides? What about videos? submitted by /u/HideOB [link] [comments]
View originalAdvice on building a Figma → PowerPoint plugin (non-coder using AI)
I'm not a coder, but I've been loving using AI to build scripts and plugins for the programs I use. It's opened up a space my lack of coding knowledge kept me out of before. For the last few months I've been trying to build a Figma plugin that converts Figma frames into PowerPoint master slides at the highest fidelity possible. I've tried many iterations, including exporting to XML. The core problem: Figma and PowerPoint don't share the same measurement units, and I can't seem to get a true one-to-one conversion. No matter how I prompt the AI, it can't reconcile the difference — so font sizes, text spacing, alignment, placeholders, headers, and footers never translate the way I want. A solid Figma → PowerPoint pipeline would be huge for my work. I love designing in Figma and it does things PowerPoint never could, but Figma Slides isn't an industry standard yet — PowerPoint still is. My ideal plugin would recognize and convert, at high fidelity: headers, footers, content boxes, placeholders, layout guides, font colors, spacing, line/stroke widths, and gradients — so I'm not rebuilding everything by hand. I know it's possible — there are paid Figma plugins that do this. I just don't know coding well enough to know what I'm missing in my prompts. Has anyone built something similar or had success here? Any advice on prompting or a different approach would be appreciated. Thanks! 🙏 Extra information - I have a pro subscription. I have tried using Fable to build the plug-in and I got the same outcome as before. I keep ending up with a poor translation that is so off that I would have to do as much work correcting them than I did building them in figma in the first place. submitted by /u/Brief_Intention_7599 [link] [comments]
View originalI built a free editor for HTML slide decks from Claude — edit them like PowerPoint, right in your browser, no sign-up, data stays in your browser
Lately a lot of my presentations come out of Claude/ChatGPT as a single HTML file. They look great and open anywhere, but the moment you need to fix a typo or move a box before a meeting, you're stuck re-prompting the AI or digging through dev tools. So I built Greenroom: drop in an HTML deck, click any text to edit it, drag and resize elements (with snapping guides), edit chart data, reorder slides, change the deck's colors, present fullscreen, export PDF. Hit save and you get back the same single HTML file, still working everywhere. No signup, no upload, the file never leaves your browser (check the network tab if you don't believe me). Try it: edit-html.com There's a built-in demo deck if you don't have one handy. It's early I'd genuinely love to know what breaks when you throw your own decks at it. submitted by /u/Parry11 [link] [comments]
View originalBlast Arena: a Bomberman-style browser game built entirely with Claude Code
🎮 Play (free, nothing to install): https://bomberman-coral.vercel.app What it is: an 8-level arcade game where each level introduces a new mechanic — classic crate-bombing, enemies that pathfind toward you, ice you slide on, electric floors, a minion-spawning boss, teleport portals, enemies that plant their own bombs, and conveyor belts. Between levels you spend gold in an upgrade shop with an unlock tree (max one line to open advanced ones). There's a public per-level leaderboard with clear times, full touch controls on mobile, and procedurally drawn graphics/synthesized audio — zero asset files. How Claude helped: honestly, it built all of it. I steered with plain-language prompts ("make it look premium", "levels should get harder", "make it work on mobile", "my scores disappeared — fix it") and Claude Code wrote the vanilla JS/canvas engine, the particle and audio systems, the enemy AI, and the Vercel serverless leaderboard. The interesting parts were the bugs: it diagnosed a leaderboard race condition (concurrent score submissions silently overwriting each other through a CDN-cached read-modify-write) and redesigned the storage so every score is its own write-conflict-free record. It also wrote its own headless test harness that simulates full playthroughs, since there was no test framework in a plain HTML project. Transparency / security notes: No account, no login, no personal data requested. You pick a nickname to play — that nickname and your level clear times are publicly visible on the leaderboard, so don't use your real name. Game progress (gold/upgrades) is stored only in your browser's localStorage. The site uses Vercel Web Analytics (anonymous, cookie-free page counts). Nicknames are profanity-filtered server-side. Everything runs client-side except the leaderboard API (a small Vercel function). No downloads, no permissions, no credentials touched. Feedback very welcome — especially on difficulty balance in levels 5–8, which were tuned by an AI that can't actually feel panic. 😄 submitted by /u/igoroliveiragg [link] [comments]
View originalTrolling AI for no reason
Is it just me, or does anyone else find they can't help themselves troll AI sometimes. Like I will use Claude for a long research project, write and refine a report, and once done I just love fucking with it. Like asking it to rewrite the report because I am going to send it over to a 4 year old to review, so if you could please put the whole thing in baby talk. Or ask it what I can put on the slides when I present it in order to guarantee that anyone who sees it will become incredibly attracted to me. Or ask it to find the closest tattoo shop near me because I am going to get this whole report tattooed on my ass and moon people on the street as a guerilla marketing experiment. Is my life so dull that I have to resort to fucking with a robot to feel feelings? submitted by /u/musicheadspace [link] [comments]
View originalCS lead at a series B SaaS. The Claude + Gamma workflow that finally made QBRs not painful.
