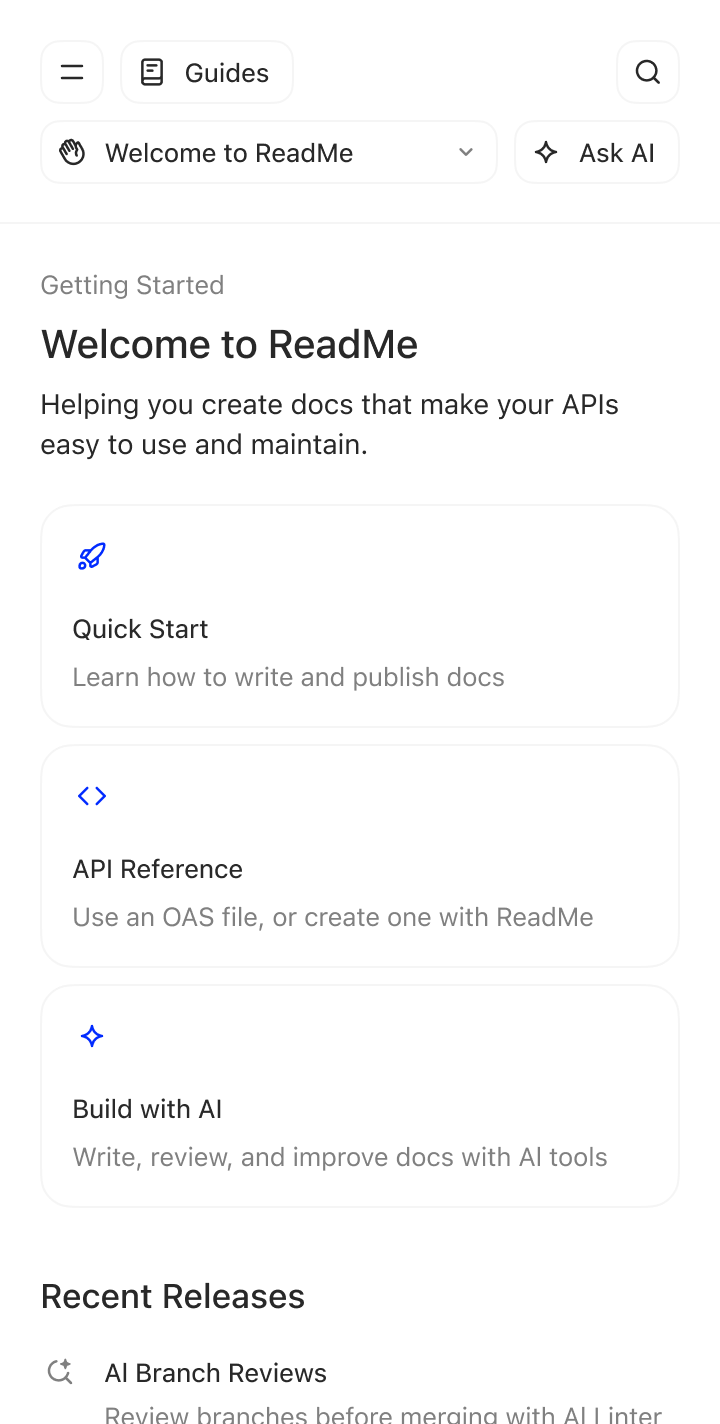
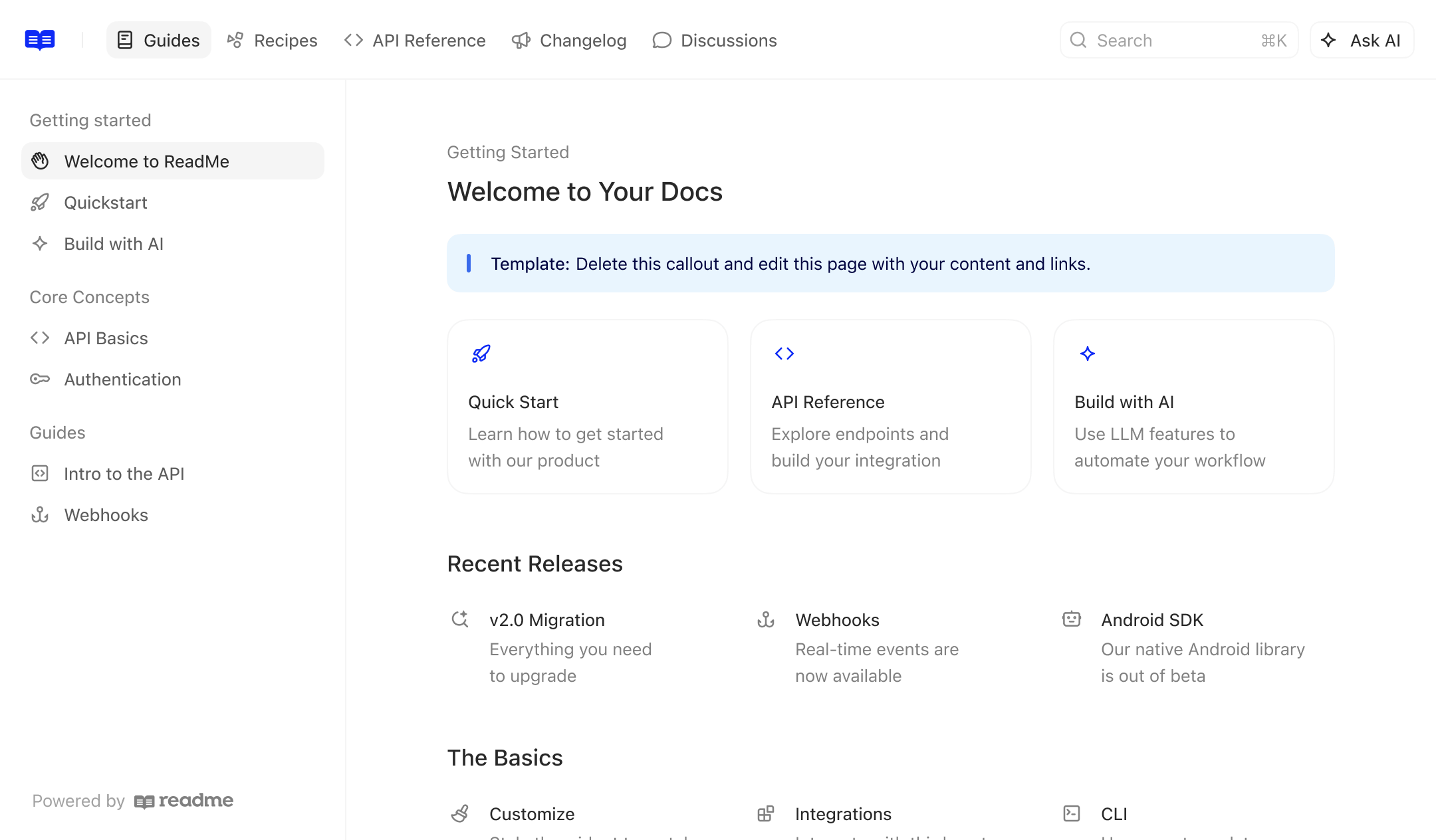
ReadMe helps you create beautiful, interactive API documentation that developers love.
