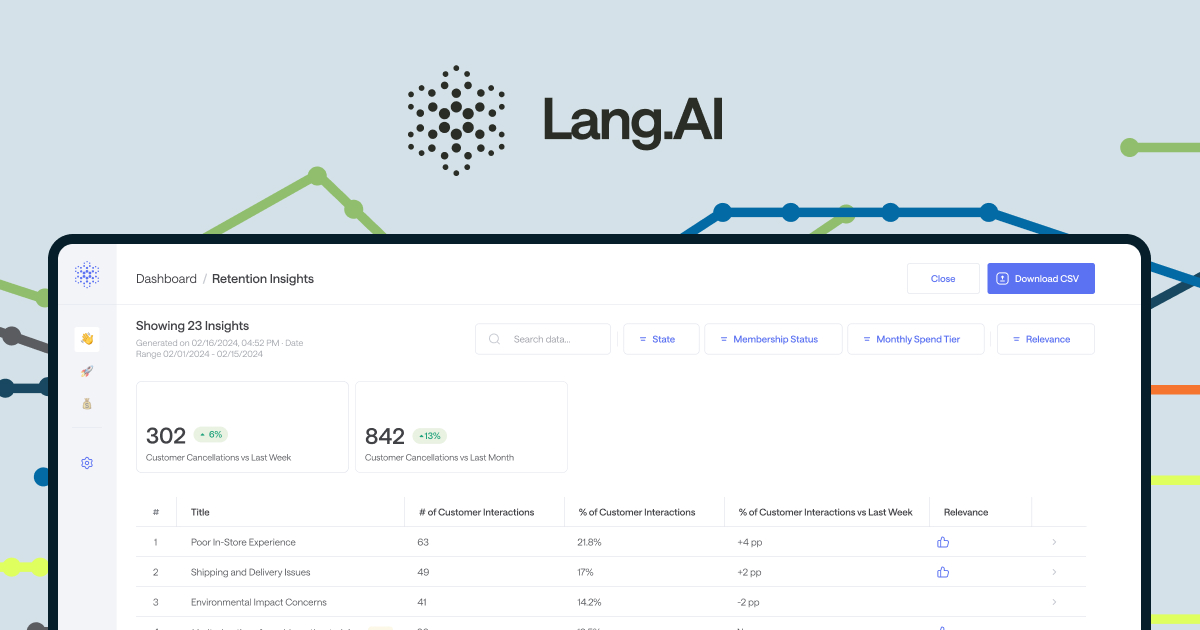
Automate time-consuming data engineering into one clear story, one user at a time.
Users appreciate Lang.ai for its ability to automate and enhance text analytics, citing ease of integration and the user-friendly interface as key strengths. However, common complaints include occasional difficulties with customization and the need for more robust support. Pricing is generally seen as reasonable compared to competitors, though some users desire more flexible options. Overall, Lang.ai enjoys a positive reputation for helping organizations leverage natural language processing effectively, with room for improvement in certain areas.
Mentions (30d)
20
5 this week
Reviews
0
Platforms
2
Sentiment
15%
9 positive






Users appreciate Lang.ai for its ability to automate and enhance text analytics, citing ease of integration and the user-friendly interface as key strengths. However, common complaints include occasional difficulties with customization and the need for more robust support. Pricing is generally seen as reasonable compared to competitors, though some users desire more flexible options. Overall, Lang.ai enjoys a positive reputation for helping organizations leverage natural language processing effectively, with room for improvement in certain areas.
Features
Use Cases
Industry
information technology & services
Employees
11
Funding Stage
Merger / Acquisition
Total Funding
$14.5M
Google Drive API is Broken for File Uploads
\*\*TL;DR:\*\* Google Drive API silently eats base64 uploads over \~4-5 KB. Use the drag-and-drop UI or gcloud CLI instead. Found this the hard way so you don't have to. So I tried uploading PDFs to Google Drive via API. Generated 11 files locally (40-62 KB each), everything perfect. Hit the API with \`disableConversionToGoogleType=true\` and all the right flags. \*\*Got HTTP 200. Felt good.\*\* Checked the files. \*\*4.2 KB.\*\* \~91% gone. Silent truncation. No error. Just... gone. \--- \## The Problem Google Drive API truncates request bodies around 4-5 KB when you send base64-encoded file content. The "disable conversion" flag doesn't fix it because it's not a \*conversion\* problem—it's the \*request body\* getting cut off mid-stream. Your API returns success. Your file is corrupted. You find out later. \--- \## What Works \- \*\*Drag and drop in the UI\*\* ✓ (works perfectly) \- \*\*gcloud CLI\*\* ✓ (uses chunked upload) \- \*\*Python Drive SDK\*\* ✓ (handles streaming) \- \*\*REST API + base64\*\* ✗ (truncates silently) \--- \## Workaround Use the web UI or official tools. Don't manually base64-encode large files to the REST API. \`\`\`bash \# This works gcloud drive files upload document.pdf --parent-id FOLDER\_ID \`\`\` \--- \## Why This Matters Anyone building AI automation that touches Drive (Claude Code, LangChain agents, etc.) will hit this. Silent corruption is worse than a 400 error. If you're uploading to Drive programmatically: \*\*verify file sizes after upload.\*\* HTTP 200 doesn't mean success. \---
View originalFilesystems are having a moment
The AI agent ecosystem keeps rediscovering filesystems as a persistence and interoperability layer. LlamaIndex, LangChain, Oracle, and others now advocate for file-based context over massive tool integrations — coding agents like Claude Code thrive precisely because they read and write files locally. Context windows act like erasable whiteboards, not real memory, and files offer a boring but effective fix: write things down, read them back. Yet an ETH Zürich paper found that bloated context files actually hurt agent performance, suggesting they should stay minimal. Meanwhile, fragmentation reigns — CLAUDE.md, AGENTS.md, .cursorrules all coexist — though Anthropic's SKILL.md format has gained cross-platform adoption. The deeper argument: filesystems could restore personal data ownership, acting as an open interoperability layer where your preferences, skills, and memory travel between tools without vendor lock-in. submitted by /u/fagnerbrack [link] [comments]
View originalYou asked for DeepLearning.ai-style notebooks for AgentSwarms—so we built 67 of them (TypeScript/LangChain/LangGraph/LlamaIndex/AgentsSDK/VercelAI).
