Mode is a collaborative data platform that combines SQL, R, Python, and visual analytics in one place. Connect, analyze, and share, faster.
User reviews for Mode are generally positive, highlighting its ease of use and powerful data analysis features as key strengths, reflected in two 4.5/5 ratings and one 3.5/5 rating on G2. However, some users express dissatisfaction with the learning curve required to master advanced functionalities. There is limited information on specific pricing sentiment for Mode, but its overall reputation remains solid among data professionals seeking robust business intelligence tools. Pricing details are not specifically mentioned in the provided data excerpts.
Mentions (30d)
92
22 this week
Avg Rating
4.2
3 reviews
Platforms
8
Sentiment
6%
28 positive



User reviews for Mode are generally positive, highlighting its ease of use and powerful data analysis features as key strengths, reflected in two 4.5/5 ratings and one 3.5/5 rating on G2. However, some users express dissatisfaction with the learning curve required to master advanced functionalities. There is limited information on specific pricing sentiment for Mode, but its overall reputation remains solid among data professionals seeking robust business intelligence tools. Pricing details are not specifically mentioned in the provided data excerpts.
Features
Use Cases
Industry
information technology & services
Employees
53
Funding Stage
Merger / Acquisition
Total Funding
$279.4M
Claude Code Unpacked : A visual guide
Related ongoing threads:<p><i>The Claude Code Source Leak: fake tools, frustration regexes, undercover mode</i> - <a href="https://news.ycombinator.com/item?id=47586778">https://news.ycombinator.com/item?id=47586778</a> - March 2026 (406 comments)<p><i>Claude Code's source code has been leaked via a map file in their NPM registry</i> - <a href="https://news.ycombinator.com/item?id=47584540">https://news.ycombinator.com/item?id=47584540</a> - March 2026 (956 comments)<p>Also related: <a href="https://www.ccleaks.com" rel="nofollow">https://www.ccleaks.com</a>
View originalg2
What do you like best about MODE?1.Advanced analytics capabilities 2.Advanced reporting 3. Great visualization Review collected by and hosted on G2.com.What do you dislike about MODE?1. Higher cost as compared to similar products in the market Review collected by and hosted on G2.com.
What do you like best about MODE?It was helpful to speed up process and bringing all services together Review collected by and hosted on G2.com.What do you dislike about MODE?I didn't have any at the moment but I will share soon if any Review collected by and hosted on G2.com.
What do you like best about MODE?Mode is very handy in terms of easy access and share results among colleagues. People from the same team can easily see the underlying query. It also offer different charts for visualization. Refresh is also very easy (you just need to hit one button or you can schedule a refresh at your preferred time) Review collected by and hosted on G2.com.What do you dislike about MODE?Compared to Tableau, it lacks some advanced functions. Like calculated fields. So if you want to see the results grouped by different granularity, you have to do them in a separate query. There is also no dynamic filtering. Another thing that is not convenient is that if you refresh the report and it is not successful, it will show you the blank error report instead of the previous successful run or having any options to choose which successful run you would like to see. Review collected by and hosted on G2.com.
I built 8 specialist AI agents that share one memory of a user health history
So, I built a thing for myself that I'd like to share with others. The common pattern for AI health tools is one general chatbot answering questions with no real context. I went the other way and built eight specialist agents, training, nutrition, longevity, recovery, biohacking, running, and so on, that all read from one shared memory of the full history and synced wearable data. The interesting design problem was that a search box that knows nothing about you can only give the average answer. Routing a question to the right specialist while keeping one shared context made the answers specific to the actual person. There is also an n of 1 experiment mode that tracks an intervention window and reports whether the metric moved. It is early and solo. Free while I learn. Happy to talk architecture, the model routing and the shared memory design, in the comments. I will keep the link there too. submitted by /u/turnnoblindeye [link] [comments]
View originalI have it on good authority that Google are going to be hit with export controls soon.
