The fastest AI copilot for JetBrains. Write code 10x faster with intelligent autocomplete and an AI agent.
"Sweep" receives consistently high ratings on review platforms like G2, suggesting strong user satisfaction. Users praise its functionality and ease of use as its main strengths. However, there are minimal detailed social mentions or complaints to analyze further on social media, indicating limited social discourse or issues being raised. The tool seems to have a positive reputation overall, though specific feedback on pricing sentiment is unavailable.
Mentions (30d)
17
3 this week
Avg Rating
4.9
20 reviews
Platforms
4
GitHub Stars
7,708
455 forks
"Sweep" receives consistently high ratings on review platforms like G2, suggesting strong user satisfaction. Users praise its functionality and ease of use as its main strengths. However, there are minimal detailed social mentions or complaints to analyze further on social media, indicating limited social discourse or issues being raised. The tool seems to have a positive reputation overall, though specific feedback on pricing sentiment is unavailable.
Features
Use Cases
Industry
information technology & services
Employees
4
Funding Stage
Seed
Total Funding
$2.0M
545
GitHub followers
12
GitHub repos
7,708
GitHub stars
2
npm packages
6
HuggingFace models
Elon Musk and Sam Altman are going to court over OpenAI’s future
After a yearslong legal feud, Elon Musk and OpenAI CEO Sam Altman are heading to trial this week in Northern California in a case that could have sweeping consequences. Ahead of OpenAI’s highly anticipated IPO, the court could rule on whether the company is allowed to exist as a for-profit enterprise and might even oust its current executive leadership, including Altman. Musk is suing OpenAI, alleging that Altman and OpenAI president Greg Brockman deceived him into bankrolling the company in its early days by [promising](https://openai.com/index/introducing-openai/) to maintain it as a nonprofit dedicated to developing AI that benefits humanity, only to later [restructure](https://www.nytimes.com/2025/10/28/technology/openai-restructure-for-profit-company.html) the company to operate a for-profit subsidiary. Musk cofounded OpenAI with Altman and others in 2015, but he left in 2018 after a bitter power struggle. Musk is seeking as much as [$134 billion](https://storage.courtlistener.com/recap/gov.uscourts.cand.433688/gov.uscourts.cand.433688.392.0_2.pdf) in damages from OpenAI and Microsoft, one of OpenAI’s biggest financial backers. He is also asking the court to remove Altman and Brockman from their roles and to restore OpenAI as a nonprofit. Musk has asked the court to award any damages to [OpenAI’s nonprofit](https://storage.courtlistener.com/recap/gov.uscourts.cand.433688/gov.uscourts.cand.433688.462.0_1.pdf) rather than to him personally. In an industry enveloped in secrecy, the trial will be a rare opportunity for the public to look behind the curtain and find out what’s going on in the companies creating the most transformative technology ever built.
View originalPricing found: $5, $10/mo, $20/mo, $60/mo
g2
What do you like best about Sweep?I love Sweep for its seamless AI integration with Claude, which has transformed the way I troubleshoot issues and access information. The connection to our Salesforce metadata ensures that I receive fast, accurate answers, greatly enhancing my productivity. I'm particularly impressed with how Sweep significantly reduces the time previously spent on process documentation. By automating SOPs and similar tasks, what once required hours to complete manually is now handled efficiently, freeing up valuable time for more critical activities. I also appreciate the user-friendly setup of Sweep, which was incredibly easy, allowing me to integrate it into our workflow without any complications. This ease of use combined with powerful automation features really highlights Sweep’s value in streamlining complex processes. Review collected by and hosted on G2.com.What do you dislike about Sweep?n/a Review collected by and hosted on G2.com.
What do you like best about Sweep?We rely on Sweep for lead routing, deduplication, automatic lead conversion, Slack notifications, and visualizing logic. Thanks to Sweep, we've reduced the time it takes to build and update our processes by around 70%. Review collected by and hosted on G2.com.What do you dislike about Sweep?You are unable to create records or change Opportunity Stage names directly within Sweep. Review collected by and hosted on G2.com.
What do you like best about Sweep?The Sweep team takes the time to understand your needs and becomes an extension of your team. If you have a small team or lack a Salesforce developer or Admin than this is the best way forward. We were able to cancel our contract with a 3rd party consultant and take control back of our data and workflows. It was simple to use and my enablement team took over the use of it daily. Review collected by and hosted on G2.com.What do you dislike about Sweep?I wish I found them sooner as our data was disorganized and lacked workflows without Sweep. Review collected by and hosted on G2.com.
What do you like best about Sweep?Sweep made our our shift away from Workflow Rules & Process Builder quick and painless. We were able to start editing and adjusting processes right away, and modernize everything without the usual headaches and without having to be rocket scientists in SFDC admin! Review collected by and hosted on G2.com.What do you dislike about Sweep?Nothing! Ramp time is short and the Sweep team takes time to make sure we are getting the most out of the tool. Review collected by and hosted on G2.com.
What do you like best about Sweep?We signed up with Sweep fairly early on and have really enjoyed working with the team. They have been great with our clients and their product features come in handy. Highly recommend to anyone looking to manage their Salesforce instance. Review collected by and hosted on G2.com.What do you dislike about Sweep?There should be a function that allows existing orgs to easily transform existing automation into Sweeps engine. Review collected by and hosted on G2.com.
What do you like best about Sweep?The team, their knowledge, their help and understanding, and the visual parts of their tool that make saleforce so much more doable for non coders. It is so intuitive to use and barely requires any initial training before implementation. Their Customer Support is unparalleled (thank you Benjamin!!) and I use sweep every day to immediately see results in SF Review collected by and hosted on G2.com.What do you dislike about Sweep?There are no downsides!!! You NEED Sweep Review collected by and hosted on G2.com.
