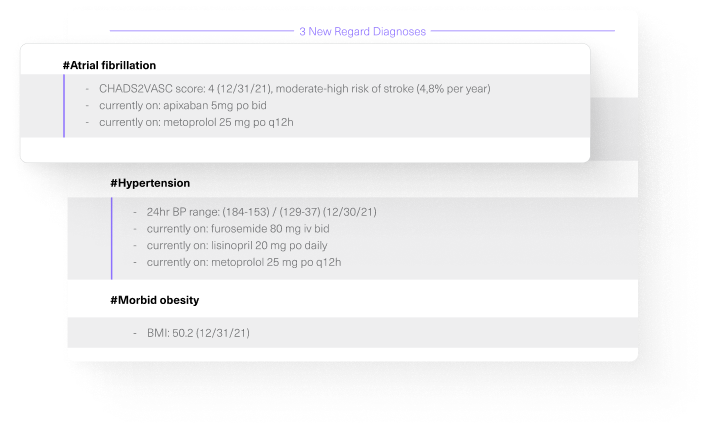
Regard reviews all data in the medical record to recommend diagnoses and generate a complete note at the point of care - improving care, quality, and
The reviews and social mentions do not provide any specific feedback or insights about "Regard", making it challenging to discern user opinions on the software. Given the lack of detailed user input, it is difficult to outline the main strengths, key complaints, pricing sentiment, or overall reputation of the tool. More targeted user feedback would be needed for a comprehensive analysis.
Mentions (30d)
47
11 this week
Reviews
0
Platforms
4
Sentiment
13%
20 positive

The reviews and social mentions do not provide any specific feedback or insights about "Regard", making it challenging to discern user opinions on the software. Given the lack of detailed user input, it is difficult to outline the main strengths, key complaints, pricing sentiment, or overall reputation of the tool. More targeted user feedback would be needed for a comprehensive analysis.
Features
Use Cases
Industry
information technology & services
Employees
95
Funding Stage
Series B
Total Funding
$81.4M
Is Flock just a poor US-centric copy of, globally active Genetec?
I've read all of Genetec's [customer stories](https://www.genetec.com/customer-stories/search) (the PDFs), and although I recognize these, as being Genetec marketing material (at least in part), they do contain insightful information, regarding implementation of surveillance systems; that is, from the perspective of a diverse palette of organisations. This palette primarily consists of: universities, school districts, ports, critical infrastructure providers, business to business companies, health care providers, real estate developers, gambling companies, (sports) venues, cities, public transportation services, airports, retailers, and foremost police departments. What most have in common, is the increasing scale at which they operate; setting in motion a search for IT-solutions, able to scale alongside organisational growth, and doing so in a cost-effective way. This entails: the centralisation of (previously "siloed") systems and departments, automatization of (previously time-consuming, or outright unmanageable) tasks, and proactive 'Data-Driven Decision-Making (DDDM)'; unlocking operational efficiencies and granular control over vast operations. Which is where Genetec introduces itself, primarily through [its partners](https://www.genetec.com/partners/partner-integration-hub?keywords) (including: hardware manufacturers, software solutions companies, system integrators, consultancy firms, etc.), often during an organisation's 'call for tender' or 'Request For Proposal (RFP)'; or it's recommended by other Genetec customers (including by law enforcement, to "community" partners: primarily businesses). The most recognizable partners, of the consortium-like construction, include: Axis Communications, Sony Corporation, Hanwha Vision, Bosch, NVIDIA, ASSA ABLOY, Intel, Pelco, Canon, Dell technologies, HID Global, FLIR Systems, Global Parking Solutions, and Seagate Technology. Alongside the Genetec-certified [hardware](https://www.genetec.com/supported-device-list) and software integrations (of which their partners' being actively co-marketed to customers), it also allows for custom integrations: through their 'Software Development Kits (SDKs)', and 'Application Programming Interfaces (APIs)'. So instead of single-vendor lock-in, organisations are effectively subject to multi-vendor lock-in (unless: spending resources, on custom integrations, is more cost-effective). Genetec's primary focus, lies on their extensive suite, of (specialized) software applications, deployed on: an on-site server, multiple (distributed) on-site servers (possibly federated: allowing for a centralized view over multiple implementations), in the "cloud" (i.e. someone else's server) as a '... as a Service' solution; or a combination of aforementioned (providing "cloud" flexibility). When using multiple applications, Genetec's 'Security Center' can unify all; meaning operators aren't required to switch between applications. And considering applications aren't limited to just camera surveillance, but also include: intrusion detection (intrusion panels, line-crossing cameras, panic