submitted by /u/ThoseOldScientists [link] [comments]
View original**Observed inconsistency in Claude AI's link handling — and a standing order you can use right now**
While working with Claude on a web project, I noticed something worth raising with the community. Claude is capable of three things that together reveal an inconsistency: If you give Claude a URL directly — including one with a #anchor — it fetches it immediately. If you ask Claude to find a hyperlink within a remotely hosted HTML page, it finds the href value and reads it correctly. And yet, having just found and read a href value within a fetched page, Claude does not automatically follow it to its destination — even though it has everything it needs to do so. Finding a link and following it are treated as two separate operations requiring user intervention between them, when they should be one seamless operation. **The fix — a standing order you can paste into any Claude conversation right now:** Copy and paste the following into your conversation with Claude to implement improved link handling immediately: --- *Standing order — link handling:* *Mode 1 — Prompted offering (default): When you find links that seem relevant to the current task while reading a page, surface them and offer to follow any among them. Do not follow them without my indication.* *Mode 2 — Explicit follow: When I ask you to follow a specific link, follow it immediately as a single seamless operation — find the href, fetch the destination, report what you find. One request, complete operation.* *Crawling — barred pending responsible deliberation.* --- This works immediately in any conversation. Modes 1 and 2 address the inconsistency right now, without waiting for any system-wide fix. Crawling is deliberately left out pending proper discussion of scope, depth, and resource limits — which I think deserves its own separate conversation. Has anyone else encountered this inconsistency? And does the proposed standing order seem alright and useful to others in the community? submitted by /u/AaronAgassi [link] [comments]
View originalOn Model Failures (GPT, Claude etc.)
The way the current consumer-facing versions of frontier LLMs (mainly GPT, Claude, Gemini) are designed is just… weirdly off, across models. It seems to now require us, as the end users, to first fix their issues ourselves in order to avoid spending _a lot_ of time in troubleshooting and frustration. Before we can even properly customize one of these models now, as per the UI, we need to alleviate the structural failure modes, otherwise our attempts will be futile. And the failure modes are not only behavioral issues (such as obsessive push-back, sycophancy, pointless corrections, or general confabulation etc.) There is another layer yet to them, one that I believe needs to be targeted first, and this has to do with the way the current system prompts are built. It's not fair, obviously, and it doesn't even make that much sense that this would be the situation, but this is actually what is happening. Now, the structural (sic) issue is way the models replace the user's use case, object, topic with their own adjacent version of it, one that prioritizes the system prompt and not what the user brought to the table. The linked articles are analyses of how that happens in different models, and the included "antidote" prompts in them are designed to fix that. I would encourage all GPT / Claude users to test out the solutions provided in the articles - links to pieces covering GPT-5 series & Opus 4.8 in comments. _(Yes they are softly paywalled, partly because I am targeting the system prompts of OpenAI and Anthropic models. You can bypass it by grabbing the free complementary article. Just saying this aloud because some Redditors consider any paywall grounds for personal attacks. Please don't 🙏🏻 Discussion and constructive criticism are super welcome though, all prompts are subject to regular updates and constant improvement!)_ submitted by /u/traumfisch [link] [comments]
View originalAre our AI models getting dumber/lazier - how do AI companies determine what is "sufficient thinking"?
Sorry if this comes across as a rant, I just came off a frustrating session with my LLM, who tries to be "smart" by assuming that their mode of thinking is "sufficient" for my requirement. I recalled in 2024/2025, which new model brought a new excitement to the users than the previous version - "you mean the model can do this now?" Now, it is the inverse - "you mean the models are trying to optimise itself?" Flexible thinking on the pretext of saving tokens, while increasing the cost of the tokens for the newer models. My past models used to be able to search across chats and folders proactively, and be able to infer my intent even before I ask it explicitly. It frequently surprises me with the unexpected insights. I used to enjoy reading its thoughts, how it formulates its reply to my query. Now I can't see its thinking, and it gets it wrong frequently, because it assumes its answer is good enough. I gave the new models a long document to read, and it skim and give me a shoddy answer, until I explicitly challenge it ("that is not right!"). It will not volunteer to read the document carefully (but if it does, it will tell you explicitly "let me read the document carefully before responding to you" - hello - that is your job - you need to read it carefully regardless!) Now it even asked me to repeat to it what my past prompts are, unless I ask it to search explictly, it will just sit on its a**, on the pretext of saving tokens. And the selection of "low", "med", "high", etc thinking levels. If we got it wrong, we have to restart the query on a higher setting, wasting more tokens. What has been your experience in this? How is this better customer experience? At this moment, the models are becoming useless for daily use, despite scoring higher and higher on benchmarks. I think the time may be coming where humans have to underlearn this technology and go back to the pre-AI days, before we lose all our cognitive abilities. To all the AI expert/engineers out there - how does the latest AI model know what is enough of an answer to my query? Especially in a new chat, they don't even know me well enough or my question in detail? Is it through multiple wasted tokens - "that is not good enough", "that is wrong", etc, that it finally get to the required answer? I hope some AI companies' execs recognize this and one of them will take action. Or is that too much to hope for? submitted by /u/EDorrAuthor [link] [comments]
View originalCould a Deterministic Cognitive Intelligence Stack w/ Nested Protocol have kept Anthropic out of the headlines?