CS lead at a 240 person series B SaaS. 7 person CS team. We run ~80 QBRs per quarter across our enterprise accounts. For 18 months QBRs were the worst week of every quarter. Each CSM spent ~8-12 hours per QBR. The deck was always rushed. The data was always stale. The customer narrative was always something the CSM remembered, not something we'd documented. Built a new workflow in q1 2026. Now ~3-4 hours per QBR with better output. Sharing because other CS leaders kept asking what we did. The qbr template we standardized: Customer headline (what they bought us for, in their words) Outcomes against the buying narrative (specific metrics) Usage patterns (where they're getting value, where they're not) Open issues + how we're closing them Next quarter's joint priorities The strategic question (what's changing in their business that affects our relationship) The Claude side of the workflow (the brain): Each enterprise account has a Claude project with their history, contracts, support tickets, product usage data 1 hour before each QBR prep session, the CSM asks Claude to draft each of the 6 sections The CSM edits (~90 min) and the draft becomes the source of truth The deck rendering (where Gamma comes in): The drafted QBR document goes into Gamma as the structured input Gamma generates a 12 slide deck from the document The CSM spends ~45 min cleaning up layout and adding specific account screenshots The ai presentation generator output then gets a final review with the CSM's manager before the customer call Why this workflow specifically: Claude is the brain (the thinking, the narrative, the customer-specific insight) Gamma is the rendering layer (the deck, the visual structure) The CSM is the editor (judgment, relationship knowledge, the actual customer call) What this changed: QBR prep time: 8-12 hours per QBR → 3-4 hours per QBR Customer NPS on QBR experience: went from "we tolerated them" feedback to "best vendor QBR we've ever had" from 3 customers (sample of ~30) Renewal rate at QBR-active accounts: 71% → 86% over 2 quarters (small sample, encouraging trend) What we still won't automate: The actual customer call (CSM only) The relationship work between QBRs (CSM only) Any pricing or commercial conversation (CSM + commercial lead) For other CS leaders running 50+ QBRs per quarter: what's your workflow and where's the bottleneck? submitted by /u/FlatGovernment6743 [link] [comments]
View originalNon-developer built a real web app with Claude; looking for people to try it.
I’m an architect, not a developer. Spent the last few months working with Claude (mostly Claude Code) to build a real production AI doc/slide-deck tool called Lineweight. Just went live. What it does: • One prompt → multi-page slide deck (styled, editable per-page). • Chat-edit any page — model emits structured edits, engine applies them. • Upload a CSV, Claude queries it with DuckDB tool calls and charts the data into pages. What Claude built: essentially all the code. The multi-step planner → designer architecture, the doc schema and apply-edits engine, auth, Stripe billing, usage metering, a full pre-launch security audit + multi-tenant refactor. I was product owner; set requirements, made decisions, reviewed diffs. A few things I learned. Claude dispatch is awesome! You can build from your phone, and it seems to somewhat change your exact prompt to actually help Claude be better. Sometimes it would start a new session, and I never know when to do that for best token usage. Sometimes it would add context or other things to the directions that it's actually giving Claude code that I wouldn't have known to do. I found that it was able to solve bugs and build code way better going through Dispatch than just me typing into code. I also confirmed what a lot of you have already seen: COD can be very lazy. Sometimes it would tell me that something was an issue without ever looking into my code or doing any tests, and I would have to push back on that. It also constantly suggested quicker fixes, saying that doing it right would be too long, so I recommend a quick fix. The quick fix would not actually fix it, or it would fix this specific item while not fixing the broader category. I definitely needed to prompt it to do it right, no matter how long it took. Free to try: https://lineweight.io If you do try it, I'd love feedback. submitted by /u/_Ubuntu_ [link] [comments]
View originaldynamic workflows changed how i build features. 3 subagents researching API docs, writing tests, and generating code simultaneously. feature velocity: 3x.
