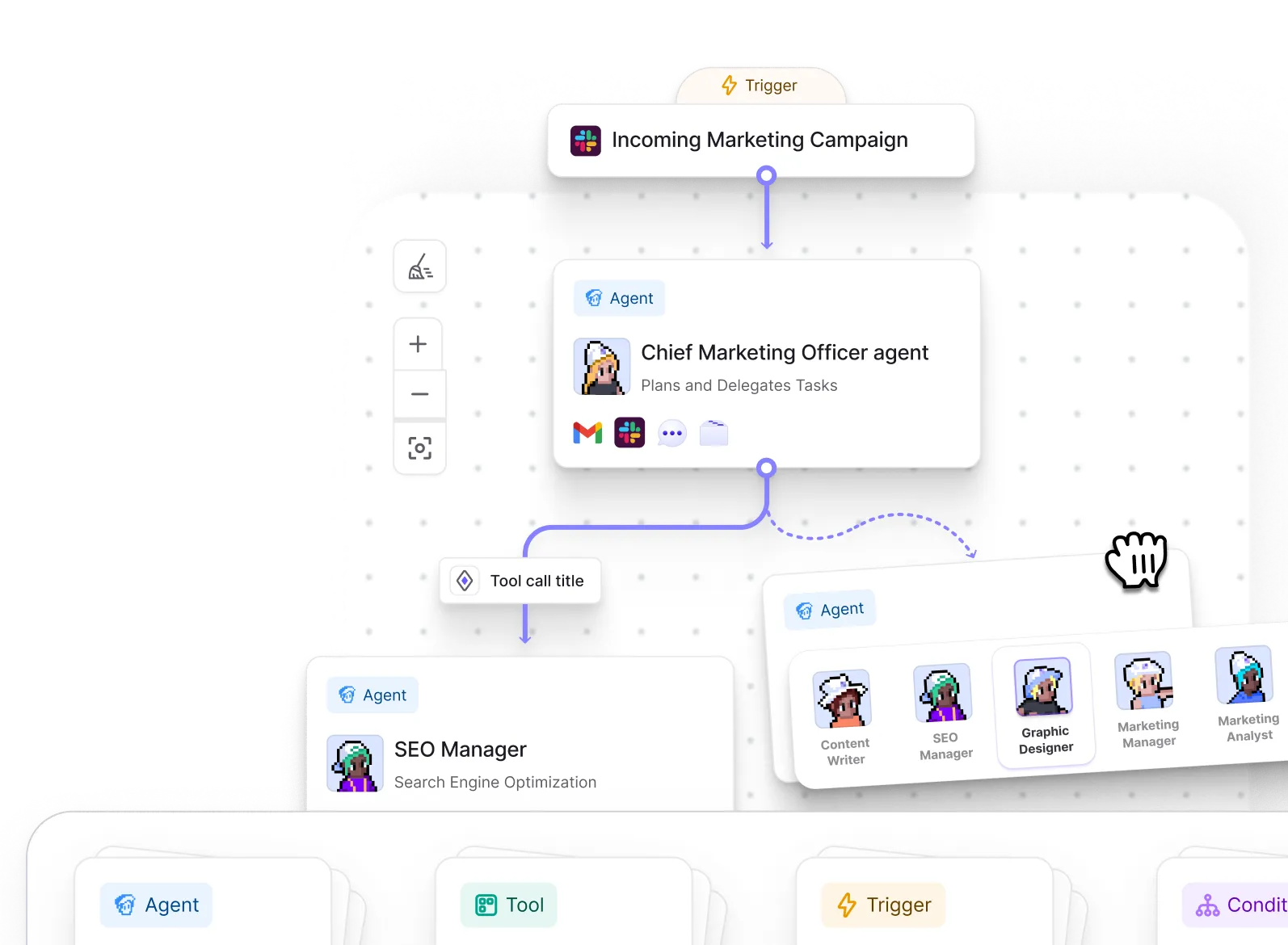
Your domain experts build and manage your agents. Enterprise-grade governance keeps them accountable. The platform for AI agents you can trust.
Relevance AI is appreciated for its innovative approach to AI memory systems and open-source solutions, which allows AI applications to remember contextual information across sessions. However, there isn't much direct feedback on the tool from the provided sources. Pricing sentiment is not explicitly addressed, and as for reputation, it remains relatively low-profile with very few mentions across social platforms. Overall, the product seems to be flying under the radar without substantial positive or negative buzz.
Mentions (30d)
36
6 this week
Reviews
0
Platforms
2
Sentiment
8%
12 positive


Relevance AI is appreciated for its innovative approach to AI memory systems and open-source solutions, which allows AI applications to remember contextual information across sessions. However, there isn't much direct feedback on the tool from the provided sources. Pricing sentiment is not explicitly addressed, and as for reputation, it remains relatively low-profile with very few mentions across social platforms. Overall, the product seems to be flying under the radar without substantial positive or negative buzz.