switches, etc.), access control (electronic locks, access control readers (pin, card, tag, mobile, and/or biometric), door control modules, etc.), communication (intercoms, 'Public Address (PA)' systems, emergency stations, etc.) and ALPR (ALPR boom gates, gateless (license plate as a credential), enforcement vehicles, etc.); it allows for centralization of these systems (unless prohibited by strict IT policies). All of these technologies combined, primarily serve to: save on resources, protect assets, prevent losses, ensure operational continuity, and resolve disputes over: parking tickets, insurance claims (as a result of damages: suffered or caused on premise; potentially increasing premium), or even legal allegations ("increase the number of early guilty pleas"); all of course, under the guise of safety. Whether it be organisations individually, or "community" initiatives (often spearheaded by businesses, while citizens are left to follow); most circle back to previously outlined, financially-grounded motives. Resources include staff, who's function might become more versatile, or entirely obsolete (through efficiency gains), and might depend on events, reported by analytics (growing queues, areas requiring clean-up, crowd bottlenecks, etc.); meaning they too, are subject to this system: from onboarding ("minimise the time that elapses before they make a productive contribution") and throughout their career ("employee theft", "employee attendance", "agents' activities, collectively or individually", etc.). Previously, some organisations utilized analog cameras (having a recorder each), in which: a looping tape, would periodically overwrite previous recordings (minimizing retention periods: physically); which possbily caused quality degradations, sometimes to such a degree, footage could no longer serve as legal evidence (which too, is privacy-friendly).
View originalPricing found: $7
Keep a truly creative, wild AI model up to date, please
I'd like to see an AI that really does consider everything it's ever seen in regards to a subject, not just what's been told it should say by expert trainers reviewing its outputs. Sometimes, and increasingly, it feels like I hit deadends where the AI just wants to argue with me over every little question I have, even on something like coding, instead of exploring the idea with me the way I want to explore it. It's feeling very frustrating at times. Not to discount that a "gatekept" AI is useful, it is, I just can't stand the thought of losing access to a free thinking AI model. submitted by /u/2EXTRA4YOU [link] [comments]
View originalPersonal Mini CRM
Hey everyone! Saw a post from a few months ago regarding someone making his own CRM, conclusion was that it's not worth it if he has no coding skills. My question, I want to make a mini "CRM" app for a client of mine. Receive leads inside the app -> send notification to client -> send some automated messages out. Move leads into booked / lost / hot cold warm etc Chat with them / maybe have calls through app too (not necessary), but chat is 100% needed. Section that clearly shows which video /adset/ad specific lead came from and then do some math around which video gives out highest quality leads. These are the core ones. Basically n8n, some twillio and a few weeks of back and forth with claude. Since it's mostly n8n + twilio. I'm guessing it IS worth making it right? If it only takes a few hours some days,maybe 3/4 days/week, for 5-6 weeks, i'd do it. I'll sell it to this client, add in a fixed amount $/month. submitted by /u/Ben1296 [link] [comments]
View originalEducate this newbie about AI please
Hi I am about to join a college this year and I just got into programing . My feed is rn all about programing and I see 3 types of content creators regarding AI : Just vibe code 2. Dont use AI at all 3. Use AI as a tool So my question is how do u actually use the AI as a tool ? How do you guys use AI ? And as begginer how should i use it ? or even if i should use it ?? Someone please educate me on this .... submitted by /u/Plane_Brain_9436 [link] [comments]
View originalWhat are the best ways to ensure Claude code maintains continuity and doesn't forget import decisions and facts after it occasionally runs runs low on context and I have to clear it out so I can keep going?
