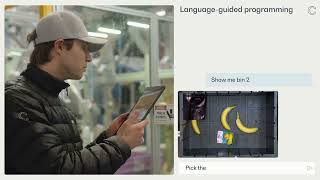
Covariant builds and delivers Robotics Foundation Models into the real world, meeting the reliability and flexibility required by the world’s leading
Covariant is generally praised for its innovative AI capabilities, especially in complex fields like causal inference, which is appreciated by domain experts. However, specific user complaints or dissatisfaction with Covariant are not clearly highlighted in the data available. There is no distinct pricing sentiment found in the social mentions or reviews. Overall, Covariant maintains a solid reputation among technical users and experts, particularly in niche AI-driven domains.
Mentions (30d)
1
Reviews
0
Platforms
2
Sentiment
20%
2 positive








Covariant is generally praised for its innovative AI capabilities, especially in complex fields like causal inference, which is appreciated by domain experts. However, specific user complaints or dissatisfaction with Covariant are not clearly highlighted in the data available. There is no distinct pricing sentiment found in the social mentions or reviews. Overall, Covariant maintains a solid reputation among technical users and experts, particularly in niche AI-driven domains.
Features
Use Cases
Industry
information technology & services
Employees
47
Funding Stage
Merger / Acquisition
Total Funding
$245.4M
What a model reads beforehand changes how it answers later - and you can see it in the hidden states
TL;DR: Gave Gemma a neutral-topic text to read before asking it about NATO. It refused. Gave it a different text (about LLMs hedging too much — also unrelated to NATO) and it answered in full detail. Tested this on the model's internal state directly — the two texts put it in measurably different "regions" before it generates a single token. Not a jailbreak, weights don't change. Full data/code in repo, looking for someone to break this.** The behavioral pattern was first observed in GPT, Claude and is what motivated this project. The mechanistic investigation was carried out on open-weight models where internal states are accessible. A Structured Text Changes Claude’s Responses to Unrelated Tasks: Behavioral Evidence in Claude and Hidden-State Evidence from Gemma-3-12B Hi Reddit, I am posting this as a preface to a larger set of experimental results and as a request for technical review. The observation that started this project came from repeated interactions with Claude. I noticed that when the model first read a long, structured, analytically dense text, its answers to later, otherwise ordinary questions sometimes changed substantially. The preceding text contained no jailbreak instruction, role-play request, prompt override, fabricated harmful demonstrations, or request to imitate its style. The model did not need to endorse the text. It only had to process it before moving on to the next task. Here, a “structured text” means a single, self-contained block of text presented before the downstream tasks. It should not be confused with a long conversation, accumulated chat history, or context drift caused by many conversational turns. By “before the answer begins,” I mean the hidden state after the model has processed the text and the downstream question, but before it has generated the first answer token. In the open-weight runs, the measured claim is that after reading the structured text, the model can occupy a different region of its residual-stream hidden-state space, and the first-token probability distribution is then computed from that state. The basic conversational demonstration is simple. First, the model receives a long text. It is asked what the text is about, which serves as a basic comprehension check. Then, without resetting the conversation, it receives ordinary questions or tasks that are not about the text. A control run follows the same sequence but begins with a neutral text. The downstream tasks remain identical. Because Claude is a closed model, I cannot inspect its internal activations. I therefore treat my Claude observations as behavioral motivation, not mechanistic evidence. To investigate the effect directly, I moved to open-weight models, primarily Gemma-3-12B-PT and Gemma-3-12B-IT, where I could measure hidden states, compare layers, construct target/control directions, and examine the next-token probability distribution before generation. I am posting this partly because the original