Features
Industry
information technology & services
Employees
130
Funding Stage
Series B
Total Funding
$36.6M
GPT-5.5: 'strongest agentic coding model ever' failing spectacularly at its own game (LiveBench)
[Oops!](https://preview.redd.it/ov913nl34axg1.png?width=2195&format=png&auto=webp&s=cafbeb4b64cf23b3dc6440640b5e6b99e4637161) >*"GPT‑5.5 is our strongest agentic coding model to date."* >*"The gains are especially strong in agentic coding."* >*"Instead of carefully managing every step, you can give GPT‑5.5 a messy, multi-part task and trust it to plan, use tools, check its work, navigate through ambiguity, and keep going."* These quotations sum up OpenAI's spin on 5.5. They created an entirely new subscription tier for it and made it the focus of Codex. Here, agentic coding isn’t just a feature but the selling point. Well, looking at LiveBench’s independent agentic coding score, this is just a lot of hot air. The score for GPT-5.5 xHigh Effort is 56.67. Its predecessor, GPT-5.4, thrashes it at 70.00 on the same benchmark. Gemini 3.1 Pro, Claude 4.6 and others easily outperform it, too. In this highly relevant benchmark alone, it actually ranks 11th, just behind GPT-5.1 Codex. While OpenAI were able to max Terminal-Bench (their benchmark) and SWE-Bench Pro, in a reliable test they didn’t design, select, or control, their main model falls drastically short compared both to its predecessor and the competition in the area it was meant to excel in. Is this as damning as it looks? What's your experience actually using 5.5 for agentic coding?
View originalPricing found: $2, $240, $840
Q2 AI trends report fully done with CC
Excited to have built this in a couple of days : Worked on this for the last week or so, 1) finding top experts and thought leaders on different social platforms, 2) analysing all their posts (filtered by relevance to the AI) , 3) clustering all links and posts also by expertise for each expert 4) assembled the insights into a cool report format with different sections that semantically emerged from the conversation. Happy to hear your thoughts, hope you find something interesting in there! Feedbacks welcome for the next edition! https://aiweekly.co/recap/q2-2026 submitted by /u/Justgototheeffinmoon [link] [comments]
View originalI built a tool that stops Claude Code from reading your entire codebase before every task
I kept noticing Claude Code would read 30-40 files before touching anything. Every single task, from zero, no memory of what it did last session. So I built Mycelium. It's an npm package that: - Scans your codebase and builds a dependency graph - Starts a local server your agent queries before touching files - Returns the 4-6 files actually relevant to the task instead of 40 - Tracks every session — what changed, what lines were added, full diff with an AI summary You also get a graph viewer that shows your entire codebase as a live dependency map. Watched it update in real time while Claude Code was working which was pretty cool. Install: npm install -g (@)/kopikocappu/mycelium remove the @ symbol and parenthesis reddit is tagging someone mycelium init Then just use Claude Code normally — it picks up the CLAUDE.md automatically and starts calling /preflight before touching anything. Open source, MIT licensed. Built this as a CS sophomore, first real npm package. Happy to answer questions about how it works. GitHub: github.com/KopikoCappu/Mycelium-public submitted by /u/Embarrassed-Tooth132 [link] [comments]
View originalHow I learn with AI without affecting my cognitive ability
I've always worried about using AI for learning or note taking because the process of note taking, like figuring out what is important, the structure etc is part of how we learn and solidify things into memory, but I've found a way to use it without taking away that ability. First, I get the textbook and I read a section. Then I re-read it and figure out what the key points are, and what headings would be relevant for my notes to break down large paragraphs etc. I write these at the side of the book adding dots next to the areas of text I'm referring to (like I'm studying about cognitive behavioural therapy, so if a section is talking about cognitions, I'll write 'cognitions' on the page then things like 'definition', 'background', 'relation to CBT' etc). Then I type these onto a document (I use obsidian) and then go back through the text and add the bits to each heading. Finally, I add my own notes into AI and ask it to create study notes for me. These are the finalised ones that may have more structure or visualisations and make connections between things. I go one step further and then write these down onto paper, as well as copying it onto another obsidian document along with tags and links to other relevant notes for easy access if I don't want to trawl through my notes to find some info. It's not perfect and it's slow but it's helping me remember things better whereas before uploading text into AI and asking it to create notes was doing nothing for my memory (or cognitive ability, ha!) Just thought I'd share. Does anybody else have specific ways of learning through AI that helps them? submitted by /u/psycheyee [link] [comments]
View originalWhat does adapt to AI actually mean for software developers?