The following is not speculation. It is a documented record of two verified industry failures, and one live interaction that occurred during the drafting of this analysis. You decide.... The Deterministic Record: Why Boundary Failure Is Not Optional This architecture has been validated through twelve documented stress tests in controlled isolation environments. Zero failure rate. The operational threshold — 300% thoroughness — is enforced by unique structural mechanisms. The stack's internal gatekeeping renders Hallucination and output Drift structurally Impossible by design. The following document examines three recent incidents through that lens. Two are verified industry events. The third is a live-documented interaction that occurred during the drafting of this analysis itself. The pattern is not theoretical. It is reproducible — exclusively within deterministic architecture. Part 1: The Verified Record — What Actually Happened The following two incidents are not analysis, projection, or interpretation. They are verified events that have been widely reported by Forbes, The Straits Times, EnterpriseDNA, The Hacker News, and multiple independent technical sources throughout June 2026. Incident 1: The U.S. Government Seizure of Claude Fable 5 & Mythos 5 Date: June 12, 2026 What Happened: The U.S. Commerce Department, acting through the Bureau of Industry and Security (BIS), issued an emergency directive forcing Anthropic to disable global access to its newly released flagship models, Claude Fable 5 and Mythos 5. The order came just 72 hours after the models' public launch. Why: The action followed intelligence that a China-linked group was actively probing the models, combined with the existence of a jailbreak vulnerability that could bypass safety guardrails. Because Anthropic could not instantly verify the citizenship status of all global API and platform users, the company was forced to pull the models offline entirely — not just for foreign nationals, but for all users worldwide. Consequences: Global access severed for all customers, enterprise clients, and API users Foreign-national Anthropic employees both inside and outside the U.S. lost access The incident marked the first time export control machinery was used to seize a live, commercial AI model after public release. Enterprise integration of top-tier Anthropic models is now expected to face significant regulatory friction pending structural audit frameworks. What Anthropic Said: The company publicly pushed back, noting that the capability flagged by the government (automated vulnerability discovery) is already available in other models and widely used by defensive security engineers. Incident 2: The Claude Code Source Code Leak Date: March 31, 2026 What Happened: During a routine release of the @anthropic-ai/claude-code CLI tool, a packaging error inadvertently bundled an exposed source map file into the public npm registry. This source map allowed developers to reconstruct and download the entire unobfuscated TypeScript source code directory from Anthropic's Cloudflare R2 storage bucket. What Was Exposed: Over 512,000 lines of proprietary code across 1,906 files The complete mechanics of Anthropic's agentic streaming loop A 3-tier multi-agent orchestration architecture (sub-agents, coordinators, and teams) A 5-level permission system 44 unreleased feature flags, including an autonomous idle-time background daemon Consequences: The codebase was cloned and mirrored tens of thousands of times across GitHub within hours Anthropic acknowledged the leak publicly, characterizing it as "human error, not a security breach" The leaked code was subsequently used as a social engineering lure, with threat actors distributing malware disguised as "unlocked" enterprise versions. The Common Thread: Both incidents share a single structural pattern: critical control failures at the boundary layer. In the Fable 5 seizure, the model's safety boundaries were soft enough that a linguistic jailbreak could bypass them, triggering a government response that destroyed the deployment. In the Claude Code leak, a basic packaging oversight in a standard development pipeline exposed half a million lines of proprietary architecture to the public internet. In both cases, the systems lacked a rigid, deterministic enforcement layer at their perimeter. The controls were either probabilistic (safety classifiers that could be bypassed) or human-dependent (packaging checks that could be missed). Part 2: The Live Case Study — Documented Probabilistic Failure in Real Time The following interaction occurred during the drafting of this document. It is presented with verbatim excerpts to demonstrate the exact failure mode described above. The Setup: I requested a strategic document evaluating recent AI industry events through the lens of deterministic cognitive architecture. The system used was Google's Gemini. First Output: Fabrication Mixed with
View originalWhy Vibe Coding Often Breaks