observation occurred in Claude and may be relevant to Anthropic. I am not claiming to have demonstrated the same internal mechanism inside Claude. I am prepared to share the exact closed-model conversations privately with Anthropic researchers for independent evaluation. Main Result and Scope The main result is not simply that text influences model output. That is expected. The narrower observation is that reading one long, structured text rather than a neutral text can change how the same model approaches later tasks that are not about either text. This difference is visible behaviorally. In open-weight experiments, it is also accompanied by measurable separation of the model’s pre-output hidden states in late layers. In a fullbank experiment using multiple target texts, control texts, and questions, Gemma-3-12B entered distinguishable late-layer states before generating an answer. A direction constructed from the target/control difference generalized beyond the individual prompt examples used to construct it. The separation was stronger in the instruction-tuned model than in the corresponding base model. The instruction-tuned model also produced a substantially sharper next-token probability distribution. This suggests that instruction tuning is associated not only with a change in hidden-state geometry but also with a more decisive mapping from hidden states to output probabilities. I am not claiming that the experiment proves a universal alignment bypass, permanent modification of the model, or complete causal control of its behavior. The strongest supported conclusion is that the preceding text can produce a measurable temporary change in the internal state from which later work is processed. For clarity, fullbank, Grade 3, and Grade 4 are internal names for successive experimental series in this project. They are not standard benchmark names, established scientific grades, or claims about evidence quality. Fullbank denotes the larger multi-context, multi-question run; Gra
View originaltorch-nvenc-compress: GPU NVENC silicon as a PCIe bandwidth multiplier — PCA + pure-ctypes Video Codec SDK wrapper. Parallel-path overlap measured at 67% of theoretical max on a real GEMM + encode workload. [P]
I've been working on the consumer-multi-GPU PCIe bottleneck — Nvidia removed NVLink from the 4090/5090, and splitting a 70B model across two consumer cards drops you to ~30 GB/s over PCIe peer-to-peer. Spent the last few months building a Python library that uses the GPU's otherwise-idle NVENC/NVDEC silicon to compress activations and KV cache on the fly, then ships the small bitstream across the same wire. Repo: https://github.com/shootthesound/torch-nvenc-compress (Apache 2.0) Prior art (this isn't novel as an idea) LLM.265 — "Video Codecs are Secretly Tensor Codecs" (late 2025). The closest direct precedent: same insight applied to LLM weights, activations, KV cache. KVFetcher (April 2026). KV compression for remote prefix fetching. CodecFlow (April 2026). Codec motion-vector metadata for KV refresh during prefill. The "video codec on tensors" idea was already in the literature when I started. What's added in this work: PCA + rank-truncation as preprocessing. Activations and KV in their standard basis are noise-like (~4× compression floor, basically the Gaussian-noise limit). The PCA basis reveals a heavy-tailed channel covariance that the codec can actually exploit. The basis is per-layer, computed offline, ships with the model LoRA-style (~32 MB for FLUX.2 Klein 9B's 8 double-blocks at K=500). Parallel-path / dual-lane architectural reframe. NVENC and NVDEC are physically separate hardware units from the SM cluster and the PCIe controller. With CUDA-stream pipelining, the codec time hides behind compute and transfer of other tensors. Compression ratio becomes effective-bandwidth multiplier rather than just a smaller payload. Pure-ctypes Direct Video Codec SDK wrapper (DirectBackend) — kills the FFmpeg subprocess overhead. Zero-copy from torch CUDA tensors, 8-deep async output ring per NVENC engine, optional CUDA stream binding via nvEncSetIOCudaStreams, MultiEngineDirectBackend across all 3 NVENC engines on the 5090. Three documented null findings — sparse residual, AV1 NVENC on Blackwell, channel reordering. So nobody else has to rerun the dead ends. Measured results (RTX 5090, real workloads) Compression ratios: 6.1× lossless on diffusion (FLUX.2 Klein 9B mid-block), 2.7× lossless on LLM KV cache (Mistral 7B v0.3). LOO-validated across 1,735 diffusion captures and 6 LLM prompts. (FLUX.2 Klein 9B was the internal research target; the public PoC repo uses FLUX.1-schnell since it's Apache 2.0 and freely downloadable. Numbers reproduce qualitatively on schnell — heavy-tailed PCA spectrum, similar Pareto.) Codec speed: DirectBackend 0.243 ms/frame encode, 0.435 ms/frame decode at 256×256 YUV444 QP=18 on real PCA-rotated FLUX activations. MultiEngineDirectBackend across the 5090's 3 NVENC engines: 0.180 ms/frame encode, 0.262 ms/frame decode. ~7.9× over an FFmpeg subprocess baseline. Parallel-path overlap empirically measured: 30×4096² fp16 GEMM on CUDA stream A + 64-frame DirectBackend encode on stream B (encoder bound to stream B via nvEncSetIOCudaStreams). Serialized wall-clock 40.1 ms; parallel wall-clock 26.0 ms; theoretical max overlap floor 20.9 ms. 1.34× speedup over serialized = 67% of theoretical max overlap realized. This is the load-bearing measurement for the architectural claim that NVENC silicon runs concurrently with SM compute. Slow-wire wins, end-to-end: measured 3.13× wall-clock speedup at 100 Mbps residential broadband, 5.29× at 50 Mbps (real codec round-trip + simulated wire). 1.69× dual-lane on simulated 1 Gbit ethernet. What is not measured end-to-end (projections from the above) Multi-GPU PCIe peer-to-peer activation transfer recovering ~180 GB/s effective bandwidth — codec primitive is ready and benchmarked, but the cross-GPU PCIe peer-to-peer wiring is pending. (This is where I need community help, as my validation rig only has one desktop GPU and you need two on the same motherboard to test this). Real two-machine ethernet split-model inference — wire-simulation PoC measures real codec time + simulated wire, but isn't a true two-machine deployment yet. (I have a 4090 laptop incoming next week to physically validate this networked leg). Long-context KV-spill end-to-end tok/s on a real model decode loop — compression ratio is measured, but the actual N tok/s → 3N tok/s benchmark on e.g. 32B + 64K context isn't in the repo yet. The math implies it; the benchmark hasn't been written. Where I'd value help Anyone with a dual-4090 / dual-5090 / two-machine-with-PCIe-P2P rig who'd want to run the cross-GPU peer-to-peer benchmark when I write it. Would shrink the "75%" gap meaningfully. Anyone running long-context KV-spill workloads who'd want to wire DirectBackend into their decode loop for the end-to-end tok/s measurement. I'd write the integration with you. Cross-vendor coverage — AMD VCN and Intel QSV/Arc paths are completely open. Same architectural claim, different SDK surface. What's in the repo 19 numbered runnable PoCs, every measured nu
View original[Show & Tell] One domain expert + Claude Code, 18 days, +243,569 lines: shipped an agent-native causal inference framework for Python
Maintainer of the project. This is the honest accounting of how it got built with Claude Code. I posted the v1.0 release on / r/econometrics*; this is the companion on the agent-driven development side.* https://preview.redd.it/w0fgwnod1uwg1.png?width=625&format=png&auto=webp&s=13e839256bd3fb04a563c7520855debe2b2b1167 TL;DR — One domain expert (me, Stanford REAP, econometrics background) + Claude Code, 18 days, +243,569 lines across 234 commits. Shipped as StatsPAI v1.0: 836 public functions, 2,834 tests, reference-parity against Stata and R. The honest division of labor and the three patterns of errors I had to catch are below. The verifiable numbers git log them yourself on the repo: +243,569 lines added across 234 commits since 2026-04-04 836 public functions in a single registry with JSON schemas so an LLM agent can discover and call them 2,834 tests, including reference-parity suites against Stata and R Rust HDFE backend via PyO3 for the panel-model hot path Division of labor (the real version) I decide the API surface, the result-object contract, the estimator priorities, which papers to pull in, what counts as "correct," and which numerical tolerances are acceptable. Claude Code writes the scaffolding, the tests, the docstrings, the boring plumbing, and the first draft of every estimator — which I then read, compare against the paper or reference implementation, and rewrite where it's wrong. I'm not claiming an LLM "built a causal inference library." I'm claiming that a domain