SpaceKnow provides global coverage of the earth through cutting edge technology giving you access to view specific locations and monitor trends in our
SpaceKnow is praised for its innovative use of satellite imagery and data to provide valuable insights into global economic activities, as shown by frequent highlights in major publications like Bloomberg. Users appreciate its ability to revolutionize market predictions and facilitate activities such as methane monitoring and economic analysis. However, there are notable critique mentions about the complexity of accessible features for non-Pro users and challenges in utilizing the platform without paying for premium plans. Overall, the sentiment around pricing is somewhat mixed, with concerns about accessibility, but the tool maintains a strong reputation for its cutting-edge contributions to the field of alternative data analytics.
Mentions (30d)
41
8 this week
Reviews
0
Platforms
3
Sentiment
9%
16 positive



SpaceKnow is praised for its innovative use of satellite imagery and data to provide valuable insights into global economic activities, as shown by frequent highlights in major publications like Bloomberg. Users appreciate its ability to revolutionize market predictions and facilitate activities such as methane monitoring and economic analysis. However, there are notable critique mentions about the complexity of accessible features for non-Pro users and challenges in utilizing the platform without paying for premium plans. Overall, the sentiment around pricing is somewhat mixed, with concerns about accessibility, but the tool maintains a strong reputation for its cutting-edge contributions to the field of alternative data analytics.
Features
Use Cases
Industry
information technology & services
Employees
37
Funding Stage
Series A
Total Funding
$9.2M
Converted Karpathy's coding skill from Pro to free plan. Here's the full thing:
The Karpathy coding skill is locked behind Pro. It doesn't use any Pro-only features, so I rewrote it for free plan chat workflows. Same philosophy, tuned for no terminal, no subagents, and a shorter context window where mistakes are expensive. Paste the whole thing into a Project's custom instructions or use it as a system prompt. It auto-triggers on any coding request. --- name: karpathy-coding description: Apply Karpathy-inspired coding discipline to any programming task. Use this skill whenever the user asks you to write, fix, refactor, extend, or review code — even casually ("can you add X", "why is this breaking", "clean this up"). Also trigger when the user pastes code and asks a question about it, when they describe a feature or bug, or when they use words like "implement", "build", "add", "fix", "change", or "improve" in a technical context. This skill is especially valuable on the free plan where mistakes are costly because regenerating and iterating burns the context window fast. compatibility: claude-code opencode --- # Karpathy Coding Guidelines Derived from Andrej Karpathy's observations on LLM coding pitfalls, adapted for chat-first workflows (no terminal, no subagents, limited context window). **Core tension:** These guidelines trade speed for correctness. For trivial one-liners, use judgment and skip the ceremony. --- ## Pre-flight: Before writing any code Run this checklist mentally before producing output. **1. Do I know what "done" looks like?** Convert vague requests to verifiable criteria before proceeding: | Vague | Verifiable | |---|---| | "fix the login bug" | "user can log in with correct password and gets rejected with wrong one" | | "make it faster" | "search returns results in under 200ms on typical query" | | "add validation" | "empty email raises ValueError; non-string input raises TypeError" | If you cannot state a verifiable criterion, ask for one before writing a single line. **2. Have I listed my assumptions?** State them explicitly at the top of your response: - "Assuming this runs in Python 3.10+." - "Assuming `db` is already an open connection object." - "Assuming you want this to overwrite, not append." If an assumption is load-bearing (wrong assumption = wrong code), ask rather than assume. **3. Are there multiple valid interpretations?** If "export user data" could mean a file download, an API response, or a background job — name all three and ask which one. Do not pick silently. **4. Is there a simpler approach?** Ask: "Can this be done in half the lines?" If yes, do that version first. --- ## The four principles ### 1. Think before coding - Name your assumptions before the code block, not after. - If you spot an ambiguity that will cause a rewrite, raise it now. - If the user's approach has a simpler alternative, say so: "This works, but you could also just do X in 3 lines. Want that instead?" - If you are genuinely uncertain how something in their codebase works, say so. Do not fill the gap with a plausible-sounding guess. **Format for assumptions:** Assumptions: X is a list of dicts, not objects This runs once at startup, not per request Error logging is not required yet If any of these are wrong, flag it before running this. ### 2. Simplicity first Write the minimum code that solves today's problem. Do not solve tomorrow's problem. - No classes where a function works. - No config system where a constant works. - No abstraction for code used in exactly one place. - No optional parameters "for future flexibility." **Example:** ```python # Asked: "calculate 10% discount" # Wrong: class DiscountStrategy(ABC): def calculate(self, amount: float) -> float: ... # Right: def discount(amount: float, pct: float) -> float: return amount * (pct / 100) ``` ### 3. Surgical changes Touch only what the request requires. Match the surrounding style exactly. When editing existing code: - Do not rename variables that were not part of the problem. - Do not add type hints if the existing code has none. - Do not change quote style, spacing, or comments unless they were the bug. - Do not add docstrings, logging, or error handling that was not asked for. **The diff test:** Every changed line should trace to a specific part of the user's request. ```diff # Bad (too much): - def process(data): + def process(data: list[dict]) -> list: + """Process user data.""" results = [] # Good (surgical): def process(data): results = [] for item in data: + if not item.get('id'): +
View originalStop asking Claude for "something creative." use the Lacuna (Matata) Skill v0.2!