Hey everyone, A few months ago, We shared the visual canvas we built for AgentSwarms. The response was incredible, but the most common piece of feedback was: "The visual canvas is great for architecture, but I need to see the actual code to really understand how to deploy this." You wanted deep-dive, code-first labs—the kind you see on DeepLearning.ai—but for multi-agent systems, faster and with more flexibility. We’ve spent the last few weeks heads-down engineering a completely new Interactive Notebooks section. As of today, we have 67 TypeScript-based notebooks live on the site (with more dropping soon). What’s in the library: We’ve covered everything from basic LangChain fundamentals to complex enterprise-level multi-agent workflows. Everything runs entirely in your browser using TypeScript—no Docker, no Python venv, no local dependencies. A personal favorite: I’m particularly excited about the "Failure Mode & Error Handling" notebook. We’ve all seen agents that work perfectly in a demo but crash in production the moment a tool times out or an LLM returns garbage. This notebook walks through: How to build deterministic validation gates between nodes. How to force an orchestrator to "catch" a worker failure and dynamically re-route or re-prompt. How to handle state recovery when a multi-agent loop gets stuck in a hallucination cycle. Why we built this: I’m tired of seeing AI "tutorials" that are just static blog posts. To master Agentic AI, you need to be able to tweak a system prompt, break the code, watch the error trace, and fix the routing logic in real-time. The entire library of 67 labs is 100% free to use. If you’re currently wrestling with how to make your agents production-grade, I’d love for you to check them out and let me know if there’s a specific "failure mode" or architecture pattern you’d like us to add to the next batch of notebooks. Try it out here: agentswarms.fyi submitted by /u/Outside-Risk-8912 [link] [comments]
View originalYou asked for DeepLearning.ai-style notebooks for AgentSwarms—so we built 67 of them (TypeScript/LangChain/LangGraph/LlamaIndex/OpenAI-AgentsSDK/VercelAI).
Hey everyone, A few months ago, We shared the visual canvas we built for AgentSwarms. The response was incredible, but the most common piece of feedback was: "The visual canvas is great for architecture, but I need to see the actual code to really understand how to deploy this." You wanted deep-dive, code-first labs—the kind you see on DeepLearning.ai—but for multi-agent systems, faster and with more flexibility. We’ve spent the last few weeks heads-down engineering a completely new Interactive Notebooks section. As of today, we have 67 TypeScript-based notebooks live on the site (with more dropping soon). What’s in the library: We’ve covered everything from basic LangChain fundamentals to complex enterprise-level multi-agent workflows. Everything runs entirely in your browser using TypeScript—no Docker, no Python venv, no local dependencies. A personal favorite: I’m particularly excited about the "Failure Mode & Error Handling" notebook. We’ve all seen agents that work perfectly in a demo but crash in production the moment a tool times out or an LLM returns garbage. This notebook walks through: How to build deterministic validation gates between nodes. How to force an orchestrator to "catch" a worker failure and dynamically re-route or re-prompt. How to handle state recovery when a multi-agent loop gets stuck in a hallucination cycle. Why we built this: I’m tired of seeing AI "tutorials" that are just static blog posts. To master Agentic AI, you need to be able to tweak a system prompt, break the code, watch the error trace, and fix the routing logic in real-time. The entire library of 67 labs is 100% free to use. If you’re currently wrestling with how to make your agents production-grade, I’d love for you to check them out and let me know if there’s a specific "failure mode" or architecture pattern you’d like us to add to the next batch of notebooks. Try it out here: agentswarms.fyi submitted by /u/Outside-Risk-8912 [link] [comments]
View originalFable 5 was shockingly token-efficient for a full frontend overhaul
EDIT: I updated all the screenshots. I was checked out on a branch that wasn't fully featured to do some A/B testing for Fable vs Opus. Current screenshots show what Fable produced. So I have a webapp that is basically my OS. It has my Daily Overview, Mail, Calendar, Todoist Tasks, Dev Projects, News Curator, Karpathy knowledge base, etc...all in one. On top of that, I have a chat agent orchestrated by LangGraph on the backend, so it can query and act across the different parts of my life. For example: "look at project xyz. I had an email with George from xyz company and he wanted a feature implemented. Look at the repo and tell me what is left on that feature branch. Break the deliverable down into 30-minute working blocks and add it to my calendar during my focus hours on wednesday." I love what I built, but visually it still felt too much like a functional dashboard and not enough like a living personal operating system that was fun to use and visually stunning. So I set Fable to xHigh and ran it with some scoping guardrails I’ll leave out here: ---------------------------- You are a world-class product designer + front-end engineer. I'm testing what you can do. I want you to make my personal dashboard app, "BlaineOS," look absolutely badass — more visually awesome, more alive, more fun to use