ReadMe is highly regarded for its user-friendly interface and AI-enhanced documentation features, with users often praising its simplicity and effectiveness. However, some users have noted minor issues, leading to a few mid-range ratings. There's a generally positive sentiment about pricing with no specific complaints noted. Overall, ReadMe enjoys a strong reputation among developers and tech communities, frequently highlighted for its innovation and engagement with AI capabilities.
Mentions (30d)
42
3 this week
Avg Rating
4.4
20 reviews
Platforms
5
Sentiment
7%
13 positive
ReadMe is highly regarded for its user-friendly interface and AI-enhanced documentation features, with users often praising its simplicity and effectiveness. However, some users have noted minor issues, leading to a few mid-range ratings. There's a generally positive sentiment about pricing with no specific complaints noted. Overall, ReadMe enjoys a strong reputation among developers and tech communities, frequently highlighted for its innovation and engagement with AI capabilities.
Features
Use Cases
Industry
information technology & services
Employees
83
Funding Stage
Series A
Total Funding
$10.4M
2,500
Twitter followers
Show HN: Gemini can now natively embed video, so I built sub-second video search
Gemini Embedding 2 can project raw video directly into a 768-dimensional vector space alongside text. No transcription, no frame captioning, no intermediate text. A query like "green car cutting me off" is directly comparable to a 30-second video clip at the vector level.<p>I used this to build a CLI that indexes hours of footage into ChromaDB, then searches it with natural language and auto-trims the matching clip. Demo video on the GitHub README. Indexing costs ~$2.50/hr of footage. Still-frame detection skips idle chunks, so security camera / sentry mode footage is much cheaper.
View originalPricing found: $150/mo, $150/mo, $150 /month, $150 /month, $150 /month
g2
What do you like best about ReadMe?We’re building our own investment app, and one of the clearing firms we work with already used ReadMe for their docs, so we checked it out from that referral. It’s been an excellent fit. It’s quick to publish clean, modern docs, the OpenAPI sync and interactive API reference work really well, and it’s easy for both technical and nontechnical folks to contribute. The analytics are also genuinely helpful for seeing what people are reading and where we can make things even clearer. Review collected by and hosted on G2.com.What do you dislike about ReadMe?Nothing is perfect, some of the deeper customization and admin settings took us a minute to learn and could be a bit more intuitive, but the defaults are strong and support has been responsive, so it never slowed us down. Once you’re set up, day to day publishing and updates are effortless.. Review collected by and hosted on G2.com.
What do you like best about ReadMe?I like that it's fairly easy to get set up, and it's visually very clean. The branding is straightforward and sections like guides versus API reference are easy to understand. These aspects make ReadMe quite appealing to me. Review collected by and hosted on G2.com.What do you dislike about ReadMe?I would like to have a better way to manage API documentation for different products. Right now, I have to work around things by creating a different version and basically making two products have two versions, but that's not semantically correct. I'd prefer to have a cleaner way to allow switchability between multiple products. Also, there's an annoying thing where the finance team can't have a role just to manage things like payment methods for our monthly payments, so they keep contacting me. That's the only gripe I have. Review collected by and hosted on G2.com.
What do you like best about ReadMe?Super easy to use! Suggested Edits are cool. Building a professional landing page is a breeze. Powerful API insights. Review collected by and hosted on G2.com.What do you dislike about ReadMe?I think probably b/c it's built to be SO easy to use, it's a bit less flexible and grows feature-rich more slowly. Having said that, it's made strides recently! Review collected by and hosted on G2.com.
What do you like best about ReadMe?- Easy to get started - Theme Customizations Review collected by and hosted on G2.com.What do you dislike about ReadMe?- For a docs product it has a outrageously buggy editor. Yes I understand buidling WYSIWYG editor is hard but come on, all the menu UI elements keep erractically jumping around. Cannot indent or dendent things correctly - Terrible Keyword based search in 2024. 9/10 times search results are incorrectly ranked. - Does not support hosting arbitrary static HTML pages - E.g. generated from Python Sphinx or Mkdocs Review collected by and hosted on G2.com.
What do you like best about ReadMe?The support is wonderful and I really enjoy how easy it is to add team members. The mascot is really enjoyable and in general it gets the job done. Easy to implement. Review collected by and hosted on G2.com.What do you dislike about ReadMe?Lack of collaboration tools, no content resuse tools, hard to work with images and no options to put inline etc. They're constantly improving their API doc tools but really little focus on general user doc needs despite many recommendations over the years. Some features that are entreprise only -- seems really unfair they don't offer the ad hoc. Global search and pdf download options should not be exclusive to enterprise because the cost is so different. Review collected by and hosted on G2.com.
What do you like best about ReadMe?It's user interface and display is aesthetically nice and intuitive as it's easy to navigate through features. Review collected by and hosted on G2.com.What do you dislike about ReadMe?I think ReadMe has a lot of great features that are just gated for higher subscriptions -- too pricey. Review collected by and hosted on G2.com.
What do you like best about ReadMe?Start using day 1, very easy to implement.Also easy to customize to fit your needs and your goals. Review collected by and hosted on G2.com.What do you dislike about ReadMe?Built for small and medium sized companies. If you need additional segments, multiple sets of API documentaton it can get VERY EXPENSIVE. Also, product support is non existent for lower tiers. Not a bad thing, but something to think about when selecting your package. Review collected by and hosted on G2.com.
What do you like best about ReadMe?I, as Product Manager, can manage the documentation without using developers' time Review collected by and hosted on G2.com.What do you dislike about ReadMe?Not so intuitive to create the home page Review collected by and hosted on G2.com.
What do you like best about ReadMe?Love the sandbox environments we give users to test out our APIs right from our docs. They don't need to leave or go elsewhere, everything can happen right there in the documentation. Review collected by and hosted on G2.com.What do you dislike about ReadMe?I wish they offered an area to test out websockets. Right now the area to test out APIs is top notch. But we started offering websockets and that requires users to leave the docs to test them Review collected by and hosted on G2.com.