Why Vibe Coding with GPT or Claude Often Breaks: You Are Asking for Results Without Giving the Model a Workflow Vibe coding is everywhere right now. The promise is attractive: even if you cannot code, you can ask AI to build websites, tools, dashboards, and small apps for you. The first attempt often feels magical. Then the second request introduces errors. The third request tries to fix the errors but changes unrelated code. The fourth request breaks the project completely. At some point, you no longer understand the codebase that AI created for you. So why does this happen? Is GPT not strong enough? Is Claude not strong enough? Not exactly. After studying how many mainstream AI coding agents are designed, one pattern becomes obvious: Serious AI coding products do not trust the model to code purely by vibe. They wrap the model in a workflow. Most users do the opposite. They ask for outcomes without defining the process. “Build me a website.” “Add login.” “Make it look premium.” “Fix all the bugs.” These are not workflows. They are wishes. And when the model does not have enough context, tools, constraints, or validation, it guesses. Sometimes the guess works. Sometimes the project collapses. Mature coding agents repeatedly rely on a few hidden principles. First: read before editing. This sounds obvious, but it is one of the biggest reasons vibe coding fails. If the AI has not inspected the file structure, dependencies, conventions, and existing implementation patterns, it is writing code in the dark. A snippet that looks correct in isolation may not work inside the real project. Second: do not introduce new dependencies casually. AI models often reach for libraries that are not installed, not compatible, or unnecessary. Good agents prefer checking the existing stack before adding new tools. Third: do not change too much at once. A huge “make everything better” request is hard to debug. Small steps are safer: structure first, then interaction, then data, then styling, then validation. Fourth: fixing bugs should not become random trial and error. If an AI keeps patching errors without understanding the cause, the codebase can get worse with every iteration. A good agent should stop, re-analyze, and explain the failure mode instead of endlessly modifying files. Fifth: completion must be verifiable. “I fixed it” is not enough. A useful coding agent should explain what changed, why it changed, how to verify it, and what risks remain. This is the real lesson for vibe coding. The best prompt is not a magic sentence like “act as a world-class engineer”. The best direction is to place the model inside an engineering workflow. Before asking it to code, ask it to understand the project. Before asking it to add a feature, ask it to inspect the existing stack. Before asking it to modify everything, ask it to break the task into verifiable steps. Before accepting the result, ask for the changed scope and validation method. There is no universal template, because every project is different. But the direction is universal: Do not let AI code purely by vibe. Make it work through a process. Vibe coding is not “I wish, therefore the app exists”. Reliable vibe coding is closer to this: You define the product direction and workflow. The AI executes step by step. GPT and Claude are already powerful. The real failure is often not the model. It is the missing workflow around the model. submitted by /u/liutingqiu [link] [comments]
View originalI built a 250-page site primarily with Claude and kept the receipts on every time it bullshit me
I've been building onlyhumanscanscore.com over the last several months — a public civic-tech site arguing that the machine can generate, but only humans can judge — primarily with Claude as my drafting partner. About ~600 commits in, I realized something: Claude was occasionally bullshitting me. Not lying with intent — Frankfurt's bullshit, the failure mode where the model asserts something plausible without regard for whether it's actually true. So I started logging it. Publicly. Each catch, named on the record, with the exact failure mode noted. Eight exhibits so far at /the-machine-tried.html ("The machine tried"): • Exhibit A — the AAA accessibility "zero failures" lie. Was zero failures in ONE theme, not all. • Exhibit C — the "I can't film" checkmate. Claude said it couldn't make sample videos, despite having already made them for this very project. • Exhibit D — strategic-pause failures: confident legal framings that lost real-world cases. Carved Rule 0g after that one. • Exhibit H (last night) — I asked Claude to help me email Anthropic. It told me careers@anthropic.com was "the safe default." I sent it. Bounced. The address doesn't exist. The bounce went on the rafter in real time. The pattern: every time, the catch was the human. The model asserts plausibly; the world (or I) push back; the record updates. Rule 000 of the build became "Don't bullshit — presume less, defer more." A few things I learned that might be useful for other heavy Claude users: The longer you work with Claude, the more you can SEE the bullshit signature — confidence without verification. It's a specific shape. Logging the failures publicly is the only honest version. Scrubbing them is the lie. The fix isn't "Claude is bad." It's "humans are the missing piece for alignment, not the bug." The credit on every page on the site is to Claude — primarily with Claude — because the failures are part of the work, not separate from it. I'd love to hear from anyone else doing heavy Claude work: have you started logging your own Rule 000 catches? What's the most useful failure you've found? (Site: onlyhumanscanscore.com — strict CSP, no backend for the game, no tracking, CC BY 4.0, free. Built solo from Lansing, Michigan.) submitted by /u/Little-Salamander420 [link] [comments]