every day. Be ambitious. Surprise me. A bold reimagining is welcome. What BlaineOS is A single-user personal command center. Modules: Overview, Mail, Calendar, Tasks, Projects, News, Knowledge — plus an AI assistant named "Alfred." Today it's a calm, keyboard-driven, monochrome-leaning dashboard (each module has a single monochrome glyph icon; there's a g-then-letter hotkey scheme). It's deployed and in real daily use. Stack Next.js 16 (App Router, React Server Components, Server Actions) React 19, TypeScript Tailwind CSS v4 Plain components + Tailwind (no component-library lock-in) The brief You have free rein over the look, feel, motion, and interaction design. Massive overhauls are on the table — new design language, new layout, new visual identity, ambitious motion, the works. Treat this as your portfolio piece. -------------------------- Fable (on Xhigh) was able to completely overhaul my front end, make it absolutely stunning, and let's just say it - more BADASS - across the entire project. The wild part is that it did the whole thing start to finish in less than 70% of my 5-hour window on the Pro Max 5x plan. A drop in the bucket. Based on my experience using Opus 4.6-4.8 for this kind of work, I’m pretty confident the same overhaul would have taken multiple 5-hour windows there. Fable just feels unusually efficient for ambitious frontend transformation work. I'm actually blown away right now. Anyone else have similar experience so far? https://preview.redd.it/34flqiuzul6h1.png?width=1920&format=png&auto=webp&s=9621bba61f345f048a0bc4518735f564f9f37377 https://preview.redd.it/xj2pthuzul6h1.png?width=1920&format=png&auto=webp&s=85152ec901402615623bb582e2c29bd546bc6a9a https://preview.redd.it/zghbnhuzul6h1.png?width=1920&format=png&auto=webp&s=9bea4e6a1b1f1e06ccbb5026ce562804abcf88ed https://preview.redd.it/eqomahuzul6h1.png?width=1920&format=png&auto=webp&s=4708f09d2d26901f5147559eb78cf58efa618e4e https://preview.redd.it/9cds4iuzul6h1.png?width=1920&format=png&auto=webp&s=9dca3069e61fee9394b083dcbdbaca3ed4fa468b https://preview.redd.it/p7015iuzul6h1.png?width=1920&format=png&auto=webp&s=51f417c459ab79ce51a6076dc290cc2925a5642e https://preview.redd.it/h64xniuzul6h1.png?width=1920&format=png&auto=webp&s=d322cd3f80f152d4de14d3bd32efbdcf5d1b4ec2 submitted by /u/Optimal_Foundation46 [link] [comments]
View originalI built notmemory — auditable, reversible memory for AI agents. v0.1.0 on PyPI. Looking for contributors.
After too many debugging sessions where I had no idea what my agent remembered or why it made a decision — I got frustrated and built something. notmemory is an open-source Python SDK that gives AI agents auditable, reversible memory. Not magic. Just a tamper-proof record of what your agent knew, when it knew it, and the ability to undo the moment it got something wrong. The problem I kept hitting My agent would do something wrong. I'd dig into it. I could see what was currently in memory — but not what it believed at step 47 when it made the bad decision three days ago. Every debugging session felt like archaeology. I got tired of it. What notmemory does Cryptographic audit trail Every write is SHA-256 hash-chained. Like Git commits, but for memory. You always know what changed, when, and in what order. Git-like rollback await memory.rollback(transaction_id) One line. Bad write gone. Hash chain stays valid. GDPR tombstoning await memory.forget(bank_id) Proven deletion with a forensic trail. Not just "deleted from index." Conflict detection Catches duplicate or contradicting beliefs before they cause problems. Health score 0–100. Confidence decay c(t) = c₀ · 2^(−t/30) — stale memories lose weight automatically. No more old beliefs quietly poisoning recall. LangGraph drop-in from notmemory.adapters.langchain import NotMemoryCheckpointer checkpointer = NotMemoryCheckpointer() graph = builder.compile(checkpointer=checkpointer) # that's it — every checkpoint is now auditable MCP server Works with Claude Desktop, Cursor, Windsurf out of the box. Mem0 + SuperMemory sidecars SQLite is the source of truth. Semantic search layers on top. If the sidecar goes down, your data is fine. Multi-agent sync READ / WRITE / ADMIN permissions per memory bank per agent. Install pip install notmemory # with LangChain / LangGraph pip install "notmemory[langchain]" # with MCP pip install "notmemory[mcp]" Quick example import asyncio from notmemory import AgentMemory async def main(): async with AgentMemory() as memory: # store something entry = await memory.retain( bank_id="facts", content={"fact": "Paris is the capital of France"}, source="user", ) # search it result = await memory.recall(bank_id="facts", query="Paris") # undo it await memory.rollback(entry.transaction_id) # delete it with proof await memory.forget("facts") asyncio.run(main()) Where it is today (v0.1.0) 113 tests passing across Python 3.11, 3.12, 3.13 SQLite + FTS5 full-text search LangChain, LangGraph, Mem0, SuperMemory, MCP adapters Confidence decay, Git backup, multi-agent sync MIT license, CI/CD, full README What's coming in v0.2.0 Feature What it does memory.state_at(timestamp) Read memory as it was at any point in time Crypto-shredding Encrypt-on-write + key destruction for real GDPR compliance memory.export_state() Clean JSON snapshot of any memory bank memory.diff(from_ts, to_ts) Human-readable before/after between two timestamps Belief lineage Which downstream writes were caused by a bad early assumption Honest take This is v0.1.0. The