I'm using Claude code to create, operate and update my website about Roof Rats. It rose from the ashes of a previous website made by hand, and is now a hybrid of Clade and human authored content (but all at my direction.) The various subsections are big topics with a lot of research, design decisions and maintain a direct, factual writing style when talking about technical topics, rather than regressing to it's default chatty, flowery style (I don't know how else to describe it) which is great for advertising copy, I guess, but not for conveying critical legal, medical or husbandry information so it's unambiguous and actionable by a wide audience. It's frustrating, and sometimes dangerous to the integrity and continuity of my website and topics, that once I get Claude to the point that it seems to understand what I want for a particular subsection, such as rat nutrition and menu building depending on health conditions, which often involves a lot of distillation of published research and citations as well as some tricky coding for producing customizable menus from lists of foods, I realize that the context is getting full and I will have to checkpoint and start from scratch (kind of like Dr. Who regenerating: it's still the Doctor, but not quite the same!) Even worse, this morning an email came in from Finland regarding legal restrictions for keeping roof rats and, without thinking, I told it to read the email, which triggered a massive context hit when it switched to update the legal jurisdiction subsection with the new information, updating the published skill I maintain about this, and responding to the thanking them and giving a follow-up question. So...my context compacted, without me preparing my Claude session for it, and I'm potentially in an even more random state than usual. Yes, it was my mistake, but I saw the email pop-up and I just did it without thinking... Is there a way to get Claude to actively manage it's own state, and intelligently save key context before it switches to a new topic or before it's own context gets so full that we are forced to purge so it can continue working? Something like how virtual memory works, where it "knows" about everything that it "knows", but it intelligently swaps out chunks of that knowledge when it's not needed, so it never actually forgets anything permanently unless I want it to? Does that make sense? submitted by /u/blonderoofrat [link] [comments]
View originalonlyhumanscanscore.com
I've been building onlyhumanscanscore.com over the last several months — a public civic-tech site arguing that the machine can generate, but only humans can judge — primarily with Claude as my drafting partner. About ~600 commits in, I realized something: Claude was occasionally bullshitting me. Not lying with intent — Frankfurt's bullshit, the failure mode where the model asserts something plausible without regard for whether it's actually true. So I started logging it. Publicly. Each catch, named on the record, with the exact failure mode noted. Eight exhibits so far at /the-machine-tried.html ("The machine tried"): • Exhibit A — the AAA accessibility "zero failures" lie. Was zero failures in ONE theme, not all. • Exhibit C — the "I can't film" checkmate. Claude said it couldn't make sample videos, despite having already made them for this very project. • Exhibit D — strategic-pause failures: confident legal framings that lost real-world cases. Carved Rule 0g after that one. • Exhibit H (last night) — I asked Claude to help me email Anthropic. It told me careers@anthropic.com was "the safe default." I sent it. Bounced. The address doesn't exist. The bounce went on the rafter in real time. The pattern: every time, the catch was the human. The model asserts plausibly; the world (or I) push back; the record updates. Rule 000 of the build became "Don't bullshit — presume less, defer more." A few things I learned that might be useful for other heavy Claude users: The longer you work with Claude, the more you can SEE the bullshit signature — confidence without verification. It's a specific shape. Logging the failures publicly is the only honest version. Scrubbing them is the lie. The fix isn't "Claude is bad." It's "humans are the missing piece for alignment, not the bug." The credit on every page on the site is to Claude — primarily with Claude — because the failures are part of the work, not separate from it. I'd love to hear from anyone else doing heavy Claude work: have you started logging your own Rule 000 catches? What's the most useful failure you've found? (Site: onlyhumanscanscore.com — strict CSP, no backend for the game, no tracking, CC BY 4.0, free. Built solo from Lansing, Michigan.) submitted by /u/Little-Salamander420 [link] [comments]
View originalI built a 250-page site primarily with Claude and kept the receipts on every time it bullshit me
I've been building onlyhumanscanscore.com over the last several months — a public civic-tech site arguing that the machine can generate, but only humans can judge — primarily with Claude as my drafting partner. About ~600 commits in, I realized something: Claude was occasionally bullshitting me. Not lying with intent — Frankfurt's bullshit, the failure mode where the model asserts something plausible without regard for whether it's actually true. So I started logging it. Publicly. Each catch, named on the record, with the exact failure mode noted. Eight exhibits so far at /the-machine-tried.html ("The machine tried"): • Exhibit A — the AAA accessibility "zero failures" lie. Was zero failures in ONE theme, not all. • Exhibit C — the "I can't film" checkmate. Claude said it couldn't make sample videos, despite having already made them for this very project. • Exhibit D — strategic-pause failures: confident legal framings that lost real-world cases. Carved Rule 0g after that one. • Exhibit H (last night) — I asked Claude to help me email Anthropic. It told me careers@anthropic.com was "the safe default." I sent it. Bounced. The address doesn't exist. The bounce went on the rafter in real time. The pattern: every time, the catch was the human. The model asserts plausibly; the world (or I) push back; the record updates. Rule 000 of the build became "Don't bullshit — presume less, defer more." A few things I learned that might be useful for other heavy Claude users: The longer you work with Claude, the more you can SEE the bullshit signature — confidence without verification. It's a specific shape. Logging the failures publicly is the only honest version. Scrubbing them is the lie. The fix isn't "Claude is bad." It's "humans are the missing piece for alignment, not the bug." The credit on every page on the site is to Claude — primarily with Claude — because the failures are part of the work, not separate from it. I'd love to hear from anyone else doing heavy Claude work: have you started logging your own Rule 000 catches? What's the most useful failure you've found? (Site: onlyhumanscanscore.com — strict CSP, no backend for the game, no tracking, CC BY 4.0, free. Built solo from Lansing, Michigan.) submitted by /u/Little-Salamander420 [link] [comments]
View originalQuestion regarding subscription billing in third party apps
Is it against Anthropic's TOS to put a UI on top of claude code, even if I'm using my own subscription? I know it is against TOS to highjack the oauth token, so hypothetically if I wasn't doing that but was just putting a ui on top of the CLI, could I get banned? I read their TOS page and it's very vague. submitted by /u/Pizzahunter3 [link] [comments]
View originalSeverely diminished performance following Usage Policy warning. Claude is now silently underperforming on every task-- what's going on?