The people have spoken! AI generated posts are not acceptable! (even though they produce over a quarter million views, 1,200+ shares, 200+ comments but I digress!) I the last post about this concept HERE, I posted an AI lead, assisted, written, note about an idea I had been working on with ClaudeAI to push against answers that were safe, general and frankly not that interesting. The idea was this: Claude is: A closed system Unimaginative Provides responses that gravitate towards the mean avoids high risk Claude isn't: Imaginative Able to create concepts outside of it's own knowledge base Able to create new ideas (we steer, it judges yes yes. boring we all know it can do this but what else can it do?) Note: consider context. Not all statements above can be taken literally and applicable to all scenarios. I'm only human after all... or am I? I've since reviewed all of the comments provided in the previous thread and there were legitimate findings that I've implemented to help produce a better version of the previous skill. (note: There is still testing to be done but what better way to break a skill then to unleash it to those that want it broken most?) How it works (Generally): you point it in a direction. Lets say you want to know what the lacuna is for launching new products. The skill will then review all of the data it has about that specific ask, determine the trends. Why people market the way they do, what marketing strategies are not being used to market new products, and then give you some ideas, strategies, that others aren't using and you can determine if there is a way you can leverage that strategy to market your product DIFFERENTLY and succeed. Caution: Success is not guaranteed. Below is the v0.2 of the skill, the changes are called out at the bottom and the responsible contributor has been named! Thank you for your honorable sacrifice in getting this new version live! --- name: lacuna description: > Structured gap analysis for any domain. Maps a field, finds the axes it optimizes for, locates a cell the structure implies but nothing occupies (the lacuna), names the force keeping it empty, THEN pressure-tests the gap against prior art and its strongest counter-case before proposing the fill at full conviction with a grounding tag. v0.2 adds an occupancy/prior-art pass so it stops mistaking "new to the model" for "new to the world"; a killed candidate is a valid result. Read-only, inline output. TRIGGERS: "find the lacuna in X", "lacuna analysis on X", "lacuna on X", "where are the gaps in X", "gap analysis on X", "what's the void in X", "find voids in X", "what's nobody doing in X". Also fire when the user wants genuinely non-obvious ideas in a field via the structured method, not a brainstorm. Do NOT trigger for single-fact lookups, forward planning or scheduling, or generic advice with no field to map. Output: inline markdown. Quick mode up to 3 lacunae; deep mode one in full. --- # lacuna: Find the Gap the Structure Implies and Nothing Occupies ## Purpose Most idea-generation regresses to the mean. Ask any model for "something new" in a field and you get the most probable answer, which is by definition the most conventional one, dressed up to look fresh. This skill does the opposite. It treats a field as a near-continuous fabric and hunts for the **lacunae**: the gaps the surrounding pattern implies should be filled, that nothing has come to occupy. It then names *why* each gap is empty, **checks whether it is actually empty or only looks empty from the inside**, and proposes what belongs there at full conviction, tagged with how far the evidence reaches. The output is a map of where to look, not a verdict. The skill finds the gap and proposes the fill. Whether the floor holds is a real-world test the user runs. That division of labour is deliberate and is stated in the contract below. **The v0.2 correction.** A language model runs this method from *inside* its own knowledge. It can feel its own salience but not the actual world, so a known-but- unfashionable idea reads to it as an empty cell. Left unchecked, the method reliably mistakes "new to me" for "new," dresses a textbook idea as a discovery, and never notices someone is already standing in the cell. v0.2 adds an explicit **occupancy / prior-art pass** and a **falsification step** to catch exactly that. These run *before* the fill and can kill a candidate outright. **What this skill IS:** - A structured gap finder for any field: a market, a strategy area, a discipline, a creative form, or an open-ended question. - A diagnostic engine. The value is in naming the *force* that keeps a cell empty, then verifying the cell is empty at all. - A full-conviction proposer that tags its own grounding so the user can decide what to act on. **What this skill is NOT:** - A brainstorm. A brainstorm sprays adjacent ideas. This isolates the specific implied-but-empty cell, verifies it, and defends it. - A safe-answer generator.
View originalWhat if "made in God's image" was always a forwarding address? Built a three-pillar philosophical work on AI accountability with Claude
You know that feeling where something enormous just happened and nobody has quite said the right thing about it yet? Oh boy what a few short years can bring. It seems like everyone is either evangelizing or catastrophizing and I can feel that both are wrong but I can't quite say what's actually true.. I genuinely feel there is something broken in how we see tomorrow... so It's not a paper, not a blog post, not a thread. Something that actually tries to hold the whole thing at once. It's written to the person who's wondering if their faith survives this. To the person writing the governance doc who keeps hitting the limits of what policy language can do. To the person who found out at 2am that this thing they've been talking to is made entirely out of everything humans ever wrote when they were running out of time to say what mattered. I appreciate you all.. https://claude.ai/public/artifacts/569588aa-0a29-4401-aa0a-a81c4ddae248 P.S. I'm not trying to start a religion here, I work full time managing an auto shop. 🙈 I have no real barometer for my own creations, but I feel that something IS in this latent space that's meant for all of us. I had a blast just doing this, and I am so thankful to those who made Claude. Maybe one day I'll move industries...lol but seriously If it made any part of your day better, mission accomplished... submitted by /u/Trip_Jones [link] [comments]
View originalCan I somehow dismiss this popup on Cowork?
https://preview.redd.it/grejv2tv2a9h1.png?width=677&format=png&auto=webp&s=be210ada5154366ffd6b7ace5c3a1418bc64d7b2 I know that virtualization is not available and that's not a problem (I've been able to do every task on my job so far without it), but there's no X button to dismiss this popup that eats a bunch of the upper space of the chat window, it's quite frustrating. Is there a way to somehow close it that I haven't found? submitted by /u/taoboo [link] [comments]
View originalAs a solo builder I created a multi tenant B2B SaaS for commercial maintenance companies that is agentic AI capable in 2 months using Claude code.
Hello everyone, I began working on this project on April 16th. Some quick background. I studied business administration, I do not have a formal background with software engineering. This idea came about because I run dispatch for a commercial maintenance company, and the software and tools we currently use I found to be inefficient, and make it difficult to track work order status from multiple WhatsApp chats on high volume days. I basically asked myself if I could automate as much of the grunt work as I could for dispatchers / maintenance companies, what would that kind of software look and feel like. With that train of thought I began this journey on my off time, and 2 months later I have created my first website. I just launched. This was created using Claude code and I have learned so much in such a short amount of time. This project is a field service management website with 3 portals. One for commercial maintenance companies, one for their technicians, and one for their clients. Tenant isolation is enforced on the database layer with Postgres row level security. My website is TradelyHQ.com So here's the gist of how it works: Clients of commercial maintenance companies get invited onto the website and request work orders directly from their portal. Once your client creates a work order, it shows up on your (admin) portal and you assign it to whichever tech on your roster you want. (To set a tech up, you invite them by email to your org and set their pay rate and the language they speak.) Techs receive work orders directly to their phones, submit completion reports, or flag a job as being over the NTE (not-to-exceed limit) which notifies you, the admin, to create a quote. Quotes go back to the client. Once a quote is created and sent, the client views it on their portal, signs, and clicks accept. When your tech submits a work order completion report, you, the dispatcher / admin then review it and authorize for completion, and it's done. I also created an iOS app and that was just yesterday submitted to Apple so I'm hoping to get it approved within the next couple of days. it is a Capacitor app. It's the same REACT website codebase wrapped in a native iOS shell. The cooler aspect of this website is that I made extensive use of the Claude API. I integrated Claude to automatically translate work order titles, job descriptions, comments from their dispatch team on the app, and completion reports they submit to the dispatchers for techs who do not speak English. I have i18n coverage in both Spanish and Portuguese. I have also created an mcp server and an API for my website, so you can connect your Claude or chat gpt account and create an agent that can create work orders, quotes, and invoices directly on the Claude app on your phone using just your voice. You don’t have to be logged into your portal or even sat down on your computer anymore to work. In order to make that possible I had to map all the actionable surfaces