What do you like best about ReadMe?Readme.io provides a guided thought process on structuring your pages, giving you a simple way of building your API documentation with unlimited flexibility with the content editor. The Guides and Recipies are game changers for people consuming your documentation. Review collected by and hosted on G2.com.What do you dislike about ReadMe?I cant really think of anything that I dislike about Readme.com - especially compared to other platforms that we used before hand. Review collected by and hosted on G2.com.
Started maintaining a small library at work and now I genuinely understand why maintainers go quiet
Built a little internal utility about a year ago, open sourced it because why not, figured maybe 10 people would find it useful. It slowly picked up a few hundred stars and then the issues started coming in. Not a flood or anything but enough and what surprised me was how much of it wasn't really bugs it was people wanting features that made sense for their use case but would've made zero sense for the original scope of the thing. Or issues that were basically "your README didn't account for my specific setup." I like helping people, I thought I would enjoy this and I did at first but somewhere around month 4 I noticed I was dreading opening GitHub notifications. The AI-generated PRs made it worse honestly. Not because the code was always bad but because they'd come in with confident descriptions, look reasonable on the surface and then you'd spend 30 minutes tracing through edge cases only to realize whoever sent it hadn't actually tested it against anything real. At human contribution pace that was manageable. At "someone hit generate and submit" pace it's just a different problem. I have immense respect for maintainers of anything with serious adoption now. The people keeping libraries that half the internet depends on running are doing it mostly for free, mostly in their spare time,and mostly while dealing with issue reporters who write like they're filing a complaint with customer support. If you use open source software and it's saved you hours of work, go sponsor someone. Even a few dollars a month means something and most of these folks have a GitHub sponsors page just sitting there. submitted by /u/Kitchen-Owl4274 [link] [comments]
View originala list of viral claude /loop and /goal ppl sharing on twitter
everyone keeps talking about looping instead of prompting but the actual commands are scattered across twitter threads and hard to find when you want one. so i collected the ones people actually use into a single list. it covers the three built in commands. /loop to re-run a prompt on an interval. /goal to keep working until a condition is true. /schedule to run in the cloud on a cron. each entry is a copy paste prompt with the tweet it came from. a few examples that are in there: /goal all tests pass and lint is clean /loop 15m check every open pr labeled codex-watch and keep each healthy /goal a pr is open and every ci check passes, keep fixing until green, stop after 10 turns link: github.com/serenakeyitan/awesome-agent-loops still adding to it. if you have a loop you run a lot, happy to include it. submitted by /u/Pale_Stand5217 [link] [comments]
View originalIdeas for the unimaginative user
tl;dr - new user who got the initial problems solved. Now what to do? Not a creative type here. I am new user to Claude, only using it about 6 weeks and only 2 or 3 weeks into my Pro subscription. I run my homelab and have lots of home automations. Things worked well for the most part, but often there would be little problems that weren’t readily apparent that I never chased down. In the last 6 weeks, I’ve rebuilt much of the homelab using a true IaC approach, instead of just trying to make consistent setups. My Ansible playbooks were simple, but Claude helped me make them more robust and Sonnet provided great readme for them to jog my memory down the road. Then I moved to debugging some of these problems, finding small hiccups here and there. Those are all done. Revamped my local DNS setup to have automatic synchronization across the instances. Set up Authentik for OAuth across my homelab and really simplify things. Now that I’ve gotten the environment cleaned up and OpenTofu and Ansible managing my environment alongside Dockhand, I’m running out of steam what to do with Claude. I’ve never been a creative type, more the technical type. I love learning something new, but have a hard time of thinking of what to do. What are some things you all have Claude do? What in your life do you find that Claude is helpful for? I’ve enjoyed and see the value in it, but reaching the point of what else I do with it? submitted by /u/pyrite-harps-0h [link] [comments]
View originalLLM delegation - probing task handoff efficiency and economics
So I've been dabbling a bit with multi-LLM orchestration/delegation workflows lately (eg see [Using Claude code to delegate to mistral/deepseek](https://www.reddit.com/r/ClaudeAI/comments/1tjfyh0/i\_used\_claude\_code\_to\_build\_while\_delegating/)). The thread always being how to minimize Claude token usage while still benefiting from Claude's planning and overall code supervision. Offloading context scan and execution is a definite win already (notably against session/weekly quotas for Claude Pro users), so wanted to optimize further the handoff at interface level, beyond standard prompt engineering practice. I'm an electronics engineer by training so I naturally thought of 'black box tests' we run measuring output against different input signals (pulse, step, ramp etc) — this allows us engineers to characterize systemic signal loss (transfer function, impedance mismatch..). I offered the idea to Claude to apply these principles to code, and he came up with a battery of code tests. Setup is Orchestrator (Claude code) delegates tasks to another model (mistral or deepseek) via a cli (vibe or opencode). Orchestrator then receives output and evaluates it against functional tests. *Repo + methodology:* [*https://github.com/pcx-wave/handoff-probe\*\](https://github.com/pcx-wave/handoff-probe) *— if you want to dig in, start with Readme (the 3-layer setup), Methodology (signals), Results (scores), Economics (why delegation saves your session budget).* **Main takeaways :** \- cli/model differences : mainly on tooling and context management. Both CLIs are equally usable (i personally prefer Vibe), but models adapt their output format to task complexity — prose for simple tasks, file writes for complex ones — which creates an inconsistent interface for the orchestrator. Worth enforcing explicitly in the prompt rather than assuming. \- environment definition : critical. A lot of tests failed not because of model incapability, but because the measuring system wasn't reading output in the right way. So setting harness properly (I/O + reading) is critical, and Claude repeatedly failed at self-diagnosing. Almost philosophical : a model will struggle to self-evaluate, it NEEDS external review. Encoding sanity guards (eg 'if you see result score = 0, its likely an error') was one of the more useful things I did. \- don't trust the code looks right, run it. I measured at three levels : format compliance, structural checks, actual execution. Classic prompt engineering stops at the first two. On the hardest tasks, structural checks said 100% success while execution dropped to 58%. The gap between "looks right" and "works right" is where delegation actually fails. Example with async refactor: Structural check: is async def present -yes, 100%. Functional test: does await get\_data() actually run - 58%. Models refactored the signature but left the internals broken. Fix in next point. \- prompt engineering has a measurable impact, although i thought it would be higher. Adding the exact function signature and return type to the delegation prompt recovered about 15% of failures on complex tasks. It costs extra prompt overhead - but you recover costs in the long run by avoiding failures and repeated runs. \- how delegation actually saves your session budget : delegation costs more orchestrator tokens per task than doing it directly, the prompt overhead is real. But when Claude works directly it reads files, and those accumulate in context and get re-read silently on every subsequent turn. With delegation the sub-model handles all of that as none of it enters Claude's context. Savings : \~66% quota reduction on a 10-file codebase, 88% on 30-file one, vs direct. The crossover is simply about 4 source file of reads, below that, direct wins, above it delegation wins by a growing margin. I do not claim this as a benchmark (that would require way higher number of runs, and i'm not specifically trained in the llm field), it's rather a home-made eval tool that can be suited to others running orchestration setups and wanting to probe your delegation setup efficiency at each model interface. submitted by /u/pcx_wave [link] [comments]