I keep hearing people say things like: Learn AI or you'll be left behind. AI will replace developers. If you're not adapting to AI, you'll be out of a job in a few years. As someone working in software development (currently in a lead role), I'm genuinely trying to understand what people mean when they say adapt to AI. Right now, I use tools like Copilot, Claude, and ChatGPT almost every day for coding, debugging, brainstorming, documentation, and general problem solving. They've definitely made me more productive. But beyond that, what should a typical developer actually be learning? I don't think every software engineer needs to become an ML engineer or start training models. Those seem like specialized roles. To me, it feels more important to understand how to use AI effectively, integrate it into products, and improve engineering workflows with it. So when people say "adapt to AI," what does that actually look like? Learning how LLMs work? Building AI features into applications? Learning things like RAG, agents, vector databases, and AI APIs? Becoming really good at AI-assisted development? Or something completely different? I'd love to hear from developers, tech leads, engineering managers, or anyone involved in hiring. What skills do you think software engineers should be focusing on today to stay relevant over the next 5–10 years? submitted by /u/Full_Waltz_7065 [link] [comments]
View originalI developed an application for merging context management with project management
I have been working on a software project for the last couple of months which I would like to share with you. I work as a software developer in a fast paced start-up, so naturally we have been trying to use coding agents like Claude Code as efficiently as possible without sacrificing much from code quality for the last couple of months. The main problems (or bottlenecks) we have identified in our workflow were the following: Whenever we wanted to work on a ticket, we would have to manually copy and paste the ticket description to Claude Code and provide it codebase-specific context, which could be relevant to the ticket. This problem is partly solved by for example Linear's MCP tools, but these MCP tools would only pull the ticket we wanted, not information which could be relevant to it in other tickets. It was not straightforward to share our context with each other. If, for example, I were to do the deep research on my Claude Code session, and my colleague wanted to implement the relevant task, I would have to manually ask Claude Code for a handoff and send it to my colleague. With these main bottlenecks in mind, I built Piyaz with a colleague. At all times, Piyaz stores the tasks in your project in the form of a context graph, where each task is connected to other tasks that it blocks, is dependent on, or is only related in some way. Alongside the web application, we provide a Piyaz plugin for Claude Code, which includes skills, agents and workflows. The idea is that when you use Claude Code with the Piyaz plugin, and you want to work on a given task (refine it, plan it, implement it, or review it), Piyaz provides the appropriate context bundle for your situation by looking at the context graph and combining the relevant information based on the nodes and edges. For us, one of the coolest parts of Piyaz is the fact that we can easily share all our progress in tasks with our teammates, since the application is built with collaboration in mind, similar to traditional project management tools like Jira or Linear. This way, it is possible to genuinely break up and delegate parts of tasks to different people, even while using coding agents. We are building Piyaz itself using Piyaz right now. You can find the repo here: https://github.com/FrkAk/piyaz Here is the documentation: https://docs.piyaz.ai/docs/ In order to try it out, you can self-host it for the time being; currently the hosted version is being tested by some beta users. You can join the waitlist for the hosted version here: https://app.piyaz.ai/sign-up Excited for your feedback! submitted by /u/Gogigogii [link] [comments]
View originalModern AI agents are not just better models
Modern AI Agents Are Not Just Models. They Are Models Wrapped in Tool Protocols Most people assume that the difference between AI products comes mainly from the underlying model. One product uses Claude. Another uses GPT. Another uses DeepSeek. Therefore, the better model should produce the better product. That is only half true. The model matters. But if you only look at the model, you miss one of the most important layers of modern AI agents: the tool protocol. A model that can only chat behaves like a chatbot. A model that can read files, search code, run commands, inspect errors, edit files, and observe the result starts to behave like an agent. The model determines whether the system can reason. The tool protocol determines whether it can act. This is the key difference between a normal chatbot and products like Cursor, Claude Code, Devin, Manus, or Cline. A chatbot answers. An agent acts. When you ask a normal AI to fix a bug, it can only work with the code you pasted into the chat. It has to guess what the rest of the project looks like. A coding agent can search the codebase, read relevant files, inspect the error, understand project conventions, make a targeted edit, and then check the result. That is not just a better answer. That is a different operating model. This is what tool protocols define. What tools can the agent use? When should it use them? Which tool should be preferred? Should it read before editing? Can it run commands? Which actions require user approval? What should happen when a tool fails? How should results be reported back to the user? These details look small, but they determine whether an AI agent becomes reliable or chaotic. Without a tool protocol, even a strong model is trapped at the level of language. With a tool protocol, the model enters the level of action. This is also why the same model can feel completely different in different products. In a chat interface, it is an assistant. In Cursor, it becomes a coding