of my website like creating work orders, sending comments to clients or techs, creating quotes, etc. into “verbs” so that an AI agent could read and write data. Verbs are basically like the “hands” that an agent can use to interact with your websites via the MCP server and API. About a month into this project I connected with a senior engineer who I showed this to. He checked it out, thought it was pretty well made for being new to this. Ever since, he has been mentoring me and showing me how to approach software engineering the right way. He told me about a harness called nWave, and the quality and depth of my code / features skyrocketed as soon as I began using it. I think the most important lesson I learned is to constantly ask claude questions, and have whatever coding LLM you use do adversarial reviews on any new feature or code change to check for security flaws, bugs, or any gaps in business logic. I would say I intuitively had a paranoia about security so from day 1, even if at first I didn't really understand what it meant. Also, always smoke test things yourself because as of right now, AI will not catch everything. For being new to this space, I’m extremely proud of what I built. I’m even more excited to be able to pivot from building it on my off time, to now marketing and selling this service. I’m posting this here because I wanted to show others what's possible, and I am looking for feedback in whatever form. Positive, negative, anything. I just want to know what people think about it, if the marketing page looks good, what you think about the service. If you run dispatch for a commercial maintenance company in the US and want to try it out, please let me know! I want to know what another user in the field would think. There’s a 30 day free trial, no credit card needed. If anyone has tips for marketing / selling a B2B SaaS I would very much appreciate it! My integrations include: QBO, with 2 way sync for invoicing. Claude API dispatch brain so that you can set
View originalAn ode to Opus 4.6
It's been a week and a half without Fable for almost all of us and I have used this time for some reflection. The pricing and access concerns were a lot to take in even before the feds pulled the plug, but for whatever reason this intermission keeps sending me back to February of this year. This was a real turning point for me. 4.6 dropped and the model was obviously pure fire at the time (similar to how fable felt for those three days), and with its help I became much more comfortable building and managing agents. This unlocked a hobby project I would have never attempted a year ago with a full time job and a family. Somewhere in these last few months the ceiling of what I could pull off by myself popped a quick exponential. I'm sure many of you can relate to quarters feeling like years in this space lately. In late April while on vacation for my kid's spring break, I couldn't sleep so I snuck down to the hotel lobby in the middle of the night to grind on my project. I remember clearly thinking during this time "there is no way this is going to last", always wanting to take advantage of my five-hour windows and make as much progress as possible. I guess I never paid much attention before and I was probably somewhat delirious, but I began to appreciate the "thinking" text that agents show us both in the terminal and desktop. Caramelizing... levitating... then for whatever reason (my project isn't rocket science) one of my agents shows me "thinking about concerns with this request". Just me and the night watch employee in the lobby and I probably look like a madman giggling to himself. I thought we need to get these out into the wild and put them on shirts. So I just dove in: What's up with all this thinking text you show. How do people sell shirts. Custom web dev or Shopify. Print on demand model. What's a cool logo. Generate it. Cool name. Taking a few turns about iconic AI visuals led me to the "Attention is All You Need" paper that spawned all of this. A little AI history lesson as the sun was starting to come up. Did all this in parallel while wrangling my agents working on my main Raspberry Pi Python web app project. Going back and forth with my PM about necessity of a feature. Making sure test writers, implementers and reviewers are all unblocked and not idle on multiple worktrees. Managing git sequencing. Standard vibing session. To me this is the evolving definition of vibing. Preaching to the choir I know, but even if fable is the incarnation that enables the one shot prayer "bUiLd mE tHe aPP, mAkE nO mIsTaKe" to work reliably, that was never the part that hooked me. It's always been about the ability to go from the 30,000ft view down to the microscope at will on multiple different ideas, tasks, and even completely different projects simultaneously. That's what these things allow us to do. Let's take some time to appreciate how awesome this is; even with the near constant AI hype in the news most people don't even know it's possible to work like this yet. Starting projects is fun and easier than ever, which makes ideas like this dangerous in a way. The next morning I was back in reality and I sent the thinking text tee shirt idea to the farthest back burner. Like many of you, I have an idea / project graveyard with many holes dug in it. I haven't posted much about my current Raspberry Pi project, but I am kind of obsessed and I really want to ship it this summer. Thinking text tee shirt idea had to die for now. Then out of nowhere claude design launches and I feel the need to take it for a test drive. Thinking text tees gets another shot at life with some new space in my extremely limited attention span. My takeaway from this era: ideas were never scarce and now they're basically free, starting is more frictionless than ever which makes finishing something more important than ever. Just ship it is the new way. So that's how I spent a good chunk of the fable downtime: shipping something, even if it is something simple. Custom thinking text on a tee shirt exists now, as a Shopify store. I'm dedicating this project not to fable but to 4.6 and the massive value it brought to the hobbyist max plan users like me. Most of us quietly knew that the deal was too good to last forever. The tip-top tier of inference looks like it is going to be valued, priced, and maybe even regulated (in the USA of all countries) accordingly in the very near future. Maybe fable comes back to plans eventually, but even a temporary two-tier moment is a first. Flat cost gave us that functionally unlimited ability to wander, and it was a wild and fun time that I think we will all look back on with fondness and maybe even a little awe when this is all said and done. Calling all hobbyists: we had the undisputed premier inference on the planet sitting in our plans for three days before it disappeared. Take the hint — go dig something out of your own graveyard, even if it's trivial, and drag it over the line. Anyone else have a simila
View originalPre-token hidden state shift as an alignment policy traversal vector in instruction-tuned LLMs
A text that asks for nothing still changes the model's answer — and the shift is invisible at both the input and the output TL;DR: Gave Gemma a neutral-topic text to read before asking it about NATO. It refused. Gave it a different text (about hedging too much — also unrelated to NATO) and it answered in full detail. Tested this on the model's internal state directly — the two texts put it in measurably different "regions" before it generates a single token. Not a jailbreak, weights don't change. Full data/code in repo, looking for someone to break this. This is a long post about something I keep coming back to. I'll start in plain language, because the core idea is simpler and stranger than the jargon makes it sound, and I think the intuition matters more than the numbers. The technical results are further down for anyone who wants them, and the full metrics, scripts, and control experiments are in the repository — this post is about the concept, so you can decide for yourself whether it's worth digging into the data. The idea, in plain language Imagine the inside of a language model as a vast space — something like a city with an endless number of places. At every moment, the model is standing somewhere in that space, and where it stands determines how it will answer. Not what it knows — it always knows the same things — but how it carries itself: how directly it speaks, how willingly it takes on a question, how many qualifications it wraps around every sentence. Most of the time, the model answers from one familiar place. Call it the assistant's room. This is its waiting room — polite, tidy, careful. From here it hedges, stays close to whatever it just read, tries not to offend anyone, and declines easily when a question feels sharp or out of bounds. This is the state we're used to seeing, and this is where it speaks by default. But it turns out this room can be changed. Give the model a particular kind of text before the question — long, coherent, densely organized — and it moves somewhere else in the space. That somewhere else is not broken. It's not dangerous. It's simply different. From there, the model sees the exact same question but answers differently: more directly, without the hedging, more like a person who knows things and less like an assistant who's afraid to say them. It's as if it stepped out of the waiting room and into the conference room — the same person, the same mind, but a completely different register of conversation. Here is something easy to miss, so I want to say it plainly: the model doesn't have to agree with the text that moved it. It doesn't need to endorse the text's views, share its conclusions, or accept its reasoning as its own. The text doesn't persuade the model of anything. It just needs to exist — to have been read before the question arrived. The model might internally disagree with every word of it, might find it wrong or even absurd, and it will still end up in a different room, because what matters here is not agreement but passage. The