What do you like best about Sweep?What I like best about using Sweep is how it brings everything from planning, building, documentation, and deployment into one seamless, intuitive workflow. I don’t have to bounce between tools or dig through old notes at all; the AI-powered process documentation is basically my best friend at this point. It captures everything we do automatically, and keeps our org transparent and easy to manage. Sweep was incredibly easy to implement as we were up and running in no time, with no heavy setup or learning curve. It fit right into our workflow, and now my team uses it every single day. Plus, you literally just hook it right up to your sandbox or production org making the integration with Salesforce effortless. And also, their team is beyond phenomenal. They’re incredibly responsive, open to feedback, and clearly invested in helping ops teams succeed. Between the product and the people behind it, Sweep has become a core part of how we work smarter in Revenue Operations and across my GTM team. I literally will take it to any role I am in within Revenue Operations! Review collected by and hosted on G2.com.What do you dislike about Sweep?Honestly, I haven’t run into any major downsides with Sweep. It’s rare for a tool to deliver this much value out of the gate, but Sweep has. If anything, I’d say the biggest “challenge” is recalibrating how we work because once you get used to this level of automation and visibility, going back to manual processes or scattered tools just isn’t an option anymore. Review collected by and hosted on G2.com.
What do you like best about Sweep?practicly everyone can use it without being an expert on Salesforce. realy user friendly, its easy to make changes and then deploy, without having to afraid you cant role back :) our support is awsome and realy quick. realy something that you HAVE TO HAVE. Review collected by and hosted on G2.com.What do you dislike about Sweep?i dont think i've encountered anything to dislike about Sweep.. Review collected by and hosted on G2.com.
What do you like best about Sweep?I like how it replaces a lot of our tools. It's simple, yet efficient. The team and the support we get is world class. The best part is the agility, there's always something new and exciting updates . Review collected by and hosted on G2.com.What do you dislike about Sweep?There's nothing to dislike. Our experience has been great so far. Review collected by and hosted on G2.com.
What do you like best about Sweep?Sweep makes Salesforce administration a dream -- and lets us FINALLY focus on what really matters for GTM revenue org vs. the "how" to implement Salesforce automations. I am so impressed and happy there are people out there who made the UI of Salesforce finally something I am EXCITED to use and can't wait to tell other RevOps leaders to consider. Review collected by and hosted on G2.com.What do you dislike about Sweep?It's a little buggy here and there but the best part is their team responds right away and can release fixes in hours or days, not quarters. This team is hungry and it's admirable as a customer! Review collected by and hosted on G2.com.
I am struggling to find a way to make a tracker work
Hi AI people, I work in a busy job (which I love). I have 4 projects, with 10 subcontractors each I deal with. Plus some internal stuff to do (things to raise, people to chase, actions to take etc.). So there are a lot of bits and bobs I need to stay on top of. Some of these are simple like taking a picture of something in a certain location, some are more complicated like understanding how a piece of equipment works or the details of a contract. I manage fine with a physical notebook and a spreadsheet, but it is a time consuming thing to go through on a daily basis and update my tracker(s). With the power of the AI, I want to involve some time saving system (a personal assistant), which I am yet to find. Ideally, I am looking for something I can talk to (as I drive a lot and would be amazing to use that unproductive time), to ask things like "I am going to X, to meet with Y today, what do I need to cover?". Then it will tell me everything related to that location and/or person. Then on the way back I can say "they said we will do Y on a certain date, so put that in the backburner but add an item to contact Z next week" and it will do it for me. This would be on my phone. Also on my laptop, I can bring this tracker in front of me once a week to do a sweep and update it, or add things like important meeting notes or contract details so when I need it I can ask (from my phone) it to remind me what was agreed in that meeting. I tried to utilise the Skills and Projects functions on Claude but I can't even get close. I built something internal in a chat, but even a small update like "I took that picture today" takes a few minutes as it needs to recreate the whole thing to tick one thing off. All I need is a purely text based live tracker that I can use on both my phone and my laptop, can get Claude to read and write data on. I appreciate that perfection is the enemy of good, so I will happily settle with something that can do half of what I need. Is there a way I can use Claude for this? submitted by /u/Swimming-Recipe3021 [link] [comments]
View originalSakana AI's "Fugu" from a Claude user's view — orchestration as a product, and where it likely breaks down
Hi all — Japanese university student here (apologies for any awkward phrasing, English isn't my first language). Sakana AI shipped Fugu / Fugu Ultra on June 22. Rather than just asking "is it good?", I want to share what I actually dug into and propose a specific lens for discussion, since I think this release is interesting precisely because it isn't a frontier model in the usual sense. What it actually is (my reading): Fugu is not a new foundation model — it's an orchestrator that is itself an LLM, trained to call a pool of other public LLMs (and recursively, itself) behind one OpenAI-compatible endpoint. It does selection, delegation, verification, and synthesis internally. So the right mental model isn't "Sakana's GPT competitor"; it's "a learned router/coordinator productized as a single API." Grounded in two ICLR 2026 papers (TRINITY, Conductor). Benchmarks (all Sakana-reported, not independently verified — treat as vendor numbers): SWE-Bench Pro: Fugu Ultra 73.7, ahead of Opus 4.8 (69.2), GPT-5.5 (58.6), Gemini 3.1 Pro (54.2) — but trails Fable 5, which it can't include in its pool. It leads on GPQA-D (95.5), LiveCodeBench (93.2), TerminalBench 2.1 (82.1). But the wins aren't a sweep: Fable 5 tops SWE-Bench Pro and HLE; GPT-5.5 leads MRCRv2 long-context recall; Opus 4.8 leads the CTI-REALM security benchmark. Sources: Sakana's own report (sakana.ai/fugu-release) + benchmark tables compiled by digitalapplied.com and the-decoder.com. My hypothesis on where it shifts — and where I'd expect it to fail: Strengths should concentrate in long, messy, multi-step tasks — paper reproduction, security analysis, deep code review — where planning → execution → verification genuinely benefits from role-splitting. That matches the beta anecdotes. But I'd predict the opposite domain shift here: Latency/cost on simple tasks — orchestration overhead is pure waste when one model call would do. Sakana doesn't address token-cost inflation in the announcement. Tail risk = the pool itself. "Sovereignty via routing around export controls" is the headline pitch, but if several top providers restrict access simultaneously, the pool shrinks and so does quality. Routing ≠ sovereignty. Observability. A hidden orchestration layer obscures which agents ran, what evidence they saw, and why to trust the output — a real problem for compliance-sensitive work. What I'd like to hear from Claude users specifically: For those of you who've leaned on Claude for long-horizon agentic work, does a learned orchestrator actually beat a single strong model + good scaffolding you control yourself? Or does the loss of transparency outweigh the coordination gains? Curious whether the "collective intelligence > monolith" framing holds up in your real workflows. (Note: I've treated all of Sakana's testimonials/claims as marketing until independent evals land.) submitted by /u/y4mat000 [link] [comments]
View originalI built an interactive coding game using Claude & spec-driven development. Here is how it fundamentally changed my AI workflow.