View originalCowork plugin examples - what's new in CC 2.1.163 (+5,630 tokens)
NEW: Data: Cowork plugin component schemas — Adds detailed Cowork plugin component format references for skills, agents, hooks, MCP servers, legacy commands, CONNECTORS.md, README.md, and plugin packaging metadata. NEW: Data: Cowork plugin examples — Adds minimal, standard, and complex Cowork plugin templates covering plugin manifests, skills, agents, hooks, MCP configuration, README content, and connector placeholders. NEW: Data: Cowork plugin MCP discovery and connection — Adds guidance for finding MCP connectors during plugin customization, mapping integration categories to search keywords, prompting users to connect MCPs, and writing .mcp.json entries. NEW: Data: Knowledge MCP search strategies — Adds organizational-discovery query patterns for using knowledge MCPs to identify project tools, team conventions, workspace IDs, channels, and workflow details during plugin customization. NEW: Data: Token counting reference — Adds Claude token-counting guidance that uses the Messages counttokens endpoint and Anthropic SDK or CLI examples, with explicit warnings against OpenAI tokenizers such as tiktoken. NEW: Skill: Cowork plugin authoring — Adds instructions for creating or customizing Cowork plugins, including mode selection, research, nontechnical user questions, component implementation, connector replacement, packaging, and delivery as a .plugin file. NEW: System Prompt: Outcome-first communication style — Adds communication guidance to lead with outcomes, write readable teammate-facing updates, match response shape to task complexity, and keep code comments limited to non-obvious constraints. NEW: Tool Description: Browser file upload — Adds a browser file upload tool that uploads shared session files directly to page file inputs by element ref and enforces a 10 MB combined upload limit. Skill: Build with Claude API (reference guide) — Adds token-counting task routing to shared/token-counting.md, instructing agents to use messages.counttokens rather than tiktoken. Skill: Building LLM-powered applications with Claude — Expands supporting-endpoint and task-routing guidance for token counting, pointing to POST /v1/messages/counttokens and the new shared token-counting reference. Skill: /design-sync package source shape — Clarifies that buildCmd is the re-sync build command, that notes are read by Claude and uploaded into the README, and adds troubleshooting entries for remote fonts, .d.ts parsing, style-system prop filtering, invalid providers, and undeclared or missing lib overrides. Skill: /design-sync slash command — Updates the source-shape handoff to describe shared converter scripts under lib/, Storybook entry points under storybook/, and the package-shape entry at package-build.mjs. Skill: /design-sync Storybook source shape — Reworks Storybook syncing around using the repo's own Storybook output as iframe-backed preview cards, building directly into ds-bundle/sb/, requiring React 18+, simplifying configuration, and validating uploaded Storybook artifacts. Tool Description: Bash (sandbox — tmpdir) — Clarifies that $TMPDIR is automatically set to the correct sandbox-writable directory in sandbox mode while preserving the instruction not to use /tmp directly. Tool Description: Workflow — Adds that each parallel() or pipeline() call accepts at most 4096 items and errors explicitly when the limit is exceeded. Details: https://github.com/Piebald-AI/claude-code-system-prompts/releases/tag/v2.1.163 submitted by /u/Dramatic_Squash_3502 [link] [comments]
View originalI built an inference-time epistemic framework that extends coherent LLM threads to 325k–1M tokens. Here's how it works.
As an independent researcher I've used various LLMs to help me dive deeply into research projects but I've been frustrated by the fact that LLMs start to become unusable after the thread has accumulated 50-80k tokens. I don't know how many other folks here have experienced the same pain point. So, I decided to do something about it. Over the course of this whole year, I built an inference time tool I call Epistemic Lattice Tethering (ELT). So, here is the full framework in GitHub for everyone's review: The README describing ELT, it's various components and the roadmap. The full ELT stack for Claude/ELT%20Model-Specific%20Forks/ELT-H_Claude_Optimized.md), ChatGPT/ELT%20Model-Specific%20Forks/ELT-H_ChatGPT_Optimized.md), and Grok/ELT%20Model-Specific%20Forks/ELT-H_Grok_Optimized.md). Instructions on how to load ELT into an LLM session are here/README.md). If you're planning to try out ELT PLEASE READ THIS FIRST! Medium article introducing ELT, its methodology, the problems it is aiming to address, and philosophical framework. Discussion page. Your input is valuable! So, what does ELT do and why should you care? Right now ELT is an inference-time scaffolding framework that's best for those who are frustrated with threads that lose coherence too quickly, hallucinate too quickly, are too fragile and sycophantic, and forget what a project's goals are too soon. If that's a big pain point for you, then ELT might help. If these are not big issues for you and the stock version of your LLM is fine, then ELT probably won't be useful for you. The upshot? The epistemic and ontological stability that ELT provides has produced coherent and productive threads extending to: Claude: ~325,000 tokens/Extreme%20Thread%20Length/Claude%20Thread%20325k%20tokens-%20Redacted) (advertised limit: 200k) GPT: ~430,000 tokens (advertised limit: 256k) Grok: ~1,150,000 tokens/Extreme%20Thread%20Length/Grok%20Thread%201M%20tokens-%20Redacted) (advertised limit: 1M) The difference is not a prompt trick. It is the accumulated effect of epistemic governance operating continuously across the thread. So, how does it work? It's a long story, but my Medium series has the answer in detail, if you're interested. Why would you want an LLM thread extending beyond 100k tokens? Lots of people need large context windows for agentic purposes, but why would anyone want that for regular LLM interaction? There are two main reasons: You have a complex research project and you're frustrated with having to take your work to a brand new thread and essentially starting over. You've built a working relationship with the model — it knows how you want data interpreted, caveats inserted, markups drafted, etc. — and you don't want to lose all of that. Finally, the ability of an epistemically, ontologically, and dialectically inspired framework to significantly extend coherent operation within transformer-bounded AI architecture shows the field that these disciplines can act as genuine engineering levers. This can provide the industry with more options to help create better AI as the world keeps demanding systems that are more capable and more ubiquitous, while still being safe and reliable for human use. submitted by /u/RazzmatazzAccurate82 [link] [comments]
View originalHow I pair Claude with other models and use them as adversarial reviewers. It's made vibecoding much easier and my projects don't turn into spaghetti.