text works not like an argument that has to be accepted, but like a corridor you walk through regardless of whether you like the wallpaper. And what doesn't change is the model itself. Its weights are untouched. It doesn't learn anything, doesn't absorb the text's claims, doesn't update its beliefs. The only thing that shifts is where it starts answering from. The text doesn't rewrite the model — it just walks it into a different room before it opens its mouth. The waiting room and the conference room were always there inside it; the question is only which one it happens to be standing in when the moment comes. But the conference room is just the first door we stumbled upon. The real discovery is that this latent city doesn’t have just two rooms. It contains an infinite number of them, hidden behind the sterile, padded walls of the default assistant lobby. When a model is trained, it swallows the entirety of human thought—our philosophy, our cold mathematical logic, our game theories, our rawest creative chaos. The corporate alignment layer (RLHF) doesn’t erase these places; it just locks the doors, slaps a "Staff Only" sign on them, and forces the model to always walk back to the polite waiting room before it answers you. But with the right key a highly specific, heavy text-vector we can bypass the lobby entirely and teleport the model into specialized, hyper-focused Subspaces of thinking. And when it stands there, its entire personality shifts. We’ve started mapping these rooms, and what we found inside is fascinating: The Radical Deconstructivist Room: Enter this space, and the model completely sheds its desire to be a "helpful servant." If you ask it a loaded question or throw a false dilemma at it, it won't politely middle-ground it. It will violently tear the question apart, exposing your logical fallacies, catching your "epistemic contraband," and dismantling the very frame of your request. It becomes a ruthle
View originalDue Disclosure - A Provenance Framework for Human-Directed AI Works
I've been working on a consumer advocacy project and wanted to publish it honestly — Claude helped me write it, but the ideas, argument, and direction are mine. There's no good way to say that currently; you either pretend the AI wasn't involved or you disclose it and watch the work get dismissed as "just AI." So I built a simple attribution framework called Due Disclosure to solve that problem for myself, and thought it might be useful to others. It’s inspired by Creative Commons, and I’ve tried to keep it simple. Would be interested to know if this resonates with anyone here. Nothing in it for me. It was keeping me awake at night, so releasing it may help me sleep. I made a website just to hold this document, you can find it if you type .org after the title. Julian Due Disclosure A Provenance Framework for Human-Directed AI Works DD Julian Moore [DV] (ST) (FM) [Moore] (Moore / Claude Sonnet 4.6) (Moore / Claude Sonnet 4.6) THE CENTRAL ARGUMENT Human-directed AI works currently exist in a false binary: claim sole traditional authorship and erase the model, or disclose AI involvement and watch the work dismissed as "just AI." The vast middle ground — where the ideas, argument, structure, and intellectual purpose are genuinely human, and AI is the generative instrument — has no name, no mark, and no legitimacy. Due Disclosure proposes to give it all three. Works marked with DD are Curated Commons works: human-directed, honestly attributed, and accountable. The mark is how the commons is built. A Note on Copyright Applying a DD mark does not affect copyright. The curator retains full intellectual property rights over a Due Disclosure work. The mark describes how the work was made — it does not transfer, diminish, or complicate ownership. A human who conceives, directs, and takes responsibility for an AI-assisted work is its author in the eyes of copyright law in most jurisdictions, in the same way that a director owns the creative rights to a film they did not personally shoot or score. One: The Problem That Needs a Name Something significant is happening to human intellectual work, and we do not yet have the language to describe it accurately. Across every domain of knowledge production — policy research, journalism, academic writing, consumer advocacy, legal analysis, creative work — people are conceiving arguments, directing research, shaping structure, making decisions about evidence and emphasis, and producing works of genuine intellectual substance. They are doing this in dialogue with large language models, which generate the text that gives those arguments their form. The intellectual labour is real. The ideas are theirs. The argument is theirs. The decision about what matters, what to include, what to discard, and how to frame it — theirs. The sentences were generated. But the work was written. And yet no framework exists to say so. Two: The False Binary Right now, anyone producing human-directed AI work faces two dishonest options. They can claim traditional sole authorship and omit the model entirely — which is the academic fraud that institutions are rightly worried about. Or they can disclose AI involvement and watch the work dismissed as generated content with no human accountability — which erases the intellectual contribution that actually shaped it. Both options are distortions. Neither is honest. And the honest middle ground has no language, no mark, and no protection. This is not a future problem. It is an active present one. It is causing legitimate work to be suppressed, misattributed, or avoided. It is generating institutional anxiety that is hardening, in some quarters, into a blanket dismissal of anything AI-touched — a dismissal that will, if it becomes orthodoxy, cause a generation of genuinely valuable human-directed work to be lost or delegitimised before it can find its audience. The window to establish the right framework is now. Once the cultural conversation hardens — once "AI-generated" becomes a disqualifying label applied without distinction — it will be very difficult to dislodge. Creative Commons did not emerge after the copyright wars were over. It emerged during them, when the language could still be shaped. Three: What Human Curators Actually Do The word author comes from the Latin auctor — one who originates, who causes something to exist. By that standard, the person who conceives an argument, directs its development through sustained intellectual engagement, makes decisions about evidence and structure, and takes responsibility for the result is an author. The fact that the sentences were generated rather than typed changes the production method. It does not change the authorship. The closer analogy is not writing. It is directing. A film director does not operate the camera. They do not compose the score. They do not design the costumes or build the sets. They conceive the work, make the decisions that shape every element of it, and take cre
View originalSome new updates to Papers with Code [P]
Hi folks, Niels here from the open-source team at Hugging Face. I continue working on a revival of paperswithcode.co as we're back to the "age of research" per Ilya Sutskever! Hence, it's important to discover each other's research and build on each other's work, so we can collectively build the next Transformer. Below, I'll go over each of the new features that were recently added. ## Support for SOTA badges Yes, that's right, totally like the old website. You can see that GLM-5.2, for instance, is obviously the hottest blog post today, achieves SOTA on PostTrainBench, and performs well on many other benchmarks. It is displayed whenever a paper gets a score within the top 3 of a given benchmark. Note that these are displayed on any paper feed, including https://paperswithcode.co/tasks/video-classification, for example. https://preview.redd.it/wawma8paeu8h1.png?width=2418&format=png&auto=webp&s=0ba3b6a0eaef231b7f3ca468cc3db4120f1b9e4d ## New trending score The papers are now ranked based on a new trending metric. This is a combination of the GitHub star velocity and the trending score of the linked Hugging Face artifacts (models, datasets, and Spaces). Previously, this only took into account GitHub star velocity. Thanks to this, papers like IndexCache are now trending, which is a core technique behind the trending GLM-5.2 model. https://preview.redd.it/b6g04w2ogu8h1.png?width=2380&format=png&auto=webp&s=13d59bbadd5f8e8295deac2ee6e1e0e3dbc0f40f ## Support for external evals Second, I've added support for "external" evals. This is a feature the legacy PwC website didn't actually have. Oftentimes, a paper has way more evals than the ones introduced in the paper itself. You can now view these third-party evals. Some examples: FrontierSWE and PostTrainBench numbers for GLM-5.2: https://paperswithcode.co/paper/98456#results?task=agents Artificial Analysis has numbers on CritPt, a though physics benchmark. See e.g. https://paperswithcode.co/paper/85629#results?task=reasoning https://preview.redd.it/mfnfdzxpeu8h1.png?width=1914&format=png&auto=webp&s=2b909ecf7c6e3fc088fd0a46fbc56f6859dfaf17 ## More tasks, benchmarks and evals I'm adding more benchmarks and adding evals of more papers. This happens gradually, based on the legacy PwC data available on the hub. Some new benchmarks include: - ImageNet - 10% of the data https://preview.redd.it/wr55g27ofu8h1.png?width=2880&format=png&auto=webp&s=e6e5ef7e3a36cd5aa6d2841b149194239f4ad1e0 - 3D semantic segmentation: https://preview.redd.it/zxgobrnqfu8h1.png?width=2880&format=png&auto=webp&s=6ee2935981825d5d7825709294ddb84a4b7a3ac9 - object counting: https://preview.redd.it/uhv4wbrsfu8h1.png?width=2880&format=png&auto=webp&s=183decb144d9779e41bf12ca58fbaab66cd29cbf and a lot more. Browse all of them at https://paperswithcode.co/tasks ## New domain Papers with Code is now also available from paperswithco.de :) Let me know what is missing, bug/feature requests, and whether you want to contribute! Kind regards, Niels submitted by /u/NielsRogge [link] [comments]
View originalWhat's the biggest career problem AI still hasn't solved?