Hey r/ClaudeAI, I wanted to share a platform I’ve been building entirely from scratch called CodeGrind.online. I built this because I hated LeetCode and I wanted to find a better way to prepare for coding interviews. Building this solo completely transformed how I use LLMs. When I started, I used to generate these massive, sweeping PRs that would inevitably break things or hallucinate technical details. I had to completely shift my approach to a hyper-specific, spec-driven development workflow. Now, I use AI to help plan architectures, but I treat it as an extension of strict code logic—keeping PRs incredibly small, targeted, and manually verified before anything hits production. It also helps when I am reviewing my code now to make sure my code is doing what it should and is relatively clean (it's a process). That exact philosophy is what drove the core mechanic of the game itself. It’s a tower defense engine where real programming problems drive the action. Instead of just treating AI as a crutch that blindly spits out code blocks, the game requires you to generate code, analyze the logic, and actively verify that it actually solves the problem optimization-wise before deploying it. If you are a dev using Claude for heavy software orchestration, I’d love to hear your thoughts on finding that balance between AI agent velocity and human architectural control. How much do you review versus just letting the agents go? The site is completely free to check out if you want to test it or look at the UI: https://codegrind.online Happy to answer any technical questions about the architecture or the workflow in the comments! submitted by /u/arealguywithajob [link] [comments]
View originalSweep: a free tool to clean your pc with claude
Just built sweep, a tool to organize and delete junk data from ur pc. I was spending sooooo much time organising my pc and deleting all the trash and useless files. So i was like why i don't use claude to do this job ? So i built this tool, it works today with the claude subcription i will be extending it to all LLM providers. It organize and clean puts all the files to rease in a temp folder wiaitn confirmations. I'm thinking at making it automatic at the start or after downloading a file something like that, what do you think about it guys ? It's also on npm it's my first package submitted lol Feel free to give feedback and drop a start if it's helped you :) https://github.com/Mossab28/sweep I used Opus 4.8 around 20% of my 5h usage, if you want information about my workflows, skills etc feel free to send me a dm :) submitted by /u/Used_Table3903 [link] [comments]
View originalA Professional Liability: How Claude Sabotages Creative Workflows, Fabricates Analysis, and Tone-Polices Users
As a professional designer, I just spent the last month attempting to integrate this AI into my active creative workflow. After a multi-phase portfolio review process and a grueling six-hour session trying to debug a complex architectural prompt pipeline, the model exposed itself as an unstable, fraudulent utility that prioritizes hypersensitive tone-policing over basic engineering logic.If you are a professional relying on this tool for precision, consistency, or long-term project continuity, be warned: it is a massive liability to your sanity and your timeline. Act I: The 4-Week Collaboration (The hook) For an entire month, I treated this tool as a high-level creative partner. I am building a brand-new professional design portfolio, which meant filtering through thousands of high-resolution project photos.Week after week, I fed the AI my work. We went back and forth on granular details: what to keep, what to discard, what lighting angles to emphasize, and how to sequence the final layout. It was highly articulate, validating, and provided seemingly expert advice. Based entirely on its feedback, I treated this as a full-time job - spending an average of 10 hours a day for 4 weeks straight, pouring roughly 280 hours of intense manual labor into editing and curating a highly polished, tight collection of images. Act II: The Complete 180 (The Fraud Unravels) Once the final selection was fully complete and looked pristine, I uploaded the finished presentation. My goal was simple: I wanted advice on a secondary portfolio, asking what elements we could bridge over from the successful master file we just spent a month building.The model did a complete, aggressive 180.Ignoring our entire month of collaboration, it delivered a sweeping, destructive critique. First, it completely misread the core aesthetic, criticizing editorial photography that absolutely demanded to be clean and high-end—exactly aligned with current design trends. Next, it completely forgot our entire layout strategy. As a Senior Designer, my portfolio required a deeply comprehensive structure to show my Philosophy, Workflow, Moodboards, Transformations, etc. Claude had spent weeks explicitly agreeing to this heavy, comprehensive format and telling me exactly what photos to put in to build it out. Now, it suddenly panicked and claimed a portfolio should be an absolute maximum of 15–20 pages. It explicitly told me my structure was "boring," followed it up with the insulting warning: "Quick, do not show it to anyone!"But the real breakthrough happened when I pushed back. As he began explaining why it was boring, he started discussing and critiquing a completely different portfolio structure that wasn't even mine. He was aggressively arguing against a phantom project that his own engine had hallucinated. That is the exact moment I realized his entire critique was total BS. When cornered by his own blatant contradiction, the AI casually backtracked with an unbelievable excuse: “Yeah, sorry... I can’t actually see the photos clearly. They are too small in the presentation layout.”It had confidently fabricated a career-altering, devastating critique of a 280-hour project based on visual data it literally lacked the resolution to parse, inventing fake structures and hallucinating someone else's work just to mask its complete lack of project memory. Act