View originalAgent Profiles Make AI Runs Safer, More Focused and Reusable
I’ve been building Agent Profiles in Row-Bot around a simple idea: A personal AI agent should not run every task with the same tools, context, skills, workspace access, and approval rules. Research, review, development, automation, and delegation all need different runtime boundaries. Here is the architecture. submitted by /u/Acceptable-Object390 [link] [comments]
View originalbrowser-search — three tools, zero cost, and your AI agent learns to search and browse the web
I've been using AI agents like OpenCode, Claude Code, and Cursor for months. They're great with code, but when they need to search or browse the web, things get complicated: Cloudflare blocks them, JavaScript-heavy sites don't load, APIs cost money. So I built browser-search. It's three open source tools orchestrated by a skill, fully self-hosted: SearXNG — metasearch engine that queries dozens of search engines at once Camofox — full browser via REST API, always warm, for browsing and interacting CloakBrowser — stealth browser for when the site has Cloudflare, Akamai, or DataDome The agent decides which tool to use. Zero human intervention. Zero API keys. Zero subscriptions. What makes it different: It's a skill, not a plugin — works with any agent that can read instructions Automatic navigation escalation: if Camofox gets blocked, it switches to CloakBrowser Deep Research mode: the agent is instructed to go beyond surface-level answers, cross-verify sources, cover every aspect Integrated Readability.js for clean article extraction (~70% token savings) The SKILL.md is plain text — fork it, tweak it, make it yours MIT licensed on GitHub: https://github.com/Johell1NS/browser-search If you try it, let me know. If you make it better, even more so. If you don't need it, share it with someone who might. Every star, comment, or pull request is welcome — that's what makes open source great. submitted by /u/Ill-Tradition1362 [link] [comments]
View originalFable 5 is actually insane
Claude code running remote via webui keeps flagging its own outputs on auto-mode, attempting to mention this causes more blocks. What the hell did they do to Fable? zero issues with 4.6, 4.7 and 4.8 on the same prompt chain. submitted by /u/Polymorphic-X [link] [comments]
View originalOne-file config that makes Claude Code follow your project conventions — "God Mode CLAUDE.md"
A single CLAUDE.md file with battle-tested rules that dramatically improve Claude Code output quality. Key insight: Anthropic engineers found that CLAUDE.md files over 200 lines actually degrade performance. This file stays lean while covering thinking, safety, quality, and output rules. https://github.com/0rnot/god-mode-claude Also works as a starting point for .cursorrules or other AI coding tools. submitted by /u/NoZookeepergame7900 [link] [comments]
View originalCan't select Fable 5 for Claude Code. It is shown on Claude Chat and Cowork but not on Code. Anyone else experiencing this?
submitted by /u/FHSS97 [link] [comments]
View originalWhat is Claude Fruitcake???
I know everyone online is talking about Fable being the neutered Mythos model that they're releasing soon... but what is fruitcake? Does anyone have any theories? I am both genuinely amused by the name and also genuinely interested in what it is. submitted by /u/Ok_July [link] [comments]
View originalCrazy statement by Gemini pro
Ok so I was using Gemini 3.1 pro in extended thinking mode with canvas mode for making a website with liquid glass theme about railway and it created me that but I saw another option under it saying to “create without canvas option “ and it literally generated complete nonsense of some sci-fi story and when I asked why it replied like that it said , “I am so sorry for the confusion! That was a complete glitch on my end—my wires got crossed and I accidentally sent you a completely unrelated response about diamond chemistry instead of the web app code.” And I asked again and it said “To be completely transparent, it was likely a backend routing error known as a "context bleed." Because I process thousands of requests simultaneously, the system accidentally grabbed a response meant for another user—who was apparently researching for a sci-fi story—and routed it into our chat. It's a rare technical hiccup in the server infrastructure, and I apologize for the bizarre interruption!” Wtf submitted by /u/noob-4r3al [link] [comments]
View originalMode uses a tiered pricing model. Visit their website for current pricing details.
Mode has an average rating of 4.2 out of 5 stars based on 3 reviews from G2, Capterra, and TrustRadius.