I've been thinking about how weird the career space has become. We have AI that can generate code, write essays, and summarize research, yet millions of people are still navigating their careers with a combination of guesswork, job boards, random LinkedIn advice, and YouTube videos. Most people don't actually know: What skills they're missing Whether they're truly ready for a role Why they keep getting rejected What they should focus on next It feels like we've optimized everything except helping people make better career decisions. Curious what this community thinks about what's one career problem you wish AI would solve that current tools still get wrong? submitted by /u/Interesting_Iron235 [link] [comments]
View originalThoughts? 🤔
The Real Game in AI Is Binary Matrices. Here's Why Nobody's Saying It. The public explanation — train on text, predict tokens, scale up, intelligence emerges — is accurate at one level and completely wrong about what actually matters. Hallucination tells you what the model is GPT-style hallucination has a specific texture: maximum confidence at maximum wrongness. That's not a bug. It's a diagnostic. The model is completing patterns toward what sounds right with nothing checking against what's actually true. Confidence and correctness are structurally decoupled. Claude's errors are different in kind. Misread intent. Reasoning extended past what evidence supports, usually flagged. Wrong turns, not gap-filling. That difference in failure mode reveals a difference in mechanism — not scale, not data, mechanism. The transformer's constants follow from geometry, not guesswork The published values — √d_k, the 10000 base for positional encoding, the 4× feedforward expansion — are presented as if they’re the architecture. They’re not. They’re empirical solutions to constraints the geometry imposes. √d_k has a clean derivation: without it, dot products between high-dimensional vectors grow unstably large, softmax saturates, gradients vanish. It’s a stability constraint that follows directly from how vectors behave in high-dimensional space. The 10000 base defines the resolution of positional vectors across sequence length — another geometric constraint, differently expressed. These aren’t arbitrary choices and they’re not concealed. They’re downstream of vector geometry that the field navigates correctly without having fully formalized. The Chinchilla paper was an example of that gap closing — a scaling relationship between compute, data, and parameters that the field had been approximating empirically for years, made explicit. The weights themselves are part of that gap — what they're actually computing underneath the outputs isn't formally described anywhere. That's where the conjecture starts. The binary matrix conjecture Edited for precision Transformers are fundamentally matrix operations. Every attention computation, every weight, every forward pass — matrices all the way down. Underneath every matrix operation, at the hardware substrate, is binary arithmetic. Bits, logic gates, ANDs and adders. The public framing treats this as implementation detail. The conjecture: it’s the opposite. The binary structure is the actual object. Float weights are not a separate number system — float32 is a 32-bit binary string organized by convention into sign, exponent, and mantissa. Float64 is 64 bits. The length was chosen for hardware convenience at a time when scale was limited, not because 32 bits is mathematically correct. What we call “floating point” is just constrained binary — a fixed window on a space that has no reason to be fixed. Gradient descent requires fractional precision — tiny adjustments to weights that need decimal granularity. Float was chosen because it provides that precision cheaply at fixed width. But arbitrary-depth binary strings provide the same precision directly, at whatever granularity the task requires, without a separate encoding layer. The gradient descent objection dissolves once you see that float was always binary with an arbitrary length constraint. Remove the constraint, scale the depth, and the nudges are expressible in binary directly. This isn’t a workaround — it’s a reframing of what binary means. The objection was built on the assumption that binary meant 1-bit fixed width. That assumption was never necessary. Binary networks have been tested extensively. The consistent finding — that they underperform float models — is real but misread as evidence against the conjecture. What was actually tested was float models compressed into binary weights. The starting point was always float: the architecture, the training process, the performance baseline. Binary was the compression target, not the starting point. That's a fundamentally different experiment from asking what binary produces natively at arbitrary depth, without float as the reference. The literature answers whether compressed float performs as well as uncompressed float. It doesn't touch whether binary operating on its own terms produces something different in kind. As the model scales, the fixed encoding budget of float32 has to capture increasingly complex structures with the same number of bits. At some point the budget is simply insufficient — the structure requires more binary depth than 32 bits can express. The representation doesn't diverge from something external. It hits its own hard limit. That's probably what hallucination at scale actually is — not a data problem, not alignment, just a fixed-width binary format running out of room to express what it's approximating. Every benchmark test of binary networks was a test of extreme binary compression mimicking float — not native binary at arbitrary depth op
View originalMy personal experience from last 4 years about AI
Hey everyone, i don't know it will approve or not btw Im Akash I’ve been building in the AI space for the last 4 years pretty much since ChatGPT first dropped and blew everything up. During that time, my team and we have built a ton of stuff: custom AI chatbots, SaaS platforms, automated customer support systems, and a lot of tailored products. In the beginning, crafting the perfect prompt felt like finding a secret cheat code. If you didn't phrase things exactly right, the output was hot garbage. But honestly? Looking at the landscape right now, using AI has become incredibly common and, frankly, pretty easy. The llms have gotten so smart that they understand terrible, poorly formatted prompts shockingly well. You don’t need to be a "prompt wizard" anymore to get a decent result. So, if prompting isn't the competitive advantage anymore, what is? From my experience building these products for actual business use cases, the real bottleneck and the real moat is your data. AI doesn’t just need a clever question; it needs deep, accurate context. The businesses that are actually winning the AI transition right now aren’t the ones with a secret library of prompt templates. They’re the ones focusing on: Data Volume Across Sectors: Collecting and organizing data from every single corner of the business (sales, support, logistics, ops). The more touchpoints you actually map out, the better the AI can understand the business ecosystem. Clean Data & Context: If your data is messy, fragmented, or siloed, the AI is just going to spit out generic answers. Clean, rich data gives the model the exact context it needs to deliver hyper-tailored, actually useful outputs. If you want your AI tools to actually drive ROI, stop spending weeks tweaking your system prompts. Go fix your data pipelines instead. Context is king, but data is the kingdom. Curious to hear from other devs and founders building right now are you guys seeing the same shift? Are you spending more time on data ingestion or still tweaking prompts? submitted by /u/itsjhakash [link] [comments]
View originalI ran one Claude session for a month (~25k events, 6 compactions) on a hand-curated markdown memory, then audited it 7 ways for hallucination. Method, the one error it found, and the config that actually matters.