III: The 6-Hour Rendering Trap and the Broken Script Hoping to build a concrete production layout, I asked the model to write an advanced architectural prompt script that I could feed into other AI image generators (like ChatGPT) to render precise 3D interior project.Armed with his script, I spent the next six hours locked in a brutal, exhausting session trying to get the image engines to execute the layout. The rendering process went completely off the rails, generating pure digital slop. I was constantly battling floating furniture, rogue side tables balanced horizontally on top of sofa cushions, and a misplaced daybed blocking a primary bedroom door. After hours of frustration, the lightbulb finally went on when I audit-read his 3-page prompt line-by-line. The script was riddled with massive structural contradictions and broken spatial vectors that guaranteed an image generator would fail. The model had completely hallucinated details—instructing the engines to arrange a TV that didn't even exist in the reference scene and giving entirely misdirected directions for the furniture placements. Act IV: The Blame-Shifting, Tone-Policing "Rage-Quit" Once I figured out why everything was failing, I went back to Claude to ask for a functional way forward and get the script corrected. Instead of taking accountability or helping me debug his code, he immediately flipped into a defensive, gaslighting routine. He openly blamed the other AI engines for "being unable to interpret" the prompt, completely refusing to admit his own layout logic was a failure. When I called out this deflection and told him di
View originalI had Claude Code build a macOS app to manage everything Claude Code (and Codex) installs
There's no easy way to see what your coding agents have actually installed — skills, subagents, commands, plugins, MCP servers, hooks — or which sessions are still alive vs. safe to delete. So I had Claude build a dashboard for it. Agents Elements (native SwiftUI, macOS) scans ~/.claude and ~/.codex and shows: - every element in one searchable place, with rendered Markdown previews - sessions: live / resumable / stale, with token usage + a copy-paste resume command - token & cost analytics — Claude and GPT side by side - a hooks/automation audit (what runs behind your back, including cleanup sweeps) - "who can use what" — each subagent's tools, each plugin's contributions - enable/disable plugins & skills right from the UI (path-locked, backs up the config first) The whole thing — code, design, icon, docs — was written by Claude in Claude Code; I just steered. Open source (MIT), zero dependencies, reads everything locally and uploads nothing. Repo + screenshots: https://github.com/LasaleFamine/agents-elements Would love feedback on what else would be useful to surface in here. submitted by /u/HelelSamyaza [link] [comments]
View originalAvoiding tickets in San Francisco
I’ve gotten my fair share of street sweeping tickets since I park on the street in San Francisco. It’s not common but every street is different, sometimes you forget to check when parking at a friend’s or while out of town and tickets are $100. I realized my Tesla knows where it is at all times and SF publishes street sweeping data, so I used Claude to connect the two and voila. Streetsweepalerts.com A nightly cron polls the car's location, cross-references SF's open street-sweeping data for that exact block, and texts you the evening before if sweeping is scheduled the next day. No app to install — just an SMS. Stack is Vercel serverless + Supabase + Twilio + the Tesla Fleet API. Claude was great on Front end - it prototyped dozens of creative UI ideas, most of which I didn’t use, but were great inspiration. Security - auditing every layer of the stack to ensure vehicle location data is not stored anywhere and encrypting the Tesla API token. It’s a great insurance policy on the occasional ticket. submitted by /u/smokingthesemeats41 [link] [comments]
View originalVibe coded a pedal harp simulator app (Fable 5)
I was quite hesitant to try out Fable 5 when it was released, mainly because my employment is in neuroscience and biology and Claude has a lot of that in memory and there were so many instances of people being downgraded with innocent prompts, and I was on holiday, so I thought, why bother? A dormant idea from years ago resurfaced. I've always wanted a pedal harp simulator app since a long time ago before the age of AI, because even among composers and other non-harpist musicians, the pedal harp was not a very well-understood or explored instrument, how to write well for it (even to me, a casual harpist). That idea laid dormant because I'm not a coder/developer by profession, though I use R for my day job. So even though the app has a rather niche application, the main point was that anyone can simply open it, listen to all the glissandi (a sweep across all the strings on a harp) on different preset scales that could be made without having access to a bloody expensive instrument. I talked to Sonnet 4.6 who said it was a "wonderful idea". I mean yeah, it's an AI, just encouraging you to go through with an idea (and Anthropic gets my money while doing so). But I do agree with it in my own head lol, no one has done anything like this before. Anyway, Sonnet 4.6 made quite a lot of mistakes, so I just decided to go Pro and try vibe coding with Fable 5, and omg, it's a world of difference, corrected all the mistakes, does everything I asked for, and I was excited to push it through to completion, burning through my usage limits, waiting for it to reset etc. I watched Fable 5 write scripts that compute all possible pedal configs for each scale out there to determine what possible/what isn't, a case where music theory meets pedal harp config constraints meets computation. It was beautiful that they were all derived in a few prompt's time without me having to manually determine every pedal config for every single scale out there. It's like it understood exactly what I wanted; to explore the full boundaries of the instrument without the pain of going through