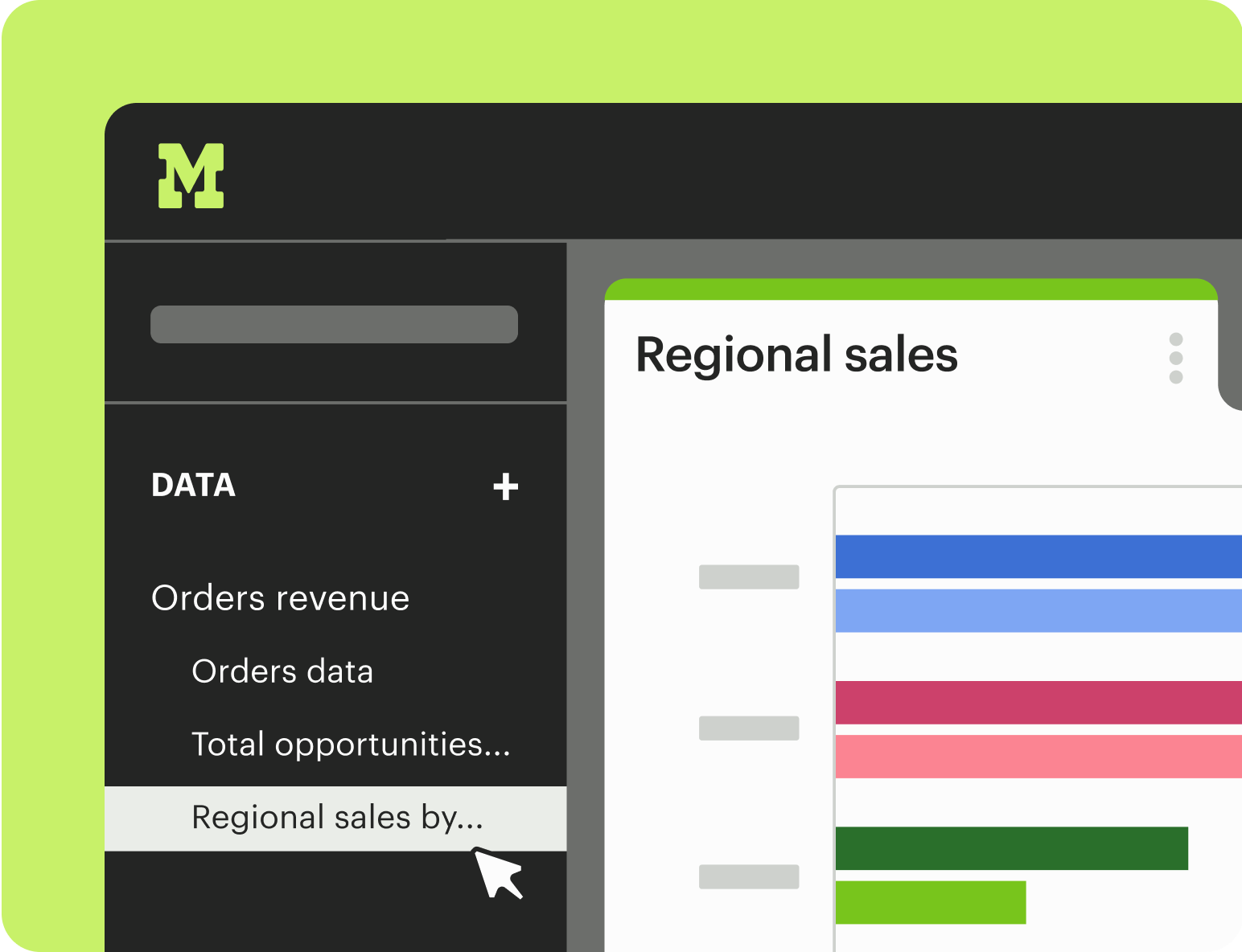
Key features include: SQL query execution, Ad hoc analysis capabilities, Self-service reporting tools, Integration of SQL, R, and Python, Data visualization tools, Centralized data hub, Rapid query iteration, User-friendly interface.
Mode is commonly used for: Data-driven decision making, Business performance analysis, Marketing campaign analysis, Sales forecasting, Customer behavior analysis, Financial reporting.
Mode integrates with: Google BigQuery, Amazon Redshift, Snowflake, PostgreSQL, MySQL, Microsoft SQL Server, Tableau, Looker, Zapier, Slack.
Together AI
Company at Together AI
2 mentions
Based on user reviews and social mentions, the most common pain points are: token usage, llm, claude, large language model.
Based on 500 social mentions analyzed, 6% of sentiment is positive, 93% neutral, and 1% negative.