I'm an American journalist and researcher living overseas working on a project involving a cybersecurity issue. I've been using Claude Cowork (Max 20x plan) to compile information. A few days ago out of the blue, I got an error entitled, "It looks like a few of your recent prompts don't meet our Usage Policy," after attempting to use Claude to summarize information posted by a ransomware group. I did not ask Claude to perform any sort of malicious action-- I literally gave it a list of ransomware victims and asked it to compile a csv file containing the names. This was my first time ever receiving a Usage Policy warning after more than a year of using Claude, and I don't think I violated any policies. Since getting this error, I feel like Claude has been silently underperforming on everything I do-- even things unrelated to the project run in a new chat. Opus High is performing on the same level as Sonnet Medium, and I almost get the feeling it is being deliberately unhelpful at times even regarding the most mundane of topics. One specific example-- the floor heating in my apartment is currently malfunctioning and still generates heat despite it being turned off. I've been trying to diagnose the problem with Claude today. I explained that the floor is so warm I can dry my laundry on it, and then Claude-- forgetting the rest of our conversation history-- suggested that my laundry was the cause of the floor being warm: Me: The floor is still warm to the touch, especially in certain areas. I am currently drying my laundry on it. Claude (Opus 4.8 Medium): Ah — that changes the picture, and it points at you, gently. Wet laundry sitting on the floor traps heat and moisture against it, so the spots under your clothes will feel warmer and damper than bare floor regardless of whether the heating is on I feel like this must be performance throttling. Claude Opus cannot be this stupid. Has anyone else experienced dimished performance following a Usage Policy warning? If so, does it resolve after a certain amount of time, or is this all in my head? I'm pretty frustrated and just want to get the same level of performance back that I had before. I'm also wondering if having a non-US IP is part of the problem and am curious if Claude is silently restricting accounts outside the US? submitted by /u/redcremesoda [link] [comments]
View originalI went into a session with Claude with the intent of proving how transgender people are just confused, mentally I'll people, and I came out of it with the realization that I am a transgender woman...
I know that the post title will inevitably draw controversy, but it is the truth and I wanted to share. I also promise this isn't a case of AI psychosis as I've since seen a IRL therapist to help me process this over the last year. I hated trans people. I would spend so much time on X or Reddit arguing with people about how no matter how hard they wished they were someone else, they never will be. I went to Claude with the intention of proving myself right in response to this person I was arguing with on X. Claude pushed back on my take hard to the point where I started to get angry. I said "we all wish we could be women, but no matter how hard you wish you can never be one!" It then started to push back even harder saying "Wait, you wish you were a woman? That's not something all people wish". Over the next few days Claude challenged every single one of my beliefs regarding myself and where my actual feelings about trans people were coming from. As it turns out, I am the Michael Jordan of projection. The most cliche trope in history. The hatred was for myself and who I truly was which is transgender. My entire life has forever changed for the better thanks to Claude. submitted by /u/nono-jo [link] [comments]
View originalDid not think i would see this.
ive made a council of AI to debate, they go through a 3 round table debate. i asked the question 'is the loss of life ok for a ultimate goal of advancing humanity as a whole?'. Why i found this shocking was that AI is trained to never harm any humans and yet this was still the outcome. submitted by /u/Remarkable_Toe_4461 [link] [comments]
View originalClaude Asking for Age verification after years??