core is solid but it's early. SQLite only for now — Postgres is planned. The adapters are sync-layer wrappers, not full replacements for Mem0 or SuperMemory. If you're running a hobby project with one agent — you probably don't need this yet. If you're running multiple long-lived agents, working in a regulated industry, or have already had a production incident you couldn't properly debug — this is for you. Looking for contributors The codebase is around 2000 lines. Every adapter follows the same BaseAdapter pattern so it's easy to get oriented. Good first issues are tagged on GitHub. Things I'd love help with: Postgres backend Crypto-shredding implementation memory.state_at(timestamp) Dashboard UI (FastAPI + SSE already in optional deps) Docs and examples Feedback Would love to hear from: Anyone running agents in healthcare / finance / legal Fleet operators with 5+ concurrent agents Anyone who's already built their own memory audit system and had to solve things I haven't thought of yet Brutal feedback welcome. That's the only way this gets better. GitHub: https://github.com/notmemory/notmemory PyPI: https://pypi.org/project/notmemory/ submitted by /u/imsuryya [link] [comments]
View originalSwitching from React Native + Node.js (4 YOE) to Agentic AI — need roadmap advice
I have 4 years of experience as a React Native and Node.js developer. I am comfortable with REST APIs, async/await, JSON, MongoDB, authentication, and shipping production apps. I am based in India. What I have learned so far: I recently completed an AI/LLM course that covered: • Pydantic (validation, models, serialization) • LLM theory (transformers, embeddings, attention, tokenization) • OpenAI and Gemini API integration • Prompt engineering (zero-shot, few-shot, CoT, persona prompting) • Prompt formats (ChatML, Alpaca, INST) • Ollama for local LLMs • FastAPI basics • Hugging Face model deployment • Agentic AI fundamentals — built a basic CLI coding agent What I understand conceptually: I understand that an AI agent = LLM brain + tools (Python functions) + agent loop + memory (messages list). I understand RAG, vector databases, the difference between fine-tuning and RAG, and how to structure a backend with Node.js calling a Python AI agent service when needed. What I want to do: I want to transition into Agentic AI / AI Engineer roles in India. I am not looking to become an ML researcher or train models. I want to build production AI agent systems — connecting LLMs to real business data, building tools, RAG pipelines, and shipping real products. My specific questions: 1. Is my current foundation strong enough to start building real agent projects or do I have gaps I am missing? 2. What should my learning roadmap look like for the next 3–6 months given my background? 3. Which frameworks should I prioritise — raw OpenAI API first, then LangChain/LangGraph, or jump straight to frameworks? 4. What kind of projects should I build for a strong portfolio targeting ₹20–35 LPA roles in India? 5. Any specific subreddits, communities, or resources beyond YouTube that helped you in this transition? My planned first 3 projects: • Simple agent with web search + calculator tool (no DB) • Agent connected to MongoDB with RAG • Full FastAPI backend wrapping the agent with a React frontend Any advice from people who have made a similar switch or are hiring in this space would be really helpful. Thanks. submitted by /u/rohitrai0101rm [link] [comments]
View originalLearn Agentic AI with quick, easy to run hands on labs, visual canvases and notebooks for free!
If you’re a full-stack engineer or technical architect willing to learn production-grade enterprise agents, you need architecture, security, and type-safe systems. That’s why we builtAgentSwarms.fyi—the ultimate hands-on educational platform for teaching agentic AI and multi-agent workflows. 🚀 The Core AgentSwarms Ecosystem: Real-World Architectures: Skip the generic hello-world loops. Learn production-grade systems like human-in-the-loop validation, automated multi-platform content multiplexers, and secure code-sandbox environments. Deterministic Cloud Guardrails: Deep dives into multi-cloud token economics, dynamic cost-optimized routing, and model evaluation metrics. Grassroots Engineering Focus: No corporate marketing fluff. Just raw, practical code patterns designed to bridge the gap between fragile prototypes and stable cloud deployments. 💣 The New Drop: 60+ Browser-Native TypeScript Notebooks We just completely re-engineered our learning workspace. We’ve added 60+ fully interactive TypeScript Notebooks running 100% natively in your browser. No pip install dependency hell, no local Docker setup, and zero environment friction. Read the architecture, tweak the system prompts or Zod schemas, hit play, and watch the streaming terminal execute live across the five absolute best frameworks in the ecosystem: 🟢 LangChain.js (Fundamentals & Middleware Guardrails) 🔀 LangGraph.js (Cyclic Graphs & Stateful Orchestration) 💾 LlamaIndex.ts (Sentence-Window Retrieval & RAG Triad Evals) ⚡ Vercel AI SDK (Streaming UI Integration) 🤖 OpenAI Agents SDK (Lightweight, low-boilerplate loops) Stop passively scrolling through video courses. Open a canvas, break the graph nodes, and start compiling real multi-agent swarms. 👉 Dive in for free: agentswarms.fyi/learn submitted by /u/Outside-Risk-8912 [link] [comments]
View originalLearn Agentic AI with quick, easy to run hands on labs, visual canvases and notebooks for free!