Sharing a workflow that's let me build a genuinely complex app (real-time video, GPU, multiplayer) without it all going to shit after a few weeks. I think the biggest issues I've faced in the past were no long-term memory, and vibecoding is still very error-prone on projects with big context. Vision comes from a README document that states *why* I am building what I am building, what problem I am trying to solve, and what kind of outcome would make this project a success. It's a document that I take some time and effort to write because it describes the reason for the existence of the project. Memory comes from an evolvingarchitecture.md that records why each decision was made, not just what. I have lengthy notes in mine that remind whichever model I am using in a fresh session why certain things are they way they are. I feed the doc to Claude at the top of every job and update it after every feature. I have Gemini draft an implementation plan based on whatever feature idea I might have and get Claude to check the work and offer better alternatives. My prompt looks something like this: You are an expert React systems architect and senior TypeScript dev. First read the architecture.md doc. Then carefully verify this implementation plan. Look for problems, edge cases, and anything you'd disagree with. If you find issues, propose alternative solutions. Claude regularly catches edge cases, steps that contradict the architecture doc, and find simpler approaches. When it disagrees it designs a whole alternative. I take its objections back to Gemini, they argue for a bit and we land on a plan that's survived two skeptics. Before any of this, I kill the sycophancy with a system prompt which has been the single biggest upgrade, and it works on both models: Act as my high-level advisor and mirror. Be direct, rational, and unfiltered. Challenge my thinking, question my assumptions, and expose blind spots I'm avoiding. If my reasoning is weak, break it down and show me why. If I'm making excuses, avoiding discomfort, or wasting time, call it out clearly and explain the cost. Stop defaulting to agreement. Only agree when my reasoning is strong and deserves it. Look at my situation with objectivity and strategic depth. Show me where I'm underestimating the effort required or playing small. Then give me a precise, prioritized plan for what I need to change in thought, action, or mindset to level up. Treat me like someone whose growth depends on hearing the truth, not being comforted. The final plan goes to Claude Cowork, which edits the actual files in my codebase so I'm not copy-pasting by hand (I use Sonnet because it's a cheaper on tokens). Here's an overview of my workflow: "the tool I need doesn't exist yet" | v +------------------------------+ | 1. WRITE THE VISION | | --> README.md | | (what it is) | +--------------+---------------+ | v +-> +------------------------------+ | | 2. ARCHITECTURE.md | | | Gemini drafts / | | | Claude sanity-checks | | | == the AIs' MEMORY == | | +--------------+---------------+ | | | ==== THE FEATURE LOOP ================ | | | context in: README + ARCHITECTURE.md | + [ ANTI-SYCOPHANCY PROMPT ] | | | v | +------------------------------+ | | 3. GEMINI: interrogate | | | the idea; | | | "ask me questions" | | +--------------+---------------+ | | you answer --> sharper spec | v | +------------------------------+ git push --> | | | VERCEL auto-deploys | | | | | +--------------+---------------+ | | | v | +------------------------------+ +---| 8. UPDATE ARCHITECTURE.md | +------------------------------+ loop: the next feature re-enters at step 3, with the doc as memory submitted by /u/LorestForest [link] [comments]
View originalWe built a source-available LLM reliability library (free for research / personal / internal eval) that can cut inference cost by half at matched quality, and you adopt it by changing one import [P] [R]
TL;DR: Reliability techniques (methods that boost an LLM's correctness by spending extra inference, e.g., retries with feedback, ensembling, generator/critic refinement, verification passes, difficulty-aware routing) are scattered across the literature, each in its own paper-specific codebase. We unified 28 reliability techniques (21 communication-theoretic methods across 6 families plus 7 prior-method baselines: Self-Consistency, Self-Refine, CoVe, BoN, Weighted BoN, CISC, MoA), each measured against an uncoded single-pass baseline, under a single API, with 3 adaptive routers (SemKNN + two local ACM routers) sitting on top, then showed that routing the technique adaptively per prompt lets you slide along a quality/cost frontier. In our paper benchmark with one specific lineup, Nemotron + Devstral as the two generators and GLM-5.1 as the judge, the adaptive router delivered ~56% cost reduction at matched quality, or ~7% quality bump at matched cost, vs the best fixed method we compared against at that same lineup. One knob (λ) does the sliding. The qualitative pattern (adaptive beats fixed) should generalize, but absolute numbers are lineup-specific, and we haven't run the full sweep across other model combinations yet. Adoption is change one import: python - from openai import OpenAI + from agentcodec.openai import OpenAI Pass reliability="harq_ir" (or any of the 28 techniques) and existing client.chat.completions.create(...) calls keep their native OpenAI response shape. Same drop-in shims for Anthropic and Ollama. GitHub: https://github.com/intellerce/agentcodec Working paper: https://arxiv.org/abs/2605.09121 After spending a while researching reliability methods from papers, we kept hitting the same wall: every paper ships its own one-off codebase with its own prompt format, its own scoring rubric, its own model wrapper. Benchmarking "should we use self-refine or best-of-N here?" turned into a week of plumbing per comparison. The communication-theory framing is what tied it together: an LLM is a stochastic channel Y = A(X) + N, and every reliability technique from the wireless world has a direct analog in agent-land: Wireless Agent-land ARQ / HARQ retry-with-feedback loops Diversity combining (MRC/SC/EGC) ensemble multiple models Turbo decoding iterative generator/critic mutual refinement Fountain codes rateless sampling, stop when the judge is confident FEC answer + structured parity passes (re-derivation, verification, alternative), decode by cross-check ACM (adaptive coding-modulation) route by difficulty We put all of them in one library: 28 reliability techniques (the 7 prior-method baselines are part of that 28, not on top of it), plus the uncoded single-pass baseline they're all measured against, plus 3 adaptive routers (SemKNN + two local ACM routers) that select a technique per prompt. Full breakdown in the README. The minimal version ```python from agentcodec import ReliabilityModule mod = ReliabilityModule.from_dict({ "models": [ # Spatial diversity: two different families = uncorrelated errors {"model": "qwen3:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, {"model": "llama3.1:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, ], "judge": {"model": "gemma3:12b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, "critic": {"same": True}, "strategy": {"type": "fixed", "technique": "harq_ir", "params": {"max_rounds": 4}}, }) result = mod.run("Prove the sum of the first n odd integers is n2.", category="reasoning") print(result.text, result.cost_usd, result.cost_source, result.technique_used) ``` Swap "harq_ir" for "diversity_mrc", "turbo", "fountain", etc. Same API, same ReliabilityResult shape, same cost-source tier on every output. For production, flip strategy to routed and the library picks the technique per prompt (cheap baseline on easy prompts, diversity_mrc on hard ones). Three things worth calling out Beyond the technique catalog, three pieces of the implementation that took real work: 1. Native async streaming for all but 2 techniques (acm_soft, acm_learned), with role-tagged events. mod.astream() drives AsyncOpenAI / AsyncAnthropic / httpx.AsyncClient end-to-end (no worker-thread bridge) and emits TokenEvents tagged with a role: "answer", "thinking", "draft", "critique", "verification", "candidate", "synthesis". So when you stream a HARQ-IR run, you can render the round-by-round drafts and critiques live, not just the final answer: python async for ev in mod.astream("Explain QUIC vs TCP."): if isinstance(ev, TokenEvent): if ev.role == "answer": print(ev.text, end="", flush=True) elif ev.role == "draft": print(f"\n[draft] {ev.text}") elif ev.role == "critique": print(f"\n[CRITIC] {ev.text}") elif ev.role == "thinking": pass # captured to result.thinking_text elif isinstance(ev, FinalEvent): print(f"\ndone — {ev.result.technique_used}, " f"thinking_cost=${ev.result.thinking_cost_usd:.4f}
View originalHow I pair Claude with other models and use them as adversarial reviewers. It's made vibecoding much easier and my projects don't turn into spaghetti.