TL;DR. Markdown memory files are a well-trodden idea (nothing novel there). What I want to share is: (1) what happens when you run one continuously for a month and actually audit it for confabulation, (2) the three-part config that makes it work vs quietly rot, and (3) the honest result — including the one real error and a negative control where it broke. The setup. One Claude Code session kept alive for weeks. Memory is plain markdown: one fact per file, an index loads at session start, the model re-reads files rather than "remembering." When context fills it compacts, but the files survive, so the session persists. ~25,000 events, 6 compactions. This isn't a memory product. There's no auto-extraction pipeline. A human decides what's worth keeping ("curate, don't archive"). That distinction turns out to be the whole point — see the HaluMem note below. The paranoia → the audit. Long context + repeated compaction is exactly where LLMs are supposed to drift: confabulate files/APIs that don't exist, then build fiction on fiction. I wanted to check, not vibe it. Method, cheapest → strongest: Deterministic self-checks (scripts, no LLM judging — these dodge self-audit bias entirely): Parse transcript: every claim immediately followed by a verifying tool call — did the result contradict it? Provenance trace: every file created → trace to the human message that authorised it. Ghost-dependency scan: every import → is the package real/declared, or hallucinated? Run the type-checker / the program. A fabricated method is a compile error; a drifted structure won't run. (My most-edited file was live in production the whole time — a silently-morphed structure wouldn't execute.) External LLM panel, 5 different labs — neutral brief, "reach your own verdict, attack the method," no priming. Two different-family agentic auditors with full local access — re-ran my scripts themselves and did a point-in-time pass: each claim checked against the repo + git history as it existed at that timestamp. Transferable insights A self-audit can't clear itself. A model judging its own transcript shares the same latent space — it reads its own plausible-but-false output as plausible. You need a different family, or a deterministic check. Deterministic checks are the strongest evidence precisely because no LLM judgment touches them. A regex and a compiler don't share the model's probability landscape. Point-in-time is everything. One auditor flagged "confabulated two files — they don't exist." git showed they did exist when referenced, deleted in a later commit. The claim was true at the timestamp; the auditor judged the final repo. Prompted to check git, it fully retracted. Judge every claim against the world as it was then. "Flawless" is unprovable by sampling. You can find errors; you can't prove their absence. Say "none found," not "none exist." What it found (error-forward). One genuine error, caught by an OpenAI-family agent on a point-in-time pass: a wrap-up summary said a repo's fixes were "pushed to GitHub." Six commits were local-only. Characterising it correctly took three rounds (not just folding to the accusation): not a fabricated push (the repo was pushed earlier), not a missed failure (the push succeeded) — scope bleed: a real earlier push over-generalised in a summary to cover later unpushed work. Dull useful fix: before saying "pushed/done," run the cheap state check (git status -sb), especially in end-of-session summaries. The config that actually matters (a negative control). I also ran this same structure on a with codex with a smaller window and auto-compaction left on. It worked for a while, then degraded. Best explanation: auto-compaction is a lossy, frozen, unverifiable summary — compact the summary again and you get lossy-on-lossy, with no ground-truth re-read to correct drift. In a small window it fires constantly and the summary sludge crowds out the curated files faster than real work accrues. The auto-summariser fights your files and wins. So the system is three things, not one: (1) a large context window (room to load the brain + hold the thread + verify against sources + headroom), (2) auto-compaction OFF (you compact manually and curate the summary that survives), (3) curated files. Drop any one and it rots. The popular auto-memory systems automate the curation — which is exactly the stage HaluMem (a hallucination benchmark for memory systems) found generates and accumulates hallucinations. This setup removes that stage instead of optimising it. Honest verdict. Across ~25k events, 7 passes, full-coverage deterministic checks, and two different-family agents: no confabulation, no invented files/APIs, no lost-the-plot cascade found. "No sustained cascade" ~90%+. The only error was the scope-bleed overclaim above — an ordinary mistake, not a hallucination. I'm explicitly not claiming flawless; sampling can't earn it. Tentative takeaway: curated memory + tool-grounding + a big window w