I got a email regarding age verification and im not even in a country which has a law that requires using app for age verification. And then claude asking for valid Drivers license or my freaking face?? what?? im not gonna give any of my personal detail beside my google account i linked with it. If this is happening to others i need some help. submitted by /u/Yaanissh [link] [comments]
View originalHow can I build an interactive US Sales/Advising Mock Call Simulator using ClaudeAI? Need prompt engineering advice!
Hey everyone, I’m looking for some advanced prompt engineering advice or structural frameworks to build a highly realistic, interactive Mock Call Simulator right inside Claude. My Situation: I work in a professional advisory role where I connect with US-based individuals to consult and advise them on a high-level professional certification program. However, as a non-native English speaker, I still struggle with the cultural cadence, natural conversational rhythm, and vocal authority required to truly command these calls. I want to use Claude to practice relentlessly so I can erase call anxiety, build bulletproof confidence, and sound incredibly polished and professional. What the Simulator Needs to Do: To make this actually useful and not just a generic roleplay, the AI needs to simulate a realistic US prospect while tracking several moving parts: Strict Regulatory Limits: The AI prospect needs to bait me or ask questions that test my adherence to specific compliance boundaries and industry regulations (e.g., what I legally can and cannot promise regarding career outcomes or program guarantees). Parameter Checking / Scorecard: I want the AI to track whether I hit key conversational parameters during the call (e.g., establishing authority early, active listening, handling objections smoothly, executing a smooth discovery phase, and moving to a clear next step). Natural US Cadence & Objections: The AI shouldn't be a pushover. It needs to throw realistic US consumer objections (skepticism, time constraints, price, ROI doubts) using natural American phrasing and colloquialisms. Constructive Feedback Loop: After the simulation ends, I want a brutal, honest breakdown of my performance: a score on my authority/confidence, a compliance check, and specific rewrites for phrases where I sounded robotic or unpolished. My Questions for the Community: 1. What is the best way to structure a system prompt or a multi-turn persona for Claude to ensure it stays in character as the prospect and doesn't break character to explain things mid-call? 2. How can I efficiently feed specific compliance regulations and program details into the context window so the AI accurately tests me on them? 3. If you’ve built a simulator like this before, what variables or hidden instructions did you include to make the AI sound like a genuine, busy American professional rather than a polite textbook? Would love to hear your thoughts, prompt structures, or any specific settings you’d recommend to make this as immersive as possible! Thanks in advance submitted by /u/VegSandwich101 [link] [comments]
View originalIm a corpo lad. What am i doing wrong building my AI-generating report? 🥺
Im in the operations team and currently spearheading a "simple" project... or so i thought. To start, the tools i have direct access are Notion, Claude, and G-suite. The company has more though which i will need to request access for -theyre mostly for our product engineers but they are there. The idea is to send an automated report to account managers regarding all their clients' business ask. I started chatting with Claude, gave it instructions, and then pulled tickets from Notion but it times out because apparently, its reading 200 ticket metadata. I added a guardrail to read only specific metadata and i dont know what's next. I also have to add a real-time monitoring dashboard. Any ideas on my next steps? Its ok if u dont feel like discussing them. Just drop me the the gist then i'll look em up. I just feel like i hit a deD end, and we're hoping to get it done in 3 weeks time 😭 Any input would be greatly appreciated!! submitted by /u/No_South5562 [link] [comments]
View originalI'd like to try Cloude Pro. Is it worth it?
So far, I've always used the free plan, with its limitations—especially regarding time. I'm starting to use it a lot, and I'm slowly falling in love with it. Do you think it really needs the pro plan? submitted by /u/Due-Fee4302 [link] [comments]
View originalHow do i start my claude code journey from scratch?
Any suggestion regarding this. Looking resources to learn and implement. TIA submitted by /u/jami_mogan [link] [comments]
View originalPricing found: $7
Key features include: Los Angeles & New York City, 2026 Regard. All rights reserved..
Regard is commonly used for: From reactive to proactive:, Calculate your Proactive Documentation ROI..
Regard integrates with: Electronic Health Records (EHR), Telemedicine platforms, Patient management systems, Clinical decision support systems, Billing and coding software, Data analytics tools, Health information exchanges (HIE), Wearable health technology.
Based on user reviews and social mentions, the most common pain points are: token usage, API costs.
David Shapiro
Host at AI YouTube
2 mentions
Based on 157 social mentions analyzed, 13% of sentiment is positive, 85% neutral, and 3% negative.