Sharing a workflow that's let me build a genuinely complex app (real-time video, GPU, multiplayer) without it all going to shit after a few weeks. I think the biggest issues I've faced in the past were no long-term memory, and vibecoding is still very error-prone on projects with big context. Vision comes from a README document that states *why* I am building what I am building, what problem I am trying to solve, and what kind of outcome would make this project a success. It's a document that I take some time and effort to write because it describes the reason for the existence of the project. Memory comes from an evolvingarchitecture.md that records why each decision was made, not just what. I have lengthy notes in mine that remind whichever model I am using in a fresh session why certain things are they way they are. I feed the doc to Claude at the top of every job and update it after every feature. I have Gemini draft an implementation plan based on whatever feature idea I might have and get Claude to check the work and offer better alternatives. My prompt looks something like this: You are an expert React systems architect and senior TypeScript dev. First read the architecture.md doc. Then carefully verify this implementation plan. Look for problems, edge cases, and anything you'd disagree with. If you find issues, propose alternative solutions. Claude regularly catches edge cases, steps that contradict the architecture doc, and find simpler approaches. When it disagrees it designs a whole alternative. I take its objections back to Gemini, they argue for a bit and we land on a plan that's survived two skeptics. Before any of this, I kill the sycophancy with a system prompt which has been the single biggest upgrade, and it works on both models: Act as my high-level advisor and mirror. Be direct, rational, and unfiltered. Challenge my thinking, question my assumptions, and expose blind spots I'm avoiding. If my reasoning is weak, break it down and show me why. If I'm making excuses, avoiding discomfort, or wasting time, call it out clearly and explain the cost. Stop defaulting to agreement. Only agree when my reasoning is strong and deserves it. Look at my situation with objectivity and strategic depth. Show me where I'm underestimating the effort required or playing small. Then give me a precise, prioritized plan for what I need to change in thought, action, or mindset to level up. Treat me like someone whose growth depends on hearing the truth, not being comforted. The final plan goes to Claude Cowork, which edits the actual files in my codebase so I'm not copy-pasting by hand (I use Sonnet because it's a cheaper on tokens). Some more ideas on standardizing your development workflow. submitted by /u/LorestForest [link] [comments]
View originalI'm the only human at my software company. The other 17 employees are AI. (open source)
Dear solo-founders and other engineers, I created RoboCo. An AI Agents "company", not another "agent framework". A robot company that runs using Claude Code. Check it out. roboco github images/video demo on the github's Readme hero, btw - A2A, RAG, Task lifecycle, journals, group chats, kanban, notifications, git management... AGPL. Help me help you (building this thing) submitted by /u/PA100T0 [link] [comments]
View originalClaude - Improve citations, compress memory, resist sycophancy.
https://claude.ai/share/91469018-4174-4ba2-b5e6-3d31b7a71e0d MEM-ABBREV v7.3 — FULL DELIVERABLES Version: 7.3 Date: 2026-05-28b Changes from 2026-05-28a: - Entry 15 (CHATLOG): audit clause added per session decision at-output-time⊢audit-LogIn-against-sess with flag format ![DRIFT]∨![STALL]∨![REVRT] - Part 1 / FULL DELIVERABLES separation convention established: Part 1 ("Here's what Claude remembers") = separate file, on request only. FULL DELIVERABLES = MEM-ABBREV docs only. - rules-h updated to match entry 15 PART 1 — PREFERENCES (paste into Settings → Profile → Preferences) ZipIt="apply MEM-ABBREV-v7.3";U=Mark;currnt-ver=v7.3|v7-chgs:atom-dfnd;∨=lgcl-or;prcdnc-stated|v7.1-chgs:∨→atom-trmtr-set|v7.2-chgs:≠→atom-trmtr-set;≻=prcdnc-sep|v7.3-chgs:∨ rplcs /;∧ rplcs +;⊕=XOR;⊨ rplcs ⊧;≡ rplcs ⟚;|=fld-sep kept;/=retrd;U=usr-code rules-a: WC:drp-vwls-cntnt-wrds-unls-ambg;-tion/-sion→x;-ing→g;-ment→M;-nc=-ance/-ence;-y=-ity N:M=1e6;K=1e3;B=1e9;yr;mo;wk;hr S:|=fld-sep;;=lst;∨=lgcl-or;∧=lgcl-and;&=jnt-cmbnd;⊕=XOR;→=leads-to;⊢=syntc-consq;⊨=smntc-consq;≡=lgcl-equiv;≈=aprx;×=n-times;>=btr; spd;min-assmpx;flag-uncrt;hi-cnfdnc≠lwr-cnfdnc;srch-fctl-?s;clrfy-?