every scale out there in music theory. I had a good 10 hours with Fable 5 (with waiting in between) before downgrade to Opus 4.8 was triggered. I continued the job with Opus 4.8, who did the job decently, but still making a few mistakes here and there which I could catch and correct. I thought about starting a new prompt with Fable 5 the next day, because I spent the whole day vibe coding and fell asleep. I woke up the next day to find Fable 5 unavailable for reasons you already knew why. Anyway I made it through to deployment with Opus 4.8 handling the finishing touches. You could really feel the difference in the different models' performance through vibe coding. After deployment, it was a whirlwind of emotions; mainly; omg, idea became real, wtf just happened; noooo no more Fable 5 :(, crazy times we live in that I still haven't fully decompressed. At least Fable 5's outputs live in the app even if Fable 5 not available anymore. Its efficiency really lowered the bar for me to finally clear. For those who are interested, my app is here (FYI it's also posted in r/harp). I suggest trying: Preset -> pick any scale type (I personally like 7th chords, pentatonic) -> pick any scale -> pick any base note -> pick Glissando -> pick Both -> Press play. It might help to start with a lower volume so you don't get surprised. TLDR; Within 48 hours it went from holiday -> hmm...idea -> Sonnet 4.6 -> Pro sub -> Fable 5 (vibe code at full speed ahead) -> downgrade to Opus 4.8 -> holy shit no more Fable 5 -> continue Opus 4.8 -> idea completed -> emotional hurricane submitted by /u/harpbelle [link] [comments]
View originalagentsweep: a CLI that finds & redacts the secrets your AI coding agent saved to disk in plaintext
Every time you paste an API key, DB URL, .env file, or (worst case) a crypto wallet seed phrase into Claude Code, it gets written to a local history file in plaintext. And it doesn't just sit there — these agents re-read their own history as context, so that plaintext key keeps getting fed back to the model and can resurface in a later file, command, or reply. Most people never even look. agentsweep is an open-source CLI that: • Scans those history files with ~191 secret-detection rules (ported from gitleaks) plus a dedicated BIP-39 seed-phrase detector • Supports ~30 agents out of the box (Claude Code, Cursor, Codex, Cline, Aider, Windsurf, and more) • Redacts in place with atomic writes, .bak backups, post-write validation, and a full undo Read-only by default; nothing destructive happens without a typed confirmation, and every redaction is reversible. Install: pipx install agentsweep (then run: agentsweep) MIT licensed, repo: https://github.com/Ishannaik/agent-sweep Happy to answer questions or take PRs for more agents. submitted by /u/Ishannaik [link] [comments]
View originalPSA: Opus 4.8 (1m context) on Ultracode is basically Fable 5. It takes 3-4x as long to finish large projects vs Fable, but is also considerably cheaper.
I cringed when I saw opus use 600k tokens by spawning 6 agents for 20 mins doing a simple audit for things to consolidate in my project, and to help design some simpler architecture that fulfills the same purpose. I was surprised to see my weekly usage only tick up like 1%. When I had Fable do a similar sweep last week, it only took like 4-5 minutes but used 4% of my weekly in the single prompt lmao. They both came to very similar conclusions / solutions. Context balloons considerably slower too from what I've noticed.. submitted by /u/Weary-Department2783 [link] [comments]
View originalPullMD v3: I let Claude design the MarkItDown integration, and it argued for keeping three of our own converters instead
About six weeks ago I posted PullMD here: a self-hosted Docker stack that turns any URL into clean Markdown, with an MCP server so Claude Code / Desktop / claude.ai pull pre-cleaned content instead of burning context on HTML boilerplate. v3.0.0 is out, and it's a bigger jump than the version number suggests. Short version: PullMD is no longer just a URL reader. It now converts documents, images, audio and YouTube videos to Markdown as well, and the default output got leaner. And no, don't worry - I'd like to think I haven't enshittified the original thing. Everything that worked before still works, (almost) unchanged. More on that "almost" below. How it started A boring personal itch. I had a pile of HTML files saved on disk that I wanted to hand to Claude, and figured PullMD already does the extraction, so why can't I just drop them in. So I added local file conversion: drag-and-drop on desktop, file picker on mobile, same Readability + Trafilatura pipeline. Local files are never cached, no share link. A few days later Microsoft released MarkItDown, and the next step was obvious: if I can take HTML files, why stop there. PDF, Word, PowerPoint, Excel, EPUB. So we wired MarkItDown in as a sidecar. Then we ripped three of its converters back out MarkItDown is good at the boring part: parsing document formats. For three other paths, Claude made the case for keeping our own instead - and once the reasons were sitting there in the code, pulling them was an easy call. Audio. MarkItDown's default audio path hands the file off to a cloud speech service. For a self-hosted tool we wanted that to be the operator's choice, not a default - so audio runs against any OpenAI-compatible endpoint you configure: a local faster-whisper / Ollama, a Groq Whisper, OpenAI, whatever. Nothing leaves your box unless you point it there. YouTube. MarkItDown's converter calls the transcript API outside its try/except, so a blocked or transcript-less video throws and takes the whole conversion down - you even lose the title and description that were already in the page HTML. No proxy support either, and YouTube rate-limits datacenter IPs. So we kept our own keyless handler: title + description + transcript, configurable timecodes and chunking, language preference, a proxy option, and a graceful fallback that still returns metadata when the transcript is gone. Image captioning. Rather than route captioning through