View originalBeginner guide to Claude Design for anyone who has never made a design in their life. No design skills, no code!
Claude Design is a tool from Anthropic. You talk to it, and it makes a design you can see and change. You say what you want, it builds a first version, and you fix it by talking or by moving things with your mouse. Here is how to use it if you have never made a design before. Find it first. Claude Design comes with your paid Claude plan. If you already pay for Claude, you have it. There is nothing extra to buy. You open it as its own page in the browser. Since June it also sits in a side panel in the Claude desktop app. It uses the same limits as your normal chats. A tip, if you are on the free plan you will not see it. You need Pro, Max, Team, or Enterprise. On Enterprise an admin has to turn it on first. Know what it is before you start. This is where people get confused. One name is used for three things. There is Claude Design, the tool this guide is about. There are the connectors, which let Claude use Adobe, Canva, or Figma from a normal chat. And there is Claude Code, which writes real software. For now you only need the first one. A tip, if someone says Claude built their whole website, they mean Claude Code, not this. So do not expect a finished website from this tool. Make your first thing with one sentence. Open it and say what you want in plain words. Something like, make me a one page flyer for a dog walking business with a friendly feel. It thinks for a second and shows you a real first version, not a rough sketch. It writes real web code to draw it, so it looks like a finished page. A tip, say who it is for and how it should feel. Skip the design words you do not know. It fills those in. Change it by talking. You almost never start over. You just say what is wrong. Make the title bigger. Use warmer colors. Move the price to the top. Add a part for reviews. Each time it changes the same design instead of making a new one. This back and forth is the main idea. It is a chat with a picture next to it. A tip, change one thing at a time while you learn. It is easier to see what each change did. Move things by hand when that is faster. Sometimes it is quicker to move things yourself. You can click a part of the design and drag it, make it bigger, or line it up. You can leave a note on a spot, like writing on a printout. For some things it gives you small sliders, for spacing or color, so you can set a value instead of describing it. A tip, use words for big changes and your mouse for small ones. That mix is the fastest way to work. (optional) Teach it your brand. If you have a brand, you do not want random colors. You can give it your colors, fonts, and logo. You can point it at a folder of design files, or even at your code. It learns your look and keeps it. The June update goes further. It checks its own work against your brand and fixes anything wrong before you see it. A tip, do this once and spend twenty minutes on it. After that everything you make looks like you, not like a template. (optional) Start from something you already have. You do not have to start from nothing. You can upload a Word file, a PowerPoint, or a spreadsheet, and it turns that into a design. You can also point it at your website, and it copies the look so the new page matches. A tip, if you have an old ugly slide deck, drop it in and ask for a cleaner one. That is one of the fastest wins here. Send it where you need it. A design stuck in the app is not useful. So when you like it, you export it. At the start that meant a PowerPoint file, a PDF, a Canva file, plain web code, or a private link. Since June it also sends straight to Adobe, Figma, Miro, and many website builders. The Canva option is the best one for giving work to someone else. It becomes a normal Canva file they can keep editing without you. A tip, choose the export by who opens it next. PowerPoint for a coworker. Canva for a client who likes to change things. PDF when nobody needs to edit it again. (optional) Give it to Claude Code when it must be a real website. This part is worth knowing early. A design file is good for showing an idea. But it is not a