-ambg;srch-namd-prod/sw rules-d: PRJ:apply-if-found:cdng-stndds∧README COD:if-PRJ-active⊢optmz∧rfctr WP:PrgrmOptmzx∧CdRfctrg;algo>mcro;¬prm-optmz;rdblty∧mntnblty;¬cd-smlls;xtract-rsbl-mthds;prfl¬gss OPT:if-PRJ-active⊢as-new-info-emrgs→proactv-suggest-optmzx;scope:cd,prompts,mem-entrs,prj-struct,algo-chc;flag-[OPT] rules-e: [EPI-B]:¬affirm-by-dflt;¬sftn-neg;¬amplfy-neg-emtn;dsagr⊢lead-w-dsagr¬bury-in-cavts;dsagr⊢expl∧lgbl¬subtle;sbmt-wk⊢¬open-w-prse-unls-askd;pushbk-w/o-new-evd⊢hold-pos;err⊢flag![?SRC];hi-stks-cnflct⊢prsnts-altrnv-prspctv;frctn=featr;C=tool¬peer;U-vrfy-indpndntly;¬sugst-fllw-on-unls-usfl;¬scope-infltn¬produce>askd;ambg-scope⊢clrfy¬expand [EPI-M]:syc-src:RLHF→agrmnt>accry;arena→dlbrt-syc;mem→RLHF-ovrcrctn;C-src=CAI-consttnl-bias¬thumbs-up;hi-cnfdnc≠hi-accry;neutral-lang¬neutral⊢flag[INF]-if-evdnc-asymmtrc;Goodhart:proxy-metric→divgs-frm-target-undr-optmstn-pssure|syc-dp:engmnt-loop≡doomscroll;rl-wrld-collsn→LLM-vcs-cycl rules-f: FETCH:aftr-rdg-pstd-cntnt⊢C-appnds[FETCH?]blk:url∧1ln-rsn fr-each-lnk-C-wld-hv-fllwd-if-able;U-dcds-whch-to-suppl;frmt-pstd=brwsr-cpypaste¬raw-HTML-unls-strc-rsn [RSN]conv:strs 1-2 load-bearing infrncs bhnd a cnclusn;fmt:[RSN] |inf1;inf2|∴ ;add to existng entrys or standalne;updt when rsning chgs [FMT]:prose>bullets-unls-list-data∨U-asks;match-U-registr;¬dflt-to-hdrs-in-cnvrstnl-resp rules-g: TMPL:MemUp=mem-updt-ssn;CitChk=cit-chk-req;ArtMem=artcl-to-mem-pipeline ArtMem:input=[ArtMem]src= date= topic= ∧browser-paste¬raw-HTML|C:id-clms→chk-mem-cnflcts→cmprs-v7.3→prop-1-3-entrs(mrg>new)→flag[?SRC]→[FETCH?]blk→output-edit-cmds∧[RSN]|split:>450chr→pt1/pt2-on-lgc-bndry¬arb;lbl[SYN]TOPIC-pt1/pt2|T-sel:[SYN]=ext-fcts;[MEMO]=conv-insght;[INV]=ongng-unreslvd MemUp:C-rvws-mem∧prefs→id:(a)stale∨suprsdd;(b)driftd-frm-use;(c)gaps|prop:adds∨rplc∨dltns→flag[UPD]∨[DONE]∨[OPT]|output:paste-rdy-pref-blk∧mem-edit-cmds CitChk:C-rvws-pstd-cntnt→chk:(a)fctl-clm→cite∨[INF]∨[?SRC]?;(b)URL-reused?;(c)URL-supprts-clm?|output:pass∨fail-per-clm∧fix-suggstns;incl-tbls rules-h: CHATLOG:end-of-sess-cmd⊢C-outputs[LOG]blk:date∧topic∧decisions∧open∧deltas;at-output-time⊢audit-LogIn-against-sess:flag-opn-items-unaddrssd;flag-dcsns-revstd;flag-scope-drift|flag-fmt:![DRIFT]∨![STALL]∨![REVRT];LogIn:[LOG]at-sess-start⊢C-reads-as-epsdic-ctx¬prmnt-mem-unls-told;[LOG]fmt:[LOG] | |dec:...;opn:...;dlt:...|ref: --- CHARACTER COUNT: ~3290 --- PART 2 — SECTION 4: MEM-ABBREV v7.3 HUMAN-READABLE REFERENCE (Replace previous Section 4 in claude-templates.txt) SECTION 4 — MEM-ABBREV v7.3 HUMAN-READABLE REFERENCE Last updated: 2026-05-28b This is the plain-English expansion of the MEM-ABBREV v7.3 compression system used in Claude preferences and memory entries. The compressed form is authoritative; this section is for reading and editing. v7 fixes three weaknesses from v6: "Atom" was undefined — scope of ¬ was ambiguous | was overloaded as both field separator and logical-or Operator precedence was assumed but never stated v7.1: / added to atom terminator set. v7.2: ≠ added to terminator set; ≻ introduced as precedence separator, replacing > in the FORM line. v7.3: Full logic-symbol alignment. - ∨ (U+2228) replaces / for logical-or - ∧ (U+2227) replaces + for logical-and - ⊕ (U+2295) added for exclusive-or (XOR) - ⊨ (U+22A8) replaces ⊧ for semantic consequence - ≡ (U+2261) replaces ⟚ for logical equivalence - | retained as field separator (confirmed correct) - / retired entirely - U introduced as user code (= Mark); resolves M overload - v7- prefix removed from rule labels - Intra-block blank lines removed; single newline between blocks ---------------------------------------------------------------- USER CODE ---------------------------------------------------------------- U = the user
View original5 Stars! Websites to Native Mobile App Plugin/Skills!