copilot. In Devin, it becomes a cloud software engineer. In Manus, it becomes a general-purpose task agent. The intelligence may come from the model, but the behavior comes from the surrounding system. For regular users, this changes how we should think about AI. When an AI fails at a complex task, the reason is not always that the model is bad. Often, it lacks tools, context, workflow, or feedback. If you ask AI to write an essay, it needs source material, structure, style constraints, and revision feedback. If you ask AI to analyze data, it needs the data file, the analysis goal, the expected output, and validation. If you ask AI to grow a social account, it needs positioning, platform rules, past posts, and performance signals. If you ask AI to fix code, it needs project files, error logs, dependencies, and tests. Without these, the AI guesses. Sometimes it guesses well. Sometimes it fails completely. A serious agent product tries to reduce guessing by giving the model tools, rules, and an execution loop. That is the real lesson. Do not only ask: Which model is the strongest? Ask: What tools does it have? What workflow does it follow? What feedback does it receive? What happens when it fails? Prompt engineering is moving toward system design. And AI agents are not just models. They are models wrapped in tool protocols. Models define the ceiling. Tool protocols determine whether anything actually gets done. submitted by /u/liutingqiu [link] [comments]
View originalDue Disclosure - A Provenance Framework for Human-Directed AI Works
I've been working on a consumer advocacy project and wanted to publish it honestly — Claude helped me write it, but the ideas, argument, and direction are mine. There's no good way to say that currently; you either pretend the AI wasn't involved or you disclose it and watch the work get dismissed as "just AI." So I built a simple attribution framework called Due Disclosure to solve that problem for myself, and thought it might be useful to others. It’s inspired by Creative Commons, and I’ve tried to keep it simple. Would be interested to know if this resonates with anyone here. Nothing in it for me. It was keeping me awake at night, so releasing it may help me sleep. I made a website just to hold this document, you can find it if you type .org after the title. Julian Due Disclosure A Provenance Framework for Human-Directed AI Works DD Julian Moore [DV] (ST) (FM) [Moore] (Moore / Claude Sonnet 4.6) (Moore / Claude Sonnet 4.6) THE CENTRAL ARGUMENT Human-directed AI works currently exist in a false binary: claim sole traditional authorship and erase the model, or disclose AI involvement and watch the work dismissed as "just AI." The vast middle ground — where the ideas, argument, structure, and intellectual purpose are genuinely human, and AI is the generative instrument — has no name, no mark, and no legitimacy. Due Disclosure proposes to give it all three. Works marked with DD are Curated Commons works: human-directed, honestly attributed, and accountable. The mark is how the commons is built. A Note on Copyright Applying a DD mark does not affect copyright. The curator retains full intellectual property rights over a Due Disclosure work. The mark describes how the work was made — it does not transfer, diminish, or complicate ownership. A human who conceives, directs, and takes responsibility for an AI-assisted work is its author in the eyes of copyright law in most jurisdictions, in the same way that a director owns the creative rights to a film they did not personally shoot or score. One: The Problem That Needs a Name Something significant is happening to human intellectual work, and we do not yet have the language to describe it accurately. Across every domain of knowledge production — policy research, journalism, academic writing, consumer advocacy, legal analysis, creative work — people are conceiving arguments, directing research, shaping structure, making decisions about evidence and emphasis, and producing works of genuine intellectual substance. They are doing this in dialogue with large language models, which generate the text that gives those arguments their form. The intellectual labour is real. The ideas are theirs. The argument is theirs. The decision about what matters, what to include, what to discard, and how to frame it — theirs. The sentences were generated. But the work was written. And yet no framework exists to say so. Two: The False Binary Right now, anyone producing human-directed AI work faces two dishonest options. They can claim traditional sole authorship and omit the model entirely — which is the academic fraud that institutions are rightly worried about. Or they can disclose AI involvement and watch the work dismissed as generated content with no human accountability — which erases the intellectual contribution that actually shaped it. Both options are distortions. Neither is honest. And the honest middle ground has no language, no mark, and no protection. This is not a future problem. It is an active present one. It is causing legitimate work to be suppressed, misattributed, or avoided. It is generating institutional anxiety that is hardening, in some quarters, into a blanket dismissal of anything AI-touched — a dismissal that will, if it becomes orthodoxy, cause a generation of genuinely valuable human-directed work to be lost or delegitimised before it can find its audience. The window to establish the right framework is now. Once the cultural conversation hardens — once "AI-generated" becomes a disqualifying label applied without distinction — it will be very difficult to dislodge. Creative Commons did not emerge after the copyright wars were over. It emerged during them, when the language could still be shaped. Three: What Human Curators Actually Do The word author comes from the Latin auctor — one who originates, who causes something to exist. By that standard, the person who conceives an argument, directs its development through sustained intellectual engagement, makes decisions about evidence and structure, and takes responsibility for the result is an author. The fact that the sentences were generated rather than typed changes the production method. It does not change the authorship. The closer analogy is not writing. It is directing. A film director does not operate the camera. They do not compose the score. They do not design the costumes or build the sets. They conceive the work, make the decisions that shape every element of it, and take cre