tutoring platform. $21.8K MRR. 108 tutors. tested dynamic workflows in claude code for feature development. the old workflow (sequential): research API docs → write code → write tests → review. each step waits for the previous one. the dynamic workflow (parallel): 3 subagents launched simultaneously: subagent 1: reads API documentation and generates integration spec. subagent 2: writes test cases based on the feature requirements. subagent 3: generates the implementation code. parent agent: synthesizes all 3 outputs, resolves conflicts, and produces the final feature. feature build time comparison: sequential: 4-6 hours per feature. dynamic workflow: 1.5-2 hours per feature. roughly 3x faster. the parallel execution eliminates the waiting between steps. the session summary prompts (70+ versions, refined over 16 months) now benefit from opus 4.8's improved reasoning. the visual progress tracking (ai presentation tool for parent-facing slide decks) quality improved because the underlying summary data improved. the caveat: dynamic workflows consume context window rapidly. complex features with large API docs can exceed the window. monitoring is essential. for devs building features with claude code: dynamic workflows are the biggest single productivity gain since MCP. the parallel subagent model changes feature development from sequential to concurrent. submitted by /u/Unique-Affect-6135 [link] [comments]
View original5H window
I want to send automated "Hi" messages to Claude Code every 30 min so the 5H window is always "in use". I only use it heavily twice a day (during my commute to and from work) and I always get blocked after 5-6 heavy prompts (or ~20 lighter ones). My goal is to have 2 separate 5H sliding windows available per commute. When I asked claude I get this answer: "But that's not how it works. The 5H window is purely a token consumption counter, not a session timer. Activity doesn't reset it — only time does (old tokens age out of the rolling window). There's also no way to script claude.ai — no API, no endpoint, nothing to hit programmatically." Any idea ? submitted by /u/Agreeable_Split1355 [link] [comments]
View originalHi Reddit, I posted my Build Your Own LLM workshop which encourages Claude use for coding exercises
Hi internet friends, I recorded a workshop about building your own LLM without any math / ML prerequisites. It covers everything from machine learning fundamentals, deep neural networks, transformer architecture, and pre/post-training. AI-coding assistants like Claude/CC are often referenced and encouraged for coding exercises. The only prerequisite is being comfortable with learning through code & excel examples. Sampling Large Language Models Reverse Engineering Large Language Model Perceptrons: wx+b Activation Functions: ReLU, GELU, SwiGLU GPU Coding: PyTorch, torch.compile(), fused kernels, CUDA, Triton MLPs/FFNs: Multi-input, Multi-Layer Perceptrons, Feed-Forward Networks Loss Functions: Residual errors, RMSE, Cross Entropy, Loss Landscapes Backpropagation: Training loops, Optimizers, Learning Rate, Batch Size Saving & Loading Models Initialization: Kaiming, Glorot Residuals: Addition, Scaling, Gated, Concatenation Normalization: Pre-norm vs. Post-norm, RMSNorm, BatchNorm, LayerNorm Regularization: Dropout, Gradient Clipping, Weight Decay SoftMax Tokenizers: By Character, By Word, BPE, SentencePiece Embeddings: Absolute vs. Learned, Sinusoidal vs. RoPE Attention: MHA, GQA, MQA, MLA Transformers Pre-training: Data Sources, Datasets, HTML Cleaning, Quality Filtering, Sharding Evaluation: Leaderboards, Benchmarks, Verifiers vs LLM-as-Judge Instruction Tuning: Alpaca & Other Formats, Self Instruct, Capabilities Reinforcement Learning: Policy Optimization, SimPO What We Didn't Cover: Scaling Each section has slides teaching the concepts, followed by excel-by-hand developing intuition for the math, and then coding examples. The goal is able to grok all parts of modern LLM development. We did this workshop in-person in San Francisco last month and hopefully the spaciousness of watching online works for everyone. If don't like watching videos, you can get the slides and exercises and work self-paced. submitted by /u/JustinAngel [link] [comments]
View originalYes, SlidesAI offers a free tier. Pricing found: $0 /month, $8.33 /month, $100 /year, $16.67 /month, $200 /year
SlidesAI has an average rating of 4.6 out of 5 stars based on 4 reviews from G2, Capterra, and TrustRadius.
Key features include: Click to watch Step by Step Tutorial, Install and Launch, Create and Customize Presentations with AI, Refine, Share, and Download, Supports 100+ languages, Edit Theme and Layouts, Refine, Rephrase, Shorten, Add Stunning Images Instantly.
SlidesAI is commonly used for: Creating professional presentations for business pitches, Generating lecture slides for educators, Developing thesis defense presentations for students, Designing marketing campaign presentations for brand managers, Creating training materials for corporate teams, Translating presentations for multilingual audiences.
SlidesAI integrates with: Google Slides, Microsoft PowerPoint, Google Workspace, Zapier, Slack, Trello, Asana, Notion.
Based on user reviews and social mentions, the most common pain points are: token usage.
Based on 111 social mentions analyzed, 9% of sentiment is positive, 90% neutral, and 1% negative.