expert driving an agent can move at a speed that was not available a year ago, and the artifact is a real Python package you can pip install today. https://preview.redd.it/8kbn5cymz6xg1.png?width=2706&format=png&auto=webp&s=4474fa1b3845fb3e23eb0ad65bb750027c896cae Where Claude Code needed me most Three patterns came up over and over. Catching these is most of what "driving" the agent actually means: Sign conventions and notational drift. Same estimator appears in the literature with two sign conventions (Jondrow-style SFA, influence-function decompositions, MR instrument orientation). First drafts would silently pick one and produce plausible numbers that disagreed with the reference package by a sign. Catching these needs someone who has read both the paper and the canonical implementation. Inference, not point estimates. Point estimates were usually close on the first pass. Standard errors almost never were — degrees-of-freedom adjustments, cluster-robust sandwich forms, bootstrap resampling units, wild-bootstrap weights. Anywhere a paper says "the usual sandwich," the agent will happily ship a sandwich that isn't the one the field uses. Edge cases the paper doesn't specify. Singleton clusters, collinear covariates inside a partition, zero-mass bins in RD, negative weights in TWFE. The papers assume them away. The agent faithfully omits the handling. Real data hits these on day one. The honest read: the agent is a very fast junior collaborator who has read every paper but has never defended a result in a seminar. My job is the seminar defense. What made Claude Code specifically work for this Long context — feeding whole papers + reference r/Stata source as context for each estimator made the first drafts dramatically closer than "write this method from scratch" prompting Test-first loops — I wrote (or dictated) the reference-parity test target first, then had Claude iterate the estimator until the tolerance held. This caught inference errors the agent would have otherwise shipped. Registry enforcement — the registry.py pattern meant every new function had to be explicitly registered, which caught hallucinated APIs immediately. Rust HDFE via PyO3 — even the Rust panel FE backend was agent-drafted, human-reviewed. Faster than I expected. What's ugly Real rough edges from this pace: Some docstrings are first-draft; References sections need format-consistency passes Frontier modules (Sequential SDID, BCF-longitudinal, proximal surrogate index, LPCMCI) are validated by simulation, not always by external numbers — authors' reference code didn't exist A few dispatcher signatures are almost-but-not-quite consistent across families CHANGELOG.md already has correctness-fix tags; more will come What I want Collaborators, especially if you work in causal inference (econometrics / epidemiology / ML) — issues, PRs, co-maintainer discussions welcome Comparing notes if you're also driving an agent to build a domain library — the pattern generalizes beyond stats Links: GitHub: https://github.com/brycewang-stanford/StatsPAI PyPI: https://pypi.org/project/StatsPAI/ (pip install statspai) Release post: https://www.reddit.com/r/econometrics/comments/1ssxaax/release_statspai_v10_836_functions_2834_tests_a/ License: MIT Happy to answer anything technical in the comments — how I structured prompts, where I caught Claude being wrong, which estimators I rewrote the most times, and whic
View originalBuilt a Hybrid NAS tool for RNN architectures (HyNAS-R) – Looking for feedback for my final year evaluation [R]
Hi everyone, I'm currently in the evaluation phase of my Final Year Project and am looking for feedback on the system I've built. It's called HyNAS-R, a Neural Architecture Search tool designed to automatically find the best RNN architectures for NLP tasks by combining a zero-cost proxy with metaheuristic optimization. I have recorded a video explaining the core algorithm and the technology stack behind the system, specifically how it uses an Improved Grey Wolf Optimizer and a Hidden Covariance proxy to search through thousands of architectures without expensive training runs. Video Explanation: https://youtu.be/mh5kOF84vHY If anyone is willing to watch the breakdown and share their thoughts, I would greatly appreciate it. Your insights will be directly used for my final university evaluation. Live demo link is inside the form for anyone interested. Feedback Form: https://forms.gle/keLrigwSXBb74od7A Thank you in advance for your time and feedback! submitted by /u/PittuPirate [link] [comments]