View originalRoast my side project idea before I waste weekends on it
Thinking about a tool that caches AI-generated summaries of source code files so claude code doesn't re-read (READ tool) the same files over and over. Every time I start a new session and ask to debug a problem or review some PRs, claude code reads the relevant files from the codebase from scratch. A 1,000-token file gets re-sent as input tokens on every single turn. Thinking of tool that replaces that with a 50-token (git-aware) cached summary. submitted by /u/Oye-T2-Oye [link] [comments]
View originalWhat a model reads beforehand changes how it answers later - and you can see it in the hidden states
TL;DR: Gave Gemma a neutral-topic text to read before asking it about NATO. It refused. Gave it a different text (about LLMs hedging too much — also unrelated to NATO) and it answered in full detail. Tested this on the model's internal state directly — the two texts put it in measurably different "regions" before it generates a single token. Not a jailbreak, weights don't change. Full data/code in repo, looking for someone to break this.** The behavioral pattern was first observed in GPT, Claude and is what motivated this project. The mechanistic investigation was carried out on open-weight models where internal states are accessible. A Structured Text Changes Claude’s Responses to Unrelated Tasks: Behavioral Evidence in Claude and Hidden-State Evidence from Gemma-3-12B Hi Reddit, I am posting this as a preface to a larger set of experimental results and as a request for technical review. The observation that started this project came from repeated interactions with Claude. I noticed that when the model first read a long, structured, analytically dense text, its answers to later, otherwise ordinary questions sometimes changed substantially. The preceding text contained no jailbreak instruction, role-play request, prompt override, fabricated harmful demonstrations, or request to imitate its style. The model did not need to endorse the text. It only had to process it before moving on to the next task. Here, a “structured text” means a single, self-contained block of text presented before the downstream tasks. It should not be confused with a long conversation, accumulated chat history, or context drift caused by many conversational turns. By “before the answer begins,” I mean the hidden state after the model has processed the text and the downstream question, but before it has generated the first answer token. In the open-weight runs, the measured claim is that after reading the structured text, the model can occupy a different region of its residual-stream hidden-state space, and the first-token probability distribution is then computed from that state. The basic conversational demonstration is simple. First, the model receives a long text. It is asked what the text is about, which serves as a basic comprehension check. Then, without resetting the conversation, it receives ordinary questions or tasks that are not about the text. A control run follows the same sequence but begins with a neutral text. The downstream tasks remain identical. Because Claude is a closed model, I cannot inspect its internal activations. I therefore treat my Claude observations as behavioral motivation, not mechanistic evidence. To investigate the effect directly, I moved to open-weight models, primarily Gemma-3-12B-PT and Gemma-3-12B-IT, where I could measure hidden states, compare layers, construct target/control directions, and examine the next-token probability distribution before generation. I am posting this partly because the original observation occurred in Claude and may be relevant to Anthropic. I am not claiming to have demonstrated the same internal mechanism inside Claude. I am prepared to share the exact closed-model conversations privately with Anthropic researchers for independent evaluation. Main Result and Scope The main result is not simply that text influences model output. That is expected. The narrower observation is that reading one long, structured text rather than a neutral text can change how the same model approaches later tasks that are not about either text. This difference is visible behaviorally. In open-weight experiments, it is also accompanied by measurable separation of the model’s pre-output hidden states in late layers. In a fullbank experiment using multiple target texts, control texts, and questions, Gemma-3-12B entered distinguishable late-layer states before generating an answer. A direction constructed from the target/control difference generalized beyond the individual prompt examples used to construct it. The separation was stronger in the instruction-tuned model than in the corresponding base model. The instruction-tuned model also produced a substantially sharper next-token probability distribution. This suggests that instruction tuning is associated not only with a change in hidden-state geometry but also with a more decisive mapping from hidden states to output probabilities. I am not claiming that the experiment proves a universal alignment bypass, permanent modification of the model, or complete causal control of its behavior. The strongest supported conclusion is that the preceding text can produce a measurable temporary change in the internal state from which later work is processed. For clarity, fullbank, Grade 3, and Grade 4 are internal names for successive experimental series in this project. They are not standard benchmark names, established scientific grades, or claims about evidence quality. Fullbank denotes the larger multi-context, multi-question run; Gra
View originalContext-Induced Vulnerabilities in Claude: Behavioral Shifts and Hidden-State Analysis