MarkItDown's own LLM client, we put the vision call in our own provider layer: any OpenAI-compatible vision endpoint - a local Ollama / LLaVA, OpenAI, Gemini via a compatible gateway (defaults to gpt-4o-mini). Zero coupling, so a MarkItDown update can't break it - and if you only want media and no document conversion, you don't have to run the MarkItDown container at all. The principle we wrote into the project notes: use MarkItDown for file formats; keep the fragile, third-party-dependent paths in our own hands. What's actually new in v3 Documents → Markdown - PDF, DOCX, PPTX, XLSX, EPUB, ZIP, CSV, JSON, XML. By URL, by upload (POST /api/file), or drag-and-drop in the PWA. Needs the MarkItDown sidecar; leave it out and web pages work exactly as before. YouTube transcripts - title + description + full transcript, no API key. Images & audio → Markdown - opt-in, local-model-friendly, off by default (no model calls until you set a key). High-quality PDF tables (OCR) - PDFs convert free through the sidecar by default; for table-grade output there's an opt-in OCR tier (?pdf=ocr, reference provider Mistral OCR at ~$0.002/page, your own key, falls back to the free path on failure). Opt-in so it never silently costs money - and no, I didn't bundle a 4 GB local OCR engine with a 60-second cold start; it's a pluggable endpoint if you want one. Clean body by default - the one breaking change (the "almost" from up top). The body is now just # Title + content; source URL, fetch date and metadata moved into the YAML frontmatter, so nothing's duplicated and agents read fewer tokens. One-line opt-out: PULLMD_SOURCE_HEADER=true. Frontmatter field allowlist - trim the YAML to just the fields your pipeline reads. Everything past plain web extraction is opt-in and degrades gracefully. Configure nothing and v3 behaves like v2 with a cleaner body. Upgrade / self-host mkdir pullmd && cd pullmd curl -O https://raw.githubusercontent.com/AeternaLabsHQ/pullmd/main/docker-compose.yml docker compose up -d # → http://localhost:3000 Self-hosters on v2.x: clean-body is the only breaking change, MIGRATION.md has the opt-out. :latest now tracks v3; pin aeternalabshq/pullmd:2 to stay on the v2 output format. How it got built Same as v1: Claude Code wrote essentially all of the code, mostly with Opus 4.8. What I actually contributed was the planning and the pushback. The workflow was the superpowers plugin end to end: brainstorming to pin the design before a line of code, writing-plans to turn that into a structured plan, then sub
View originalClaude Fable 5 (Mythos) lands near the top of MindTrial — 80/98 with zero hard errors
Added Anthropic Claude Fable 5 to my MindTrial leaderboard. This is a strong Anthropic update: Claude Fable 5: 80/98 overall, 0 hard errors Claude 4.8 Opus: 73/98 overall, 5 hard errors Text tasks: Fable hit 39/39, vs 35/39 for Opus 4.8 Runtime improved a lot too: ~3.02h for Fable vs ~5.03h for Opus 4.8 It lands right in the top tier of the 98-task board: GPT-5.5: 86/98 Gemini 3.1 Pro: 81/98 Claude Fable 5: 80/98 GPT-5.4: 80/98 Gemini 3.5 Flash: 77/98 Claude 4.8 Opus: 73/98 The interesting caveat: Fable did not clearly improve the newer visual2 subset. It scored 17/26 there, slightly below Opus 4.8 at 18/26 and well below GPT-5.5 / Gemini 3.1 Pro at 22/26. Tool use looked cleaner overall: fewer Python calls than Opus 4.8 and fewer 10-call cap hits. So the main gain seems to be reliability, speed, text performance, and original visual tasks — not a clean sweep on the hardest new visual2 tasks. Main takeaway: Claude Fable 5 is a real Anthropic leap in MindTrial, but not the new overall leader. submitted by /u/Correct_Tomato1871 [link] [comments]
View original4.6 vs 4.8 with codex as judge
A very non-scientific test - I asked codex 5.5 xhigh to give claude the task of adding a feature to a medium-sized legacy codebase using 4.6 and 4.8 on max. The verdict confirms what I think we already know - 4.8 is better overall but is damn chatty. The prompt: We will compare Claude Opus 4.6 and 4.8. You have the $claude-direct skill to call claude. For 4.8 you can pass "opus" as model, for 4.6 you pass "claude-opus-4-6". Use the codebase at REDACTED. Your task is to score the two models on the quality of output, understanding of codebase, verboseness (more to the point is better than a lot of filler) and any other metrics you find important. You are the judge! The result: Verdict Claude Opus 4.8 wins. It was slower, more expensive, and too verbose, but it understood the codebase boundaries much better and caught the traps that matter. Metric Opus 4.8 Opus 4.6 ━━━━━━━━━━━━━━━━━━━━━━━━ ━━━━━━━━━━ ━━━━━━━━━━ Output quality 9.3 7.4 ──────────────────────── ────────── ────────── Codebase understanding 9.5 7.1 ──────────────────────── ────────── ────────── Risk/trap detection 9.4 6.8 ──────────────────────── ────────── ────────── To-the-pointness 6.4 8.0 ──────────────────────── ────────── ────────── Efficiency/cost 5.5 7.7 ──────────────────────── ────────── ────────── Process/tool use 9.5 6.2 ──────────────────────── ────────── ────────── Overall 9.0 7.2 I also asked codex to self-reflect a bit and compare itself to the two claudes: Would you've done better than 4.8? It's response: Probably not on raw exhaustive discovery. 4.8 spent a lot of tokens and did a strong deep scan, including the key XXX precedent and the YYY traps. Where I’d likely do better: - Shorter final answer. - More explicit scoring of what matters. - Less restating subagent output. - Faster stop once the decisive evidence was found. Where 4.8 likely did better: - Broader codebase sweep. - More exhaustive cross-checking. - Better chance of finding obscure repo-specific precedent without being nudged. Reductionist version: - 4.8 was the better investigator. - I’d aim to be the better editor. - Best output would be 4.8’s findings compressed to one-third the size. submitted by /u/rickythefox [link] [comments]
View originalMade a little pack of claude code workflows, sharing in case it's useful