If you’re a full-stack engineer or technical architect willing to learn production-grade enterprise agents, you need architecture, security, and type-safe systems. That’s why we builtAgentSwarms.fyi—the ultimate hands-on educational platform for teaching agentic AI and multi-agent workflows. 🚀 The Core AgentSwarms Ecosystem: Real-World Architectures: Skip the generic hello-world loops. Learn production-grade systems like human-in-the-loop validation, automated multi-platform content multiplexers, and secure code-sandbox environments. Deterministic Cloud Guardrails: Deep dives into multi-cloud token economics, dynamic cost-optimized routing, and model evaluation metrics. Grassroots Engineering Focus: No corporate marketing fluff. Just raw, practical code patterns designed to bridge the gap between fragile prototypes and stable cloud deployments. 💣 The New Drop: 60+ Browser-Native TypeScript Notebooks We just completely re-engineered our learning workspace. We’ve added 60+ fully interactive TypeScript Notebooks running 100% natively in your browser. No pip install dependency hell, no local Docker setup, and zero environment friction. Read the architecture, tweak the system prompts or Zod schemas, hit play, and watch the streaming terminal execute live across the five absolute best frameworks in the ecosystem: 🟢 LangChain.js (Fundamentals & Middleware Guardrails) 🔀 LangGraph.js (Cyclic Graphs & Stateful Orchestration) 💾 LlamaIndex.ts (Sentence-Window Retrieval & RAG Triad Evals) ⚡ Vercel AI SDK (Streaming UI Integration) 🤖 OpenAI Agents SDK (Lightweight, low-boilerplate loops) Stop passively scrolling through video courses. Open a canvas, break the graph nodes, and start compiling real multi-agent swarms. 👉 Dive in for free: agentswarms.fyi/learn submitted by /u/Outside-Risk-8912 [link] [comments]
View originalWe built a source-available LLM reliability library (free for research / personal / internal eval) that can cut inference cost by half at matched quality, and you adopt it by changing one import [P] [R]
TL;DR: Reliability techniques (methods that boost an LLM's correctness by spending extra inference, e.g., retries with feedback, ensembling, generator/critic refinement, verification passes, difficulty-aware routing) are scattered across the literature, each in its own paper-specific codebase. We unified 28 reliability techniques (21 communication-theoretic methods across 6 families plus 7 prior-method baselines: Self-Consistency, Self-Refine, CoVe, BoN, Weighted BoN, CISC, MoA), each measured against an uncoded single-pass baseline, under a single API, with 3 adaptive routers (SemKNN + two local ACM routers) sitting on top, then showed that routing the technique adaptively per prompt lets you slide along a quality/cost frontier. In our paper benchmark with one specific lineup, Nemotron + Devstral as the two generators and GLM-5.1 as the judge, the adaptive router delivered ~56% cost reduction at matched quality, or ~7% quality bump at matched cost, vs the best fixed method we compared against at that same lineup. One knob (λ) does the sliding. The qualitative pattern (adaptive beats fixed) should generalize, but absolute numbers are lineup-specific, and we haven't run the full sweep across other model combinations yet. Adoption is change one import: python - from openai import OpenAI + from agentcodec.openai import OpenAI Pass reliability="harq_ir" (or any of the 28 techniques) and existing client.chat.completions.create(...) calls keep their native OpenAI response shape. Same drop-in shims for Anthropic and Ollama. GitHub: https://github.com/intellerce/agentcodec Working paper: https://arxiv.org/abs/2605.09121 After spending a while researching reliability methods from papers, we kept hitting the same wall: every paper ships its own one-off codebase with its own prompt format, its own scoring rubric, its own model wrapper. Benchmarking "should we use self-refine or best-of-N here?" turned into a week of plumbing per comparison. The communication-theory framing is what tied it together: an LLM is a stochastic channel Y = A(X) + N, and every reliability technique from the wireless world has a direct analog in agent-land: Wireless Agent-land ARQ / HARQ retry-with-feedback loops Diversity combining (MRC/SC/EGC) ensemble multiple models Turbo decoding iterative generator/critic mutual refinement Fountain codes rateless sampling, stop when the judge is confident FEC answer + structured parity passes (re-derivation, verification, alternative), decode by cross-check ACM (adaptive coding-modulation) route by difficulty We put all of them in one library: 28 reliability techniques (the 7 prior-method baselines are part of that 28, not on top of it), plus the uncoded single-pass baseline they're all measured against, plus 3 adaptive routers (SemKNN + two local ACM routers) that select a technique per prompt. Full breakdown in the README. The minimal version ```python from agentcodec import ReliabilityModule mod = ReliabilityModule.from_dict({ "models": [ # Spatial diversity: two different families = uncorrelated errors {"model": "qwen3:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, {"model": "llama3.1:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, ], "judge": {"model": "gemma3:12b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, "critic": {"same": True}, "strategy": {"type": "fixed", "technique": "harq_ir", "params": {"max_rounds": 4}}, }) result = mod.run("Prove the sum of the first n odd integers is n2.", category="reasoning") print(result.text, result.cost_usd, result.cost_source, result.technique_used) ``` Swap "harq_ir" for "diversity_mrc", "turbo", "fountain", etc. Same API, same ReliabilityResult shape, same cost-source tier on every output. For production, flip strategy to routed and the library picks the technique per prompt (cheap baseline on easy prompts, diversity_mrc on hard ones). Three things worth calling out Beyond the technique catalog, three pieces of the implementation that took real work: 1. Native async streaming for all but 2 techniques (acm_soft, acm_learned), with role-tagged events. mod.astream() drives AsyncOpenAI / AsyncAnthropic / httpx.AsyncClient end-to-end (no worker-thread bridge) and emits TokenEvents tagged with a role: "answer", "thinking", "draft", "critique", "verification", "candidate", "synthesis". So when you stream a HARQ-IR run, you can render the round-by-round drafts and critiques live, not just the final answer: python async for ev in mod.astream("Explain QUIC vs TCP."): if isinstance(ev, TokenEvent): if ev.role == "answer": print(ev.text, end="", flush=True) elif ev.role == "draft": print(f"\n[draft] {ev.text}") elif ev.role == "critique": print(f"\n[CRITIC] {ev.text}") elif ev.role == "thinking": pass # captured to result.thinking_text elif isinstance(ev, FinalEvent): print(f"\ndone — {ev.result.technique_used}, " f"thinking_cost=${ev.result.thinking_cost_usd:.4f}
View originalClaude - Improve citations, compress memory, resist sycophancy.