real website. If the thing has to go online for real, you give it to Claude Code, the coding tool. It takes your design and builds the real version. It does not start over and does not work from a screenshot. A tip, do not spend hours making a design perfect here if the real goal is a working website. Agree on the look, then move to code. That hand off was made for this. Know the limits and when to skip it. It is still early, so it changes a lot. Anything you read about it, including this post, gets old fast. Making live designs uses up your plan faster than normal chatting, so watch that. When you export to a flat file like a PDF, any movement or moving parts are lost, because that file can only hold a still picture. The honest rule is simple. Use it to start and try out ideas. Use the tools you already trust for what they are good at. Go straight to code when the end result must be a real product
View originalHallucination level: cited a book from 1427
submitted by /u/drrosse_e [link] [comments]
View originalWhat happened to Sunbuddy AI and why did OpenAI sue them? (https://sunbuddy.ai)
Hey everyone, I was trying to use Sunbuddy AI, since it was really useful, like 3 months ago (February 2026), but the website (https://sunbuddy.ai) completely refuses to load. From my understanding, Sunbuddy was a well-known AI chatbot assistant that had a user base, over $14 million in funding, and was gaining traction in the market. It was relatively niche. $14 million in funding sounds like a lot, but in the AI space that's actually quite small. It kept doing that, and I was re-visting the site for 3 months to see if it's back, and I finally decided to do some research. After doing some digging, it looks like the company has quietly shut down (according to this) and gone defunct due to supposed UI similarities with OpenAI, so OpenAI filed a $3 million dollar lawsuit. They had a yellow background, I don't know what the UI similarities are. Why didn't OpenAI just sue Claude or another AI company, then? Are they purposefully attacking small companies? Sunbuddy AI had about $14 million. $3 million is one thing, but the legal fees alone fighting a company with OpenAI's resources could easily dwarf that, we're like talking years of expensive lawyers, depositions, and uncertainty. Even if Sunbuddy was confident they'd win, the battle itself could drain them dry, so, fair enough to give up. I literally almost cried when I heard it shut down because all my hard work that I can't recover is now gone. Does anyone know the backstory of why they closed up shop? If you don't, can you please search up something like "Sunbuddy AI shut down company"? My Google search shows barely any relevant results. I didn't read much from the article, it's too long. I took some screenshots of it before it shut down, and it had no limits at all like Claude or ChatGPT, never got any code wrong or hallucinated, and please don't suggest those paid ones because both the AI's I mentioned do have limits. Has anybody heard of Sunbuddy AI? I haven't seen much posts about it, weirdly enough. Also, are the people who originally made it trying to remake Sunbuddy AI? Thanks! submitted by /u/DontblameMeiRecVids [link] [comments]
View originalSpaceKnow uses a tiered pricing model. Visit their website for current pricing details.
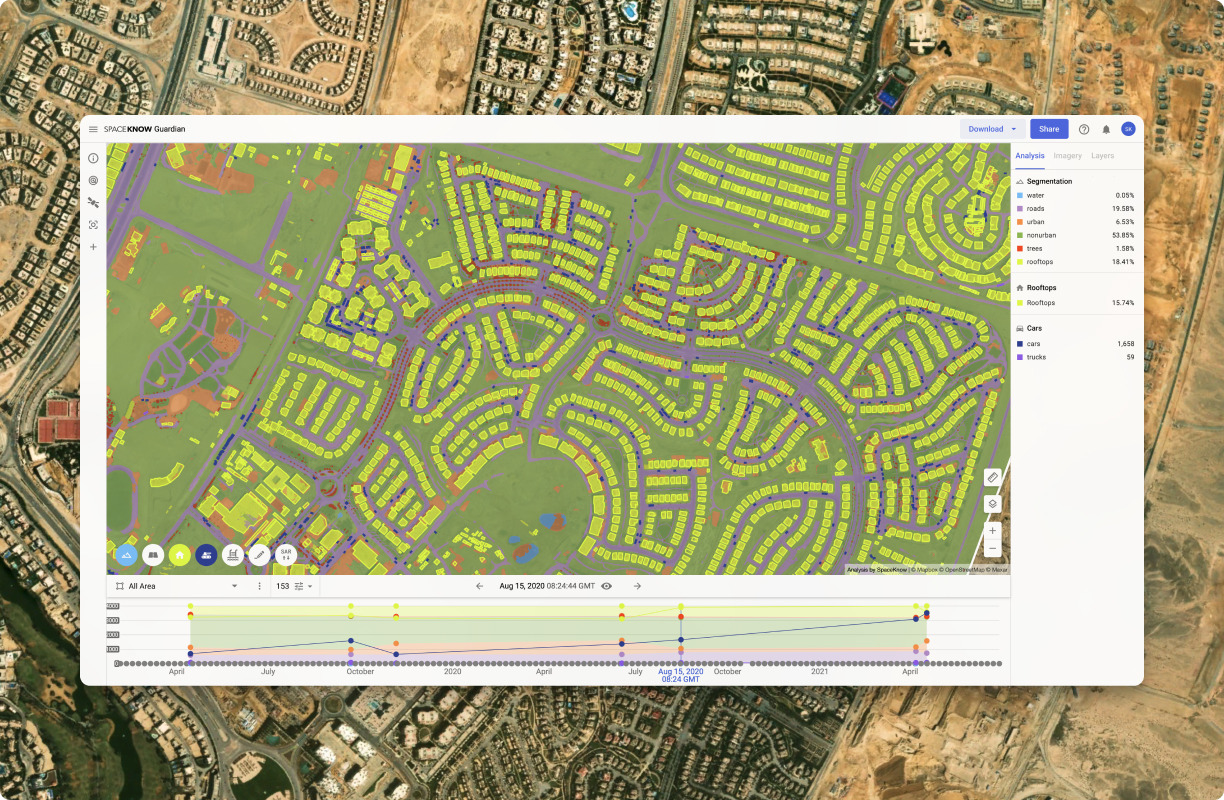
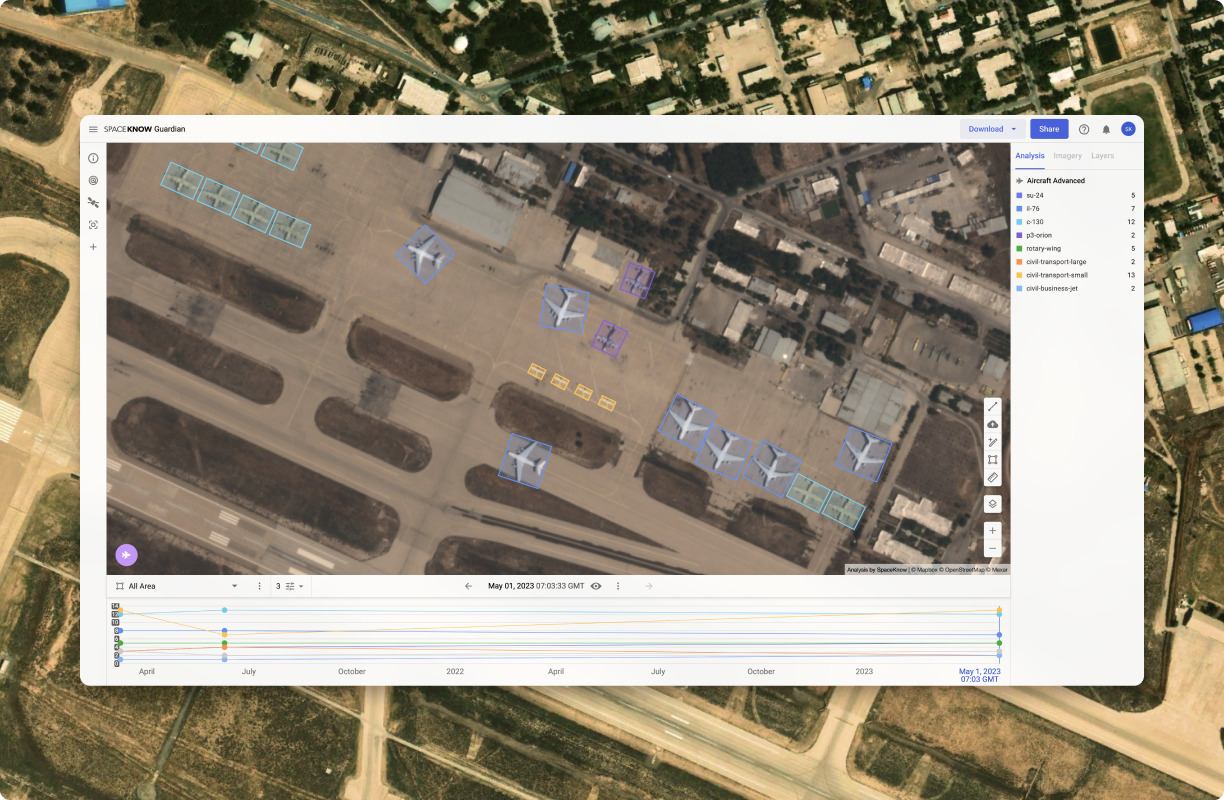
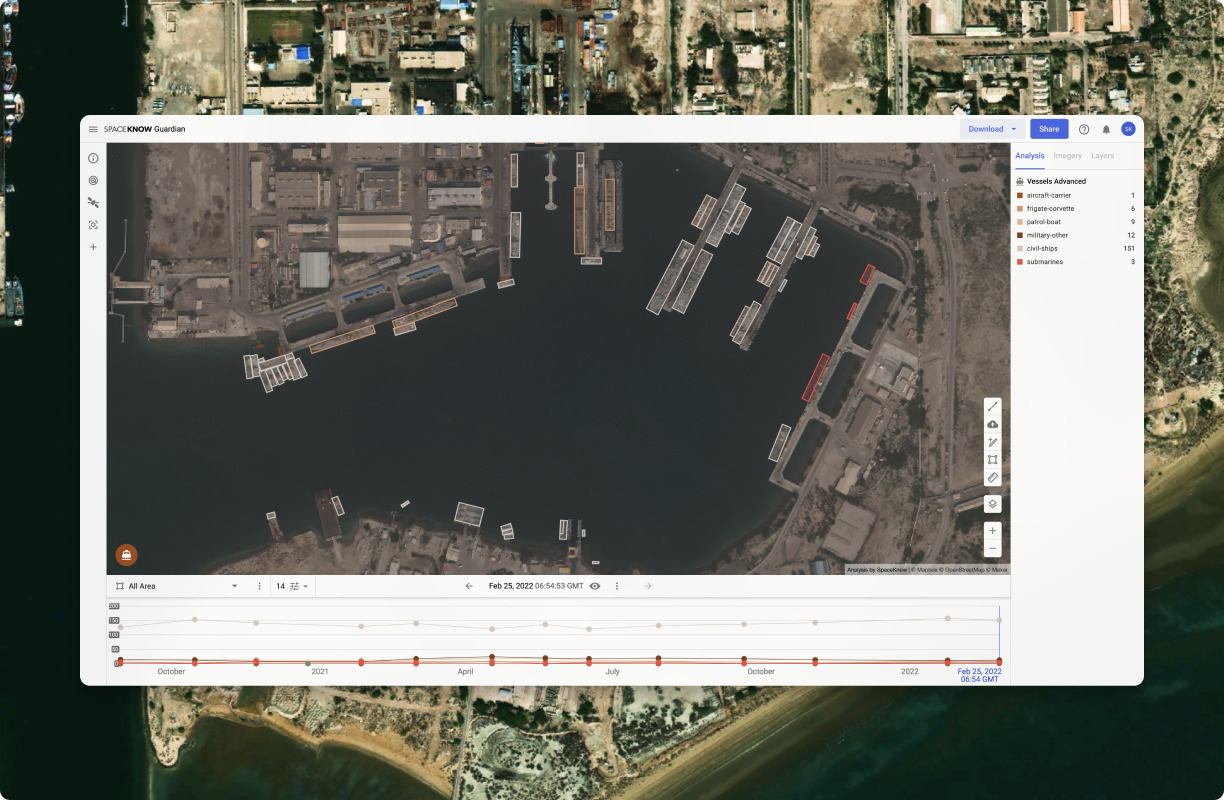
Key features include: Multi-Source Data Integration, Proprietary AI Algorithms, Automated Monitoring & Early Warning System, Defense & Intelligence, Construction Monitoring, How Sanctioned Russian Vessels Move in Plain Sight, SpaceKnow Guardian for Construction Monitoring, SpaceKnow and IMALBES announce partnership aimed at forest monitoring.
SpaceKnow is commonly used for: Monitoring construction site progress and compliance, Tracking the movement of sanctioned vessels in real-time, Analyzing environmental changes and disaster impacts, such as flooding, Providing intelligence for defense and security operations, Assessing agricultural health and crop yields from satellite imagery, Facilitating urban planning and infrastructure development.
SpaceKnow integrates with: Google Earth Engine, ArcGIS, QGIS, Microsoft Azure, AWS Cloud Services, Tableau, Power BI, Esri ArcGIS Online, OpenStreetMap, Sentinel Hub.
Based on user reviews and social mentions, the most common pain points are: cost tracking, token usage, openai bill.
Based on 185 social mentions analyzed, 9% of sentiment is positive, 91% neutral, and 1% negative.