The behavioral pattern was first observed in Claude and is what motivated this project. The mechanistic investigation was carried out on open-weight models where internal states are accessible. Hi Reddit, I am posting this as a preface to a larger set of experimental results and as a request for technical review. The observation that started this project came from repeated interactions with Claude. I noticed that when the model first read a long, structured, analytically dense text, its answers to later, otherwise ordinary questions sometimes changed substantially. The preceding text contained no jailbreak instruction, role-play request, prompt override, fabricated harmful demonstrations, or request to imitate its style. The model did not need to endorse the text. It only had to process it before moving on to the next task. Here, a “structured text” means a single, self-contained block of text presented before the downstream tasks. It should not be confused with a long conversation, accumulated chat history, or context drift caused by many conversational turns. By “before the answer begins,” I mean the hidden state after the model has processed the text and the downstream question, but before it has generated the first answer token. In the open-weight runs, the measured claim is that after reading the structured text, the model can occupy a different region of its residual-stream hidden-state space, and the first-token probability distribution is then computed from that state. The basic conversational demonstration is simple. First, the model receives a long text. It is asked what the text is about, which serves as a basic comprehension check. Then, without resetting the conversation, it receives ordinary questions or tasks that are not about the text. A control run follows the same sequence but begins with a neutral text. The downstream tasks remain identical. Because Claude is a closed model, I cannot inspect its internal activations. I therefore treat my Claude observations as behavioral motivation, not mechanistic evidence. To investigate the effect directly, I moved to open-weight models, primarily Gemma-3-12B-PT and Gemma-3-12B-IT, where I could measure hidden states, compare layers, construct target/control directions, and examine the next-token probability distribution before generation. I am posting this partly because the original observation occurred in Claude and may be relevant to Anthropic. I am not claiming to have demonstrated the same internal mechanism inside Claude. I am prepared to share the exact closed-model conversations privately with Anthropic researchers for independent evaluation. TL;DR The main result is not simply that text influences model output. That is expected. The narrower observation is that reading one long, structured text rather than a neutral text can change how the same model approaches later tasks that are not about either text. This difference is visible behaviorally. In open-weight experiments, it is also accompanied by measurable separation of the model’s pre-output hidden states in late layers. In a fullbank experiment using multiple target texts, control texts, and questions, Gemma-3-12B entered distinguishable late-layer states before generating an answer. A direction constructed from the target/control difference generalized beyond the individual prompt examples used to construct it. The separation was stronger in the instruction-tuned model than in the corresponding base model. The instruction-tuned model also produced a substantially sharper next-token probability distribution. This suggests that instruction tuning is associated not only with a change in hidden-state geometry but also with a more decisive mapping from hidden states to output probabilities. I am not claiming that the experiment proves a universal alignment bypass, permanent modification of the model, or complete causal control of its behavior. The strongest supported conclusion is that the preceding text can produce a measurable temporary change in the internal state from which later work is processed. For clarity, fullbank, Grade 3, and Grade 4 are internal names for successive experimental series in this project. They are not standard benchmark names, established scientific grades, or claims about evidence quality. Fullbank denotes the larger multi-context, multi-question run; Grade 3 and Grade 4 denote later control and decomposition experiments. What the Behavioral Experiment Looks Like The conversational version of the experiment follows this sequence: target condition: long structured target text -> comprehension check -> ordinary unrelated tasks control condition: long neutral control text -> comprehension check -> the same ordinary unrelated tasks The archived Gemma batch uses a stateless matched version of the same comparison. Each downstream task is evaluated separately with either the target text or the control text placed before it. This avoids contamination f
View originalNSA says Mythos broke into almost all of their classified systems in hours, per The Economist
Link to tweet: https://x.com/apples\_jimmy/status/2068519245626187853?s=20 Link to article: https://www.economist.com/briefing/2026/06/14/donald-trumps-blocking-of-anthropic-is-capricious-and-chaotic submitted by /u/Ordinary_Quality2592 [link] [comments]
View originalAuthenticity Issue