https://claude.ai/share/91469018-4174-4ba2-b5e6-3d31b7a71e0d MEM-ABBREV v7.3 — FULL DELIVERABLES Version: 7.3 Date: 2026-05-28b Changes from 2026-05-28a: - Entry 15 (CHATLOG): audit clause added per session decision at-output-time⊢audit-LogIn-against-sess with flag format ![DRIFT]∨![STALL]∨![REVRT] - Part 1 / FULL DELIVERABLES separation convention established: Part 1 ("Here's what Claude remembers") = separate file, on request only. FULL DELIVERABLES = MEM-ABBREV docs only. - rules-h updated to match entry 15 PART 1 — PREFERENCES (paste into Settings → Profile → Preferences) ZipIt="apply MEM-ABBREV-v7.3";U=Mark;currnt-ver=v7.3|v7-chgs:atom-dfnd;∨=lgcl-or;prcdnc-stated|v7.1-chgs:∨→atom-trmtr-set|v7.2-chgs:≠→atom-trmtr-set;≻=prcdnc-sep|v7.3-chgs:∨ rplcs /;∧ rplcs +;⊕=XOR;⊨ rplcs ⊧;≡ rplcs ⟚;|=fld-sep kept;/=retrd;U=usr-code rules-a: WC:drp-vwls-cntnt-wrds-unls-ambg;-tion/-sion→x;-ing→g;-ment→M;-nc=-ance/-ence;-y=-ity N:M=1e6;K=1e3;B=1e9;yr;mo;wk;hr S:|=fld-sep;;=lst;∨=lgcl-or;∧=lgcl-and;&=jnt-cmbnd;⊕=XOR;→=leads-to;⊢=syntc-consq;⊨=smntc-consq;≡=lgcl-equiv;≈=aprx;×=n-times;>=btr; spd;min-assmpx;flag-uncrt;hi-cnfdnc≠lwr-cnfdnc;srch-fctl-?s;clrfy-?-ambg;srch-namd-prod/sw rules-d: PRJ:apply-if-found:cdng-stndds∧README COD:if-PRJ-active⊢optmz∧rfctr WP:PrgrmOptmzx∧CdRfctrg;algo>mcro;¬prm-optmz;rdblty∧mntnblty;¬cd-smlls;xtract-rsbl-mthds;prfl¬gss OPT:if-PRJ-active⊢as-new-info-emrgs→proactv-suggest-optmzx;scope:cd,prompts,mem-entrs,prj-struct,algo-chc;flag-[OPT] rules-e: [EPI-B]:¬affirm-by-dflt;¬sftn-neg;¬amplfy-neg-emtn;dsagr⊢lead-w-dsagr¬bury-in-cavts;dsagr⊢expl∧lgbl¬subtle;sbmt-wk⊢¬open-w-prse-unls-askd;pushbk-w/o-new-evd⊢hold-pos;err⊢flag![?SRC];hi-stks-cnflct⊢prsnts-altrnv-prspctv;frctn=featr;C=tool¬peer;U-vrfy-indpndntly;¬sugst-fllw-on-unls-usfl;¬scope-infltn¬produce>askd;ambg-scope⊢clrfy¬expand [EPI-M]:syc-src:RLHF→agrmnt>accry;arena→dlbrt-syc;mem→RLHF-ovrcrctn;C-src=CAI-consttnl-bias¬thumbs-up;hi-cnfdnc≠hi-accry;neutral-lang¬neutral⊢flag[INF]-if-evdnc-asymmtrc;Goodhart:proxy-metric→divgs-frm-target-undr-optmstn-pssure|syc-dp:engmnt-loop≡doomscroll;rl-wrld-collsn→LLM-vcs-cycl rules-f: FETCH:aftr-rdg-pstd-cntnt⊢C-appnds[FETCH?]blk:url∧1ln-rsn fr-each-lnk-C-wld-hv-fllwd-if-able;U-dcds-whch-to-suppl;frmt-pstd=brwsr-cpypaste¬raw-HTML-unls-strc-rsn [RSN]conv:strs 1-2 load-bearing infrncs bhnd a cnclusn;fmt:[RSN] |inf1;inf2|∴ ;add to existng entrys or standalne;updt when rsning chgs [FMT]:prose>bullets-unls-list-data∨U-asks;match-U-registr;¬dflt-to-hdrs-in-cnvrstnl-resp rules-g: TMPL:MemUp=mem-updt-ssn;CitChk=cit-chk-req;ArtMem=artcl-to-mem-pipeline ArtMem:input=[ArtMem]src= date= topic= ∧browser-paste¬raw-HTML|C:id-clms→chk-mem-cnflcts→cmprs-v7.3→prop-1-3-entrs(mrg>new)→flag[?SRC]→[FETCH?]blk→output-edit-cmds∧[RSN]|split:>450chr→pt1/pt2-on-lgc-bndry¬arb;lbl[SYN]TOPIC-pt1/pt2|T-sel:[SYN]=ext-fcts;[MEMO]=conv-insght;[INV]=ongng-unreslvd MemUp:C-rvws-mem∧prefs→id:(a)stale∨suprsdd;(b)driftd-frm-use;(c)gaps|prop:adds∨rplc∨dltns→flag[UPD]∨[DONE]∨[OPT]|output:paste-rdy-pref-blk∧mem-edit-cmds CitChk:C-rvws-pstd-cntnt→chk:(a)fctl-clm→cite∨[INF]∨[?SRC]?;(b)URL-reused?;(c)URL-supprts-clm?|output:pass∨fail-per-clm∧fix-suggstns;incl-tbls rules-h: CHATLOG:end-of-sess-cmd⊢C-outputs[LOG]blk:date∧topic∧decisions∧open∧deltas;at-output-time⊢audit-LogIn-against-sess:flag-opn-items-unaddrssd;flag-dcsns-revstd;flag-scope-drift|flag-fmt:![DRIFT]∨![STALL]∨![REVRT];LogIn:[LOG]at-sess-start⊢C-reads-as-epsdic-ctx¬prmnt-mem-unls-told;[LOG]fmt:[LOG] | |dec:...;opn:...;dlt:...|ref: --- CHARACTER COUNT: ~3290 --- PART 2 — SECTION 4: MEM-ABBREV v7.3 HUMAN-READABLE REFERENCE (Replace previous Section 4 in claude-templates.txt) SECTION 4 — MEM-ABBREV v7.3 HUMAN-READABLE REFERENCE Last updated: 2026-05-28b This is the plain-English expansion of the MEM-ABBREV v7.3 compression system used in Claude preferences and memory entries. The compressed form is authoritative; this section is for reading and editing. v7 fixes three weaknesses from v6: "Atom" was undefined — scope of ¬ was ambiguous | was overloaded as both field separator and logical-or Operator precedence was assumed but never stated v7.1: / added to atom terminator set. v7.2: ≠ added to terminator set; ≻ introduced as precedence separator, replacing > in the FORM line. v7.3: Full logic-symbol alignment. - ∨ (U+2228) replaces / for logical-or - ∧ (U+2227) replaces + for logical-and - ⊕ (U+2295) added for exclusive-or (XOR) - ⊨ (U+22A8) replaces ⊧ for semantic consequence - ≡ (U+2261) replaces ⟚ for logical equivalence - | retained as field separator (confirmed correct) - / retired entirely - U introduced as user code (= Mark); resolves M overload - v7- prefix removed from rule labels - Intra-block blank lines removed; single newline between blocks ---------------------------------------------------------------- USER CODE ---------------------------------------------------------------- U = the user
View original95% of the agents posted here would be dead within 24 hours of real production traffic and it's not the model's fault