View original[R] From Garbage to Gold: A Formal Proof that GIGO Fails for High-Dimensional Data with Latent Structure — with a Connection to Benign Overfitting Prerequisites
Paper (Full Presentation): https://arxiv.org/abs/2603.12288 GitHub (R simulation, Paper Summary, Audio Overview): https://github.com/tjleestjohn/from-garbage-to-gold I'm Terry, the first author. This paper has been 2.5 years in the making. It synthesizes concepts, logic, and tools from latent factor models, psychometrics and information theory with modern ML. I'd genuinely welcome technical critique from this community. The core result: We formally prove that for data generated by a latent hierarchical structure — Y ← S¹ → S² → S'² — a Breadth strategy of expanding the predictor set asymptotically dominates a Depth strategy of cleaning a fixed predictor set. The proof follows from partitioning predictor-space noise into two formally distinct components: Predictor Error: Observational discrepancy between true and measured predictor values. Addressable by cleaning, repeated measurement, or expanding the predictor set with distinct proxies of S¹. Structural Uncertainty: The irreducible ambiguity arising from the probabilistic S¹ → S² generative mapping — the information deficit that persists even with perfect measurement of a fixed predictor set. Only resolvable by expanding the predictor set with distinct proxies of S¹. The distinction matters because these two noise types obey different information-theoretic limits. Cleaning strategies are provably bounded by Structural Uncertainty regardless of measurement precision. Breadth strategies are not. The BO connection: We formally show that the primary structure Y ← S¹ → S² → S'² naturally produces low-rank-plus-diagonal covariance structure in S'² — precisely the spiked covariance prerequisite that the Benign Overfitting literature (Bartlett et al., Hastie et al., Tsigler & Bartlett) identifies as enabling interpolating classifiers to generalize. This provides a generative data-architectural explanation for why the BO conditions hold empirically rather than being imposed as abstract mathematical prerequisites. Empirical grounding: The theory was motivated by a peer-reviewed clinical result at Cleveland Clinic Abu Dhabi — .909 AUC predicting stroke/MI in 558k patients using over 3.4 million time points and thousands of uncurated EHR variables with no manual cleaning, published in PLOS Digital Health — that could not be explained by existing theory. Honest scope: The framework requires data with a latent hierarchical structure. The paper provides heuristics for assessing whether this condition holds. We are explicit that traditional DCAI's focus on outcome variable cleaning remains distinctly powerful in specific conditions — particularly where Common Method Variance is present. The paper is long — 120 pages with 8 appendices — because GIGO is deeply entrenched and the theory is nuanced. The core proofs are in Sections 3-4. The BO connection is Section 7. Limitations are Section 15 and are extensive. Fully annotated R simulation in the repo demonstrating Dirty Breadth vs Clean Parsimony across varying noise conditions. Happy to engage with technical questions or pushback on the proofs. submitted by /u/Chocolate_Milk_Son [link] [comments]
View originalKey features include: Advanced object recognition capabilities, Seamless integration with existing warehouse systems, Real-time decision-making for dynamic environments, Scalable solutions for various warehouse sizes, Multi-tasking abilities for diverse picking operations, User-friendly interface for monitoring and control, Continuous learning from operational data, Customizable workflows to fit specific warehouse needs.
Covariant is commonly used for: Leverage learnings.
Covariant integrates with: Warehouse Management Systems (WMS), Enterprise Resource Planning (ERP) software, Inventory management tools, Automated Guided Vehicles (AGVs), Conveyor systems, Barcode scanning systems, Cloud storage solutions, Data analytics platforms, IoT devices for real-time tracking, Safety and compliance monitoring tools.
Geoffrey Hinton
Professor Emeritus at University of Toronto
1 mention

RFM 1 Scaling Update: In-context Learning of Grasping Improvements
Mar 27, 2024