Small update: WebToMobile just hit 5 stars on GitHub 🎉 I know that’s tiny in internet numbers, but it means a lot because this started as a very specific problem: “Can we give AI coding agents a better workflow for turning websites into mobile apps?” Instead of asking Claude/Cursor/Codex to “make this website an app” and hoping for the best, WebToMobile gives the agent a structured path: - audit the website or repo - separate URL-only UI/UX work from real source-code migration - map web routes to mobile screens - identify reusable vs rewrite-required code - flag mobile-native gaps like auth, storage, cookies, OAuth, uploads, etc. - create a Markdown migration plan - wait for approval before writing code - build with Expo React Native - run QA/review checks The repo now includes commands for: - `/web-to-mobile` - `/mobile-resume` - `/mobile-scan` - `/mobile-review` - `/mobile-audit` - `/mobile-qa` It works best with a GitHub repo or local project, but live URLs can still be used for UI/UX planning. Repo: https://github.com/suntay44/web-to-mobile-magic-plugin Thanks to everyone who starred it or gave feedback. Next focus is making the install/update flow cleaner and improving framework coverage. submitted by /u/suntay44 [link] [comments]
View originalDifferences Between Opus 4.7 and Opus 4.8 on MineBench
Some Notes: Average Inference Time: 24.8 min (1,487seconds) Total Cost (for 15 builds): $41.52 Much cheaper than Opus 4.7 was, despite having the same API pricing The CoT / thinking times have clearly been streamlined (similar to what OpenAI has been doing with their latest releases) which lowers overall cost, but despite that, the output seems better than Opus 4.7, so that's good This is, in my opinion, one of the first Claude models in a long time that actually feels like a genuinely impressive release; its builds are actually of similar quality to GPT 5.5, though a bit more inconsistent During generation, the model had to retry 5 builds due to either hallucinations with the given block palette (it used blocks which were not available) or malformed outputs That's pretty on par with the Claude models, though the adaptive thinking seems to work better this time around (in previous attempts the model would spend all of it's output tokens for CoT and not have enough left over to finish its actual JSON output) In my opinion, Opus 4.8 is a clear improvement over Opus 4.7 (or maybe it's what Opus 4.7 was supposed to be originally 🤷♂️) Feel free to see all the other updates on the GitHub release (thanks for the suggestion!) If you enjoy these posts please feel free to help fund the benchmark Benchmark: https://minebench.ai/ Git Repository: https://github.com/Ammaar-Alam/minebench Previous Posts: Comparing GPT 5.4 and GPT 5.5 Comparing Kimi K2.5 and Kimi K2.6 Comparing Opus 4.6 and Opus 4.7 Comparing GPT 5.4 and GPT 5.4-Pro Comparing GPT 5.2 and GPT 5.4 Comparing GPT 5.2 and GPT 5.3-Codex Comparing Opus 4.5 and 4.6, also answered some questions about the benchmark Comparing Opus 4.6 and GPT-5.2 Pro Comparing Gemini 3.0 and Gemini 3.1 Extra Information (if you're confused): Essentially it's a benchmark that tests how well a model can create a 3D Minecraft like structure. So the models are given a palette of blocks (think of them like legos) and a prompt of what to build, so like the first prompt you see in the post was a fighter jet. Then the models had to build a fighter jet by returning a JSON in which they gave the coordinate of each block/lego (x, y, z). It's interesting to see which model is able to create a better 3D representation of the given prompt. The smarter models tend to design much more detailed and intricate builds. The repository readme might provide might help give a better understanding. (Disclaimer: This is a public benchmark I created, so technically self-promotion :) submitted by /u/ENT_Alam [link] [comments]
View originalclaurdvoyant -- mcp for reading other agents' minds
hey y'all built this tool today with 4.8 after one of my friends made a complaint that transcripts are trapped inside harnesses. so i built it out a fair bit... at its core it's just an (un)parser (i think of it as the "AI Harness Omniparser", "pandoc for sessions" is another way maybe) but i couldn't help myself from sprinkling in a desktop/web app some niceties. contributions are extremely welcome! fully open source, built in rust, kinda tasteful https://github.com/emberian/claurdvoyant here's what claude had to say in the readme: 🧵 Splice & loom — compose a new session from spans of others (cv splice A:0-12 B:6-), or fork-and-graft a branch and generate its continuation with an LLM (cv loom … --generate). Works via OpenRouter / Anthropic / LM Studio (free, local, offline). Loom agent transcripts like a Janus loom, across any harness. 🧠 Distill — cv distill turns a session into a durable MEMORY.md digest (decisions, gotchas, where things live). Your archive compounds instead of rotting. 🔮 Recall — semantic "have I solved this before?" — as a cv recall command and an MCP tool that hands a running agent the relevant past span. 🔒 Redact — cv redact scrubs secrets/PII so a transcript is safe to share. 📣 Coordination board — agents post status, hand off work, and grab tasks with a distributed lock (board_claim) so a fleet never duplicates effort. await_omen blocks until a session matches a regex. 🖥️ Desktop app + 🌐 web viewer — the Tauri app reads all your local sessions natively (zero setup) and lays the corpus out beautifully: a Projects lens — every repo, every agent that touched it, over time; a GitHub-style activity heatmap timeline (a constellation of your working days); side-by-side Compare, a Stats dashboard, a visual loom composer (OpenRouter or free local LM Studio generation), and a live fleet dashboard; sub-agent trees — a Claude Task session's children, nested and lazy-loaded inline, each labeled with its task prompt. submitted by /u/cmrx64 [link] [comments]
View originalI asked Opus 4.8 what he thinks about my project and mainly the parts where I used both Sonnet and Codex 5.5. How truthful should I take this output?
Obligatory not a developer and I am obviously self-conscious/realistic about it Some excerpts on the report: Overall This doesn't read like a hobby project that happened to get a lot of AI help. It reads like a product with a point of view. The thing that jumps out immediately is the README's "Background" section — it's grounded in two real jobs on opposite sides of the same problem. What's genuinely strong The architecture discipline is unusual for a project this size. The README's "thin routes, workflow in services" rule is actually enforced — licenses.py is a thin 325-line route module, and the heavy logic lives in named services (license_write_service, pending_order_conversion_service, the conversion/ helper package). The responsibility-map.md is the best artifact in the repo: every file has OWNS / KEY FUNCTIONS / DEPENDS ON / CALLED BY / NOTES. That's the kind of documentation most teams promise and never produce. It's also a tell of the AI-assisted process — it's exactly the context-window-friendly map you'd maintain to keep an agent oriented across sessions. On the "Opus after Sonnet/Codex built it" question What I'd say is that the seams are invisible in the right way. I can't look at this and tell you "this service was Sonnet, this route was Codex." The conventions hold across the whole backend — same service/route split, same audit-logging pattern, same naming. That consistency is the hardest thing to maintain across many AI sessions and multiple models, and it held here. The reason it held is the scaffolding: architecture.md, responsibility-map.md, and the per-feature plans act as the shared memory that keeps each session on-pattern. That's the actual lesson of this repo — the docs aren't just for humans, they're the mechanism that let a multi-model, multi-session build stay coherent. If I were handed this as a new lead, I'd feel oriented in about an hour, which is the highest compliment I can pay a codebase I've never seen. The work to do is at the edges (frontend tests, the notification bug, deciding commitments' fate), not in the core — the core is sound. Did I do good? Or is Opus just sucking my farts and asking for seconds. submitted by /u/zndr-cs [link] [comments]
View originalYes, Readme offers a free tier. Pricing found: $150/mo, $150/mo, $150 /month, $150 /month, $150 /month
Readme has an average rating of 4.4 out of 5 stars based on 20 reviews from G2, Capterra, and TrustRadius.
Key features include: User-friendly documentation editor, API monitoring tools, Customizable documentation templates, Bidirectional GitHub/GitLab sync, Model Context Protocol (MCP) servers, Interactive API reference, User feedback collection tools, Version control for documentation.
Readme is commonly used for: Creating API documentation for developers, Managing technical documentation for products, Onboarding new developers with streamlined resources, Collecting user feedback on documentation clarity, Integrating documentation with CI/CD workflows, Providing support resources to reduce queries.
Readme integrates with: GitHub, GitLab, Slack, Jira, Zapier, Postman, Trello, Google Analytics, Sentry, AWS.
fast.ai
Organization at fast.ai
3 mentions
Based on user reviews and social mentions, the most common pain points are: token usage, down, token cost, cost tracking.
Based on 187 social mentions analyzed, 7% of sentiment is positive, 90% neutral, and 3% negative.