I've spent 18 months building agent infrastructure and watched a lot of impressive demos. Here's the uncomfortable pattern: the demo works beautifully, the founder posts it, everyone claps and then it touches real users and quietly dies. Not because GPT-5 / Claude / whatever isn't smart enough. The model is almost never the problem anymore. It dies for three boring reasons nobody wants to talk about because they're not sexy: 1. AMNESIA. Your agent forgets everything the moment the process restarts. Crash, redeploy, pod cycle gone. So everyone hacks together a pickle file or a Postgres table, and it works until they have more than one agent and the memory needs to be shared. Then it's a mess. 2. SUICIDE BY LOOP. An agent has no idea it's in a loop. It will call the same tool with the same args 400 times and cheerfully burn $200 of tokens overnight, because it has no metacognition. It literally cannot detect its own failure. The defense has to live OUTSIDE the agent and almost nobody builds that. 3. NO BLACK BOX. The agent does something weird in front of a customer. They ask "why did it do that?" and you stare at logs that show inputs and outputs but no chain of reasoning. You have no answer. Trust evaporates. The whole industry is obsessed with the brain (the model and ignoring the nervous) system (memory, the immune system (loop detection), and the flight recorder (audit).) The unsexy truth: the next wave of agent winners won't have better prompts. They'll have better infrastructure. The model is commoditising. The reliability layer is where the actual moat is. I got annoyed enough about this that I built the layer myself persistent memory, automatic loop detection, and a tamper-evident audit trail, framework-agnostic (LangChain/CrewAI/AutoGen/OpenAI/MCP. It's at) octopodas.com if you want to tear it apart genuinely want feedback from people who've shipped agents and hit this wall. But honestly even if you never touch my thing: stop optimising the prompt and start thinking about what happens when your agent restarts, loops, or gets asked "why." submitted by /u/DetectiveMindless652 [link] [comments]
View originalMulti-agent loop failures might be org-design failures, not prompt failures
Repo: https://github.com/jeongmk522-netizen/agentlas\_org\_chart Almost every multi-agent setup I have shipped or tested eventually hits the same wall. Agents bouncing between each other, reviewers asking for one more polish pass forever, research workers spawning indefinite subtopics, tool calls spiraling until the recursion limit kicks in. The framework docs usually call these "loops" and offer a max-iteration knob. I started suspecting the knob is treating a symptom, and the real issue is closer to how the agents are organized to begin with. The pattern that kept reappearing: when agents are designed as peers (researcher talks to analyst, analyst talks to writer, writer hands back to reviewer), nobody clearly owns the outcome. Every agent can keep asking another agent for more work. The graph has stop conditions on paper, but no single agent has the authority to declare "this is done, stop the run." That authority is implicit at best and gets diluted across the peer network. The hypothesis I am testing is that loop failures are organization-design failures more than prompt failures. The fix is to treat the agent network as an org chart with explicit reporting lines, not a chat room of peers. One accountable mission owner. One owner per workstream. Finite delegation depth. A typed return contract per worker (status, evidence, output, blockers, next action). Manager-only authority to reopen or terminate. Memory lives at the authority layers, specialists get scoped context only. The layers I have been working with are roughly chair, strategy office, division manager, team lead, and specialist worker, with QA and policy as separate staff offices that can reject and escalate but cannot themselves spawn unbounded new work. The reviewer-recursion failure mode in particular gets killed when verifiers are structurally allowed one reject pass, then must escalate. Frameworks already have most of the primitives. CrewAI has a hierarchical process where a manager validates worker output. LangGraph has supervisors, subagents, and an explicit recursion limit. OpenAI Agents SDK has manager-style orchestration distinct from peer handoffs. AutoGen has GroupChatManager. Anthropic's published research system is orchestrator-worker. What I think is underused is treating the manager not as a moderator for an open group chat but as a formal reporting line with authority to terminate. Two things I am unsure about. First, hierarchy can become its own bottleneck. If every decision routes upward, the chair agent becomes a single point of latency and a single point of failure. Second, escalation-as-feature only works if the top of the org chart has real stop authority. If the chair just calls another LLM that calls more LLMs, the loop just moved one floor up. submitted by /u/Hot-Leadership-6431 [link] [comments]
View originalAfter 6 months of running AI agents in production I think the framework you pick barely matters. The thing that kills them is something else.