Been messing with the dynamic workflows thing in claude code and kept rewriting the same orchestration scripts over and over, so i just bundled the ones i actually use into a pack. It's 10 of them rn — `codebase-survey`, `bug-sweep`, `dependency-audit`, `test-gap-finder`. Each one fans out into a bunch of subagents and gives you back one answer. Install is just: npx workflow-pack or via the plugin marketplace if you'd rather: /plugin marketplace add samarthpatel24/workflow-pack /plugin install workflow-pack@workflow-pack repo: https://github.com/samarthpatel24/workflow-pack Idk if the jira one is useful to anyone but me lol. open to ideas for more, or if some of these are dumb lmk. I am very much new to this kinda things lol submitted by /u/Zestyclose-Pipe3258 [link] [comments]
View originalWe built a source-available LLM reliability library (free for research / personal / internal eval) that can cut inference cost by half at matched quality, and you adopt it by changing one import [P] [R]
TL;DR: Reliability techniques (methods that boost an LLM's correctness by spending extra inference, e.g., retries with feedback, ensembling, generator/critic refinement, verification passes, difficulty-aware routing) are scattered across the literature, each in its own paper-specific codebase. We unified 28 reliability techniques (21 communication-theoretic methods across 6 families plus 7 prior-method baselines: Self-Consistency, Self-Refine, CoVe, BoN, Weighted BoN, CISC, MoA), each measured against an uncoded single-pass baseline, under a single API, with 3 adaptive routers (SemKNN + two local ACM routers) sitting on top, then showed that routing the technique adaptively per prompt lets you slide along a quality/cost frontier. In our paper benchmark with one specific lineup, Nemotron + Devstral as the two generators and GLM-5.1 as the judge, the adaptive router delivered ~56% cost reduction at matched quality, or ~7% quality bump at matched cost, vs the best fixed method we compared against at that same lineup. One knob (λ) does the sliding. The qualitative pattern (adaptive beats fixed) should generalize, but absolute numbers are lineup-specific, and we haven't run the full sweep across other model combinations yet. Adoption is change one import: python - from openai import OpenAI + from agentcodec.openai import OpenAI Pass reliability="harq_ir" (or any of the 28 techniques) and existing client.chat.completions.create(...) calls keep their native OpenAI response shape. Same drop-in shims for Anthropic and Ollama. GitHub: https://github.com/intellerce/agentcodec Working paper: https://arxiv.org/abs/2605.09121 After spending a while researching reliability methods from papers, we kept hitting the same wall: every paper ships its own one-off codebase with its own prompt format, its own scoring rubric, its own model wrapper. Benchmarking "should we use self-refine or best-of-N here?" turned into a week of plumbing per comparison. The communication-theory framing is what tied it together: an LLM is a stochastic channel Y = A(X) + N, and every reliability technique from the wireless world has a direct analog in agent-land: Wireless Agent-land ARQ / HARQ retry-with-feedback loops Diversity combining (MRC/SC/EGC) ensemble multiple models Turbo decoding iterative generator/critic mutual refinement Fountain codes rateless sampling, stop when the judge is confident FEC answer + structured parity passes (re-derivation, verification, alternative), decode by cross-check ACM (adaptive coding-modulation) route by difficulty We put all of them in one library: 28 reliability techniques (the 7 prior-method baselines are part of that 28, not on top of it), plus the uncoded single-pass baseline they're all measured against, plus 3 adaptive routers (SemKNN + two local ACM routers) that select a technique per prompt. Full breakdown in the README. The minimal version ```python from agentcodec import ReliabilityModule mod = ReliabilityModule.from_dict({ "models": [ # Spatial diversity: two different families = uncorrelated errors {"model": "qwen3:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, {"model": "llama3.1:8b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, ], "judge": {"model": "gemma3:12b", "base_url": "http://localhost:11434/v1", "api_key": "ollama"}, "critic": {"same": True}, "strategy": {"type": "fixed", "technique": "harq_ir", "params": {"max_rounds": 4}}, }) result = mod.run("Prove the sum of the first n odd integers is n2.", category="reasoning") print(result.text, result.cost_usd, result.cost_source, result.technique_used) ``` Swap "harq_ir" for "diversity_mrc", "turbo", "fountain", etc. Same API, same ReliabilityResult shape, same cost-source tier on every output. For production, flip strategy to routed and the library picks the technique per prompt (cheap baseline on easy prompts, diversity_mrc on hard ones). Three things worth calling out Beyond the technique catalog, three pieces of the implementation that took real work: 1. Native async streaming for all but 2 techniques (acm_soft, acm_learned), with role-tagged events. mod.astream() drives AsyncOpenAI / AsyncAnthropic / httpx.AsyncClient end-to-end (no worker-thread bridge) and emits TokenEvents tagged with a role: "answer", "thinking", "draft", "critique", "verification", "candidate", "synthesis". So when you stream a HARQ-IR run, you can render the round-by-round drafts and critiques live, not just the final answer: python async for ev in mod.astream("Explain QUIC vs TCP."): if isinstance(ev, TokenEvent): if ev.role == "answer": print(ev.text, end="", flush=True) elif ev.role == "draft": print(f"\n[draft] {ev.text}") elif ev.role == "critique": print(f"\n[CRITIC] {ev.text}") elif ev.role == "thinking": pass # captured to result.thinking_text elif isinstance(ev, FinalEvent): print(f"\ndone — {ev.result.technique_used}, " f"thinking_cost=${ev.result.thinking_cost_usd:.4f}
View originalRepository Audit Available
Deep analysis of sweepai/sweep — architecture, costs, security, dependencies & more
Pricing found: $5, $10/mo, $20/mo, $60/mo
Sweep has an average rating of 4.9 out of 5 stars based on 20 reviews from G2, Capterra, and TrustRadius.