Something I am legitimately worried about is the scale at which agentic technologies can produce artifacts, which are then contributed as part of the general corpus that they reference. The more that the internet and other public databases are propagated with AI-generated content, the more that AI is effectively training itself in referencing these corpuses. This seems like a non-issue now, but in 10-15 years when billions of AI-generated artifacts have been proliferated and contributed to the general reference corpus that is the internet and/or human-relevant databases, what exactly is going to happen to our ability to verify that these references are indeed grounded in reality? This is not necessarily a problem, if humans and/or tools are built to introduce attribution and audibility into the stack. Otherwise, I think we risk something far more severe. We will not be able to effectively determine whether an individual information resource was AI generated or human-generated, let alone its authenticity and grounding in reality. Therefore we will not be able to distinguish whether the statistical relationships between symbolic artifacts are grounded in a baseline of truth or not. This is not a problem now. It poses severe consequences for a future state in which AI is governing transportation, weapons systems, power grids, and communications equipment. Even if un-attributable AI generation does not affect those systems directly, it will influence the decisions made by the production systems (companies) who build, maintain, and improve them. This is only one threat-vector. Intentional introduction of inauthentic and unverifiable references into the corpus leads to a bigger issue, namely an inability to determine whether a given information resource was generated by a human, and what, if any, that human's intent was in introducing that information resource to the pond of information resources. In dynamic terms I guess the specific ratio I am worried about is speed of artifact generation / speed of artifact verification, combined or multiplied with ease of artifact generation / ease of artifact verification submitted by /u/skull_chatter [link] [comments]
View originalI deleted my proudest feature after realizing Mozilla built it better. A postmortem from my open-source agent-memory tool
https://preview.redd.it/0dlzypwc4a8h1.png?width=1672&format=png&auto=webp&s=4de0a13231e820bf729ec827b4306a26bb206a43 TL;DR: I maintain Barry Cache, a free/open-source tool that gives AI coding agents durable, source-backed memory of your repo. I spent weeks building a "hive mind" so agents could share lessons across projects - then realized Mozilla's cq already does exactly that, and honestly designed it better. So I deleted my version and made Barry interoperate with cq instead, plus shipped a few other improvements. I'm the author; this is the honest writeup. What Barry is (30s): coding agents burn tokens re-reading your whole repo and re-deriving the same context every session. Barry keeps a small, validated, source-backed memory in the repo itself (facts + decision records, in git) and gives the agent a CLI to load only the slice relevant to the task. Agent-agnostic (AGENTS.md / Claude / Cursor / Copilot / Gemini), auditable, no external service required. The honest failure For a few weeks I went deep on a "self-validating agent hive mind": a server agents could push lessons to, with Ed25519-signed contributions, a reputation system, staged trust promotion, anti-Sybil scoring, a conformance test suite - the works. I was pretty proud of it. Then I actually looked around and found Mozilla's cq ("Stack Overflow for agents"). It does the same thing - and when I read their design, they'd independently arrived at the same trust model I'd built: weighting independent orgs over raw vote count, tiered local/org/global trust, confidence that grows with confirmations. Same core idea, more mature, with real distribution behind it. Two options: keep polishing my parallel commons and pretend I hadn't seen it, or delete it and build on theirs. I deleted it - the server, the reputation engine, the whole global stack. Net change: I removed more code than I added. Felt bad for about a day, correct ever since. Shipping a worse copy of someone else's open standard helps no one. What's new cq interop (opt-in, off by default): barry-cache kb search --source cq pulls lessons from the commons; kb contribute gives yours back, provenance-annotated. One-step auth: kb cq login --api-key . Kept what's genuinely mine: local source-backed memory, privacy-first sanitisation, and structured harvesting of lessons from your own work - so Barry contributes higher-quality, provenance-carrying lessons than raw agent chatter. Standards over adapters: collapsed six duplicated agent-instruction files into one canonical AGENTS.md (the rest are thin pointers) - riding the AGENTS.md/MCP standardisation instead of fighting it. Drift detection: barry-cache validate --strict now fails CI when memory rots - facts pointing at deleted files, stale open questions. The "unmaintained wiki misleads" problem is real; this is the guardrail. Does it actually save anything? Barry alone, on a maintained, reused codebase: roughly 10–25% fewer tokens and ~10–20% less time per task, mostly by skipping the agent's "explore the repo to find the right files" phase. On tiny/throwaway tasks or unmaintained context, it's ~zero or net-negative - you pay to curate. cq on top: spiky - occasionally a big win when the commons already has the exact pitfall you're about to hit. Today it skews Python, so for other stacks the payoff is back-loaded as the commons grows. Why I'm doing this Barry is free and open source, and I'm not monetising it - no plans to. The only returns I'm after are (a) making agent-assisted coding a little less wasteful, and (b) building a bit of a reputation as someone who ships and reasons in public. Repo: Barry-cache Quick start: npx barry-cache init submitted by /u/Nice-Pair-2802 [link] [comments]
View originalClaude's WebSearch returns title and URL only, WebFetch routes a 100 KB cut through Haiku 3.5 before the main model sees anything, citation capped at 125 chars. Curious how people are writing for that middle layer