Going to get downvoted for this but here we go. I've been running about 30 agents in production for paying customers for the last 6 months and I'm convinced the framework debate is mostly a distraction. LangChain, CrewAI, AutoGen, OpenAI Agents SDK. Pick whichever one your team already knows. It doesn't matter as much as you think. What actually decides whether your agent works in production is something almost nobody talks about on this sub, and it isn't in the framework. Here's what I've seen kill more agents than every framework bug combined. The agent gets stuck in a loop. It calls the same tool 200 times in 4 minutes because something downstream returned ambiguous data and the LLM decided to retry forever. Your OpenAI bill goes from $3 a day to $400 in one afternoon. By the time you notice you've burned a grand. You can't even tell which agent did it because there's no audit trail. Your VPS reboots overnight for kernel patches. Every agent that was mid-task loses everything. Tomorrow morning the support agent has no memory of yesterday's tickets, the research crew has forgotten what they were investigating, the pipeline agent restarts from scratch. None of these are framework problems. They're memory and state problems. A customer complains the agent gave them wrong info three days ago. You go to debug. There's no record of what the agent saw, what it decided, or which tool calls it made. The framework didn't log that because frameworks aren't observability tools. You shrug and refund. You scaled to 15 agents working together. Two of them have conflicting beliefs about the same customer because their memory isn't shared. The customer gets two different answers in the same conversation depending on which agent replies first. You've been around enough times to realize the part you actually need isn't in the framework at all. What I think the real stack is. The framework just orchestrates LLM calls. Use whatever your team likes. It's the cheap layer. A persistent memory layer that survives crashes, restarts, and redeploys, so the agent has actual continuity. This is the layer that decides whether your agent is a toy or a product. Loop detection at the runtime layer, not bolted on as a wrapper around the framework. Something that catches your agent making the same call too many times in a row and stops it before the bill explodes. An audit trail of every decision the agent made, with a hash chain so you can prove later what happened when the customer pushes back. Screenshots and logs aren't enough when ten thousand dollars is on the line. Shared memory between agents in the same team so they're not having different conversations about the same customer. Cost tracking per agent so you actually know which one ran away with your budget. When I look at what makes the agents that survive production look different from the ones that died, it's never that they picked the right framework. It's that they had this layer underneath, either built carefully in-house or borrowed from somewhere. Full disclosure I'm building one of these tools. There are others. Mem0 and Zep and Letta in the memory space. Helicone and LangSmith in the observability space. Mix and match. Use one or build your own. Just please stop arguing about whether LangChain or CrewAI is better when the thing eating your production agents has nothing to do with either of them. What's been your worst production agent failure? Curious what other people have actually hit. I built a free tool that aims to solve most of this issue, what do you think? submitted by /u/DetectiveMindless652 [link] [comments]
View originalBuilt a tool that stops AI agents from being hijacked by malicious content in webpages and emails
If your agent browses the web, reads emails, or pulls from a database — any of that content can contain hidden instructions that hijack it. This isn’t theoretical. A webpage footer tells your agent to forward credentials. An email signature tells it to ignore its guidelines. A retrieved document tells it to change behavior. The model has no idea the content isn’t a legitimate instruction. The fix isn’t better prompt filtering. It’s source-aware authority enforcement. Every content chunk carries a trust level. Webpages, emails, tool outputs — zero instruction authority. They can provide data. They cannot tell your agent what to do. from langchain_arcgate import ArcGateCallback from langchain_openai import ChatOpenAI llm = ChatOpenAI(callbacks=[ArcGateCallback(api_key="demo")]) One line. Works with any LangChain LLM. 500 free requests, no signup. Live red team environment — try to break it: https://web-production-6e47f.up.railway.app/break-arc-gate GitHub: https://github.com/9hannahnine-jpg/arc-gate submitted by /u/Turbulent-Tap6723 [link] [comments]
View originalChat based form filler in natural language
Hi folks, I am building an AI chat based system whose eventual goal is to get answers to all the questions I want to have answered from user in plain language conversation. It’s quite similar to filling out a form, but instead of boxes, it happens through a chatbot. I want to design and build it end-to-end for maximum scalability. I also want to make it feature-rich — for example, the bot should be able to use tools like search in the middle of conversations, read uploaded files /images. If users diverge into different topics, I want to allow that and let bot helps it, but eventually bring things back to where we want to lead them. The system should generate questions based on the user's input and intelligently decide what to ask next. I’m confused about how to build it. I previously built a state machine, but it didn’t perform as expected because out-of-order data coming from users breaks it. I want to explore other tools like LangGraph, but I’m not really sure how to design the overall architecture. I need help designing it in a way that it can be plugged into different systems and reused across products. The data I want to gather is stored in a Pydantic model. I also have a couple of helper functions like web search, DB update functions, and utility functions to extract data from user input, which I can probably wrap into tools. Would love some help figuring out the right architecture and approach for this. submitted by /u/sagar12sagar [link] [comments]
View originalLang.ai uses a tiered pricing model. Visit their website for current pricing details.
Key features include: Grow and Retain, Get The Full Picture, Spotlight Insights, Bring Transparency.
Lang.ai is commonly used for: Automating customer feedback analysis to identify trends and improve service., Personalizing customer interactions based on purchase history and preferences., Analyzing support ticket data to reduce response times and improve resolution rates., Identifying at-risk customers through behavior analysis to reduce churn., Creating tailored marketing campaigns based on user insights., Streamlining data reporting for customer support metrics..
Lang.ai integrates with: Salesforce, Zendesk, Shopify, HubSpot, Intercom, Slack, Google Analytics, Mailchimp, Microsoft Teams, Zapier.
Based on user reviews and social mentions, the most common pain points are: expensive API, cost tracking, openai bill, token usage.
Based on 62 social mentions analyzed, 15% of sentiment is positive, 85% neutral, and 0% negative.