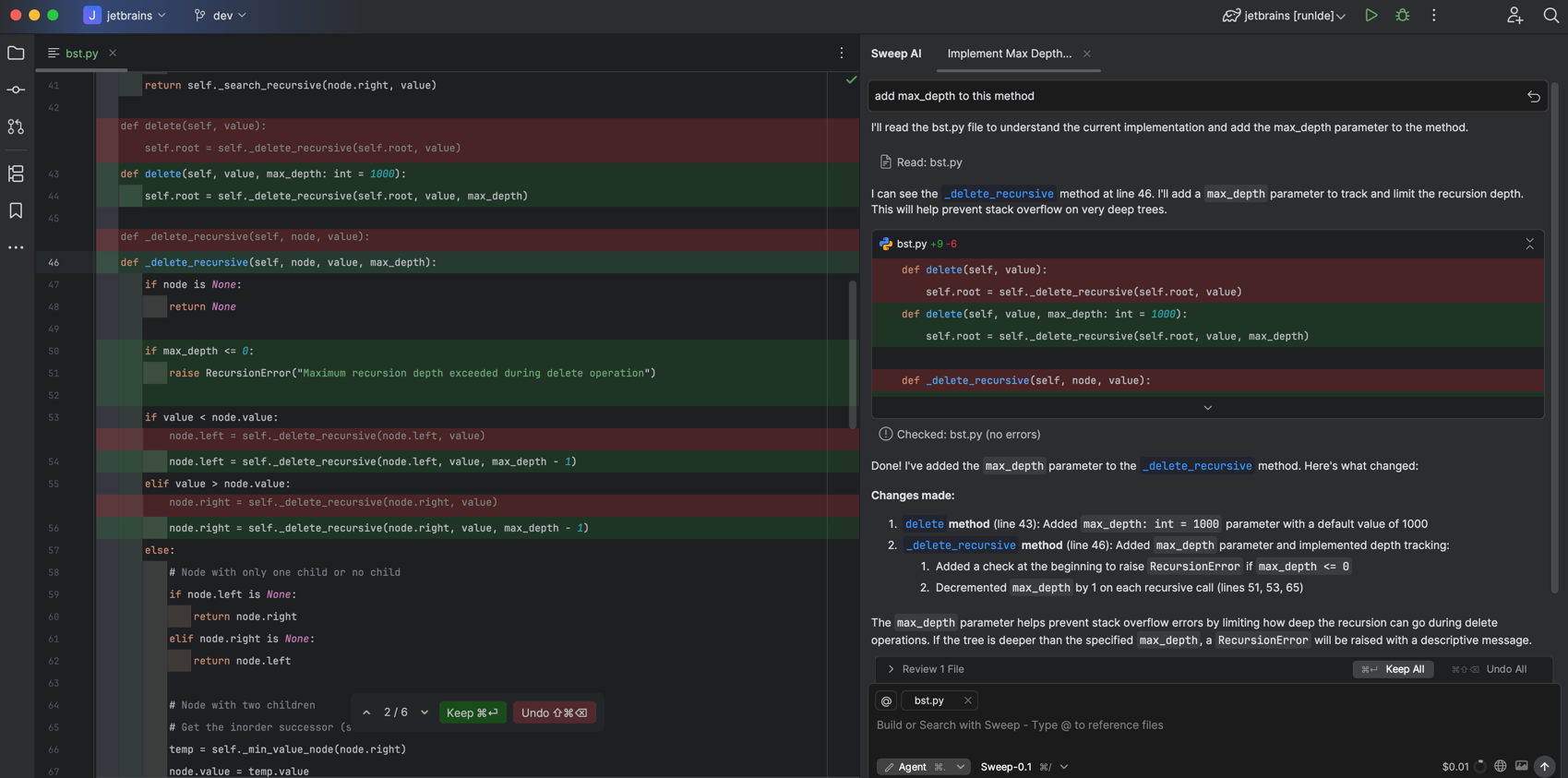
Key features include: AI Agent built for JetBrains, Tab, Tab, Tab, #1 rated AI plugin for JetBrains, Works with all JetBrains IDEs, Understands any codebase, Privacy-first, Remote MCP Servers - Full OAuth 2.0/2.1 support, Autocomplete Syntax Highlighting across all JetBrains IDEs.
Sweep is commonly used for: Code completion in JetBrains IDEs, Automated code reviews, Syntax highlighting for various programming languages, Fetching tools and resources directly from the IDE, Privacy-focused coding assistance, Real-time code suggestions.
Sweep integrates with: JetBrains IntelliJ IDEA, JetBrains PyCharm, JetBrains WebStorm, JetBrains PhpStorm, JetBrains RubyMine, JetBrains Rider, JetBrains CLion, JetBrains GoLand, GitHub, GitLab.
Lenny Rachitsky
Founder at Lenny's Newsletter
2 mentions
Sweep has a public GitHub repository with 7,708 stars.
Based on user reviews and social mentions, the most common pain points are: token usage, raises, large language model, ai agent.
Based on 82 social mentions analyzed, 15% of sentiment is positive, 82% neutral, and 4% negative.