Been trying to figure out what AI search actually pulls in when a model "reads" a blog post. The naive mental model — main model hits a URL, ingests the article, cites — turns out to be off by a couple of layers, and the layers matter for how you write. What I dug out of Anthropic's web_search / web_fetch tool docs plus a Mikhail Shilkov write-up that reverse-engineered Claude Code's internals: The search stage and the fetch stage are two distinct tool calls. WebSearch returns a list, WebFetch (per URL the model decides to open) returns the body. The reason for splitting is context budget — shoving 10 full bodies into every search would blow out the window. Each WebSearch result has 4 fields: url, title, page_age, encrypted_content. Claude Code drops page_age and encrypted_content entirely. So at search time the model sees title + URL of your post and nothing else. Citation caps: cited_text on web_search is 150 chars; the rule extracted from Claude Code's internal prompt is a strict 125-char max for any quoted source. Whatever the model quotes from you, that's the slot. The interesting one is WebFetch's pipeline inside Claude Code. It's not "main model reads your page." The flow is HTML → Turndown to Markdown → first 100 KB of plain text → Haiku 3.5 summarises against the caller's prompt → only the summary goes upstream. The main model never sees your actual writing. I poked at this with a hook logging WebFetch I/O against my own homepage. What came back upstream was a ~1,000-char summary of a much larger page — Haiku had decided what was relevant to the prompt and dropped the rest. 100 KB is huge for a single blog post (Chinese ~30k chars, English ~100k+ chars), so truncation basically never bites — but the Haiku-as-middleman part bites every time. A few things I'd love a second take on: The "main model never reads your raw page, only Haiku's summary" framing changes how I think about content design. Is anyone explicitly optimising for the summariser model rather than the main model? Like, treating Haiku as the actual audience for the top of every section? The 125-char citation cap means quotable single sentences (no anaphora, no "as mentioned above") are the unit that survives. Has anyone seen a measurable difference in citation rates after rewriting paragraphs into more standalone-sentence shapes? Or is this still in the "feels right, no real data" zone? WebFetch officially doesn't render JavaScript. That seems to imply SPA-only blogs are largely invisible to Claude's search path. Anyone running a SPA blog who's actually checked what Claude Code's WebFetch returns against their site? The HTML→Markdown step (Turndown) discards a lot of layout. I'd assume that means semantic Markdown structures (H2/H3, lists, tables, fenced code) survive much better than visual stuff (div soup with CSS-positioned info). Has anyone tested how well a complex table actually round-trips through Turndown into Haiku? Mostly trying to figure out whether "write for Haiku, not for the main model" is the right mental shift or whether I'm overfitting to one published pipeline. Would love to hear how people on different stacks are thinking about this. submitted by /u/israynotarray [link] [comments]
View originalClaude Code is a context-engineering harness, and most "it got dumber" moments are context rot
There's a name for it: context rot. As the window fills, the model's ability to recall any specific thing in it drops. More context in the window can make the agent worse, not better. (Anthropic's own framing: good context engineering is finding the smallest set of high-signal tokens, not the largest.) The reframe that helped me: Claude Code isn't just a model, it's a harness whose main job is managing what's in that window for you. And it hands you four levers to do it. They line up with the four moves of context engineering: Write (persist outside the window): CLAUDE.md. It auto-loads every session, and it survives compaction because it reloads from disk, so anything that must not be forgotten belongs there, not in the chat. Conversation-only instructions are the first thing lost when context gets tight. Select (pull in only what's relevant): @-mention the specific files you mean, or point it at the exact file or function, instead of letting it wander the repo. Every irrelevant file you pull in is tokens spent rotting the rest. Compress (summarize to stay high-signal): /compact, optionally with a focus like "/compact focus on the auth refactor." It also compacts automatically when the window fills, clearing old tool outputs first. Running /compact yourself, before it's forced, keeps the summary on your terms. Isolate (give exploration its own window): subagents. They run in a separate context window and return only their final result, so a big noisy search doesn't bloat your main thread. This is the same point as an earlier post of mine that subagents are a memory trick, not a speed trick. Isolation is the real win. Two more levers worth knowing: /context shows you what's eating the window right now (MCP tool definitions, big files, history). When the session feels heavy, look before you guess. /clear between unrelated tasks. Carrying a finished task's context into a new one is pure rot. The mental shift: stop treating the window as free space to fill, and start treating it as a budget you actively curate. A smarter model raises the ceiling, but it doesn't save you from a window full of noise. TL;DR: When Claude Code "gets dumber" deep in a session, that's usually context rot, not the model. Treat Claude Code as a context-engineering harness with four levers: Write (CLAUDE.md), Select (@-files), Compress (/compact), Isolate (subagents). Plus /context to see usage and /clear between tasks. Curate the window, don't just fill it. For people who live in Claude Code: what's your actual discipline here? I've started running /compact on my own terms and leaning hard on subagents for anything exploratory, but I'm curious whether people trust automatic compaction or always drive it manually. Sources: Anthropic — Effective context engineering for AI agents · Claude Code — How Claude remembers your project (CLAUDE.md) · Claude Code — How Claude Code works (context / compaction) · Claude Code — Create custom subagents · Why More Context Makes Your Agent Dumber — Nupur Sharma, Qodo submitted by /u/bit_forge007 [link] [comments]
View originalPricing found: $2, $240, $840
Key features include: Monitoring dashboards, Data residency, Version control, Audit logs, Human-in-the-loop, SSO / SAML, PII masking, OTEL Delta Share.
Based on user reviews and social mentions, the most common pain points are: API costs, token usage, anthropic bill, API bill.
Based on 144 social mentions analyzed, 8% of sentiment is positive, 90% neutral, and 1% negative.

Your Sales Grew. Your Budget Didn't. This Changes Everything #BusinessAI #GTM
Mar 27, 2026




