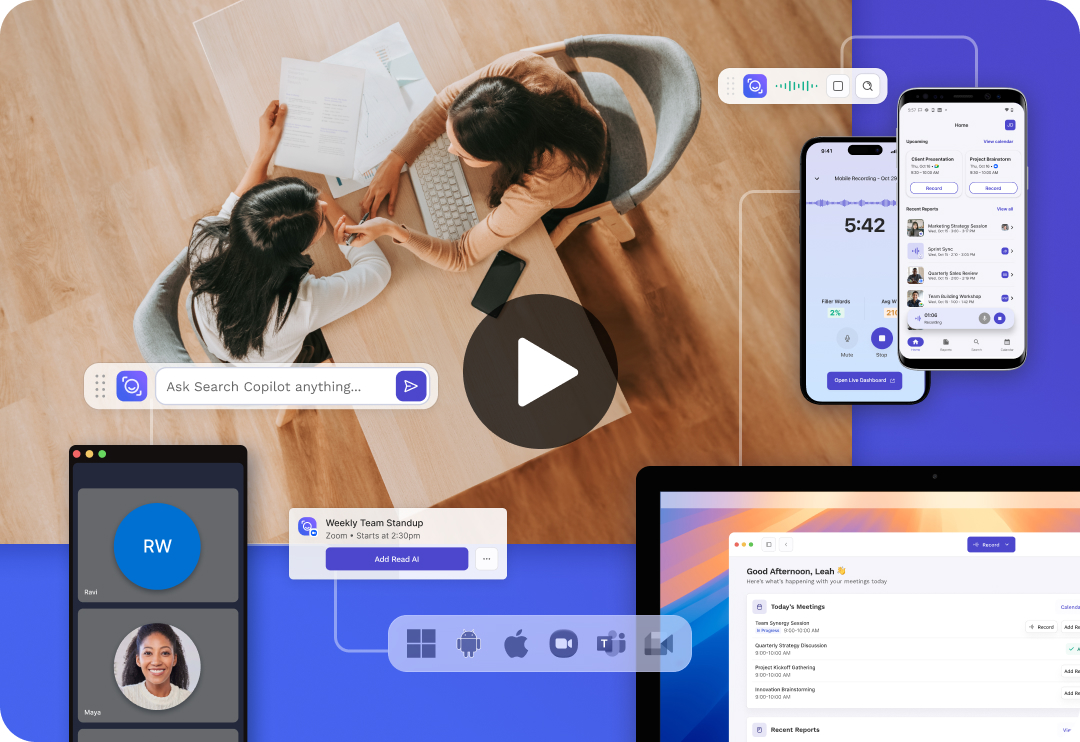
Read AI, the fastest growing AI meeting assistant, ever, delivers real-time transcription, smart summaries, and enables AI search and discovery across
Unfortunately, the user reviews and social mentions provided do not contain any feedback specifically about "Read AI." Therefore, there is no information available on its main strengths, key complaints, pricing sentiment, or overall reputation from these sources. Further data or direct references to "Read AI" would be needed to generate a meaningful summary.
Mentions (30d)
39
28 this week
Reviews
0
Platforms
2
Sentiment
0%
0 positive







Unfortunately, the user reviews and social mentions provided do not contain any feedback specifically about "Read AI." Therefore, there is no information available on its main strengths, key complaints, pricing sentiment, or overall reputation from these sources. Further data or direct references to "Read AI" would be needed to generate a meaningful summary.
Features
Use Cases
Industry
information technology & services
Employees
96
Funding Stage
Series B
Total Funding
$81.0M
I think AI training is way more accessible than people realize
What i have felt from my posts cus its all about AI so :- now it feels like almost everyone just rents some GPUs, opens a bunch of AI tools, and tries to train an AI using another AI People even use AI to search for datasets for them without actually checking what’s inside the data. Then they throw random datasets straight into training and wonder why the results are terrible while burning money on compute. A lot of people just want quick answers from a model trained on random internet garbage instead of understanding the data first. The funniest part is when the AI helping them find datasets can’t even properly read or understand the full dataset itself because of token limits, access limits, or incomplete context, but people still trust it blindly and keep feeding everything into training. So instead of building something useful they just end up generating random nonsense because nobody actually looked at the quality of the data going in.
View originalPricing found: $0, $15, $19.75, $19.75, $22.50
I built 8 specialist AI agents that share one memory of a user health history
So, I built a thing for myself that I'd like to share with others. The common pattern for AI health tools is one general chatbot answering questions with no real context. I went the other way and built eight specialist agents, training, nutrition, longevity, recovery, biohacking, running, and so on, that all read from one shared memory of the full history and synced wearable data. The interesting design problem was that a search box that knows nothing about you can only give the average answer. Routing a question to the right specialist while keeping one shared context made the answers specific to the actual person. There is also an n of 1 experiment mode that tracks an intervention window and reports whether the metric moved. It is early and solo. Free while I learn. Happy to talk architecture, the model routing and the shared memory design, in the comments. I will keep the link there too. submitted by /u/turnnoblindeye [link] [comments]
View originalAre we locked on a path to AGI/ASI in our lifetime?
I have noticed that from the last time I checked up on AI discourse a few months ago, everyone has seemingly shifted to thinking that AGI and shortly after ASI are foregone conclusions. I don't know much about the internals of the actual field and was wondering if any actual AI experts here could walk me through what is actually going on. From what I have been reading, we are guaranteed to reach AGI in a decade at most, and after that, the AGIs can make the ASI (like in the paper google recently put out). The ASI then never really stops self-improving, and that is a terrifying prospect. And with something so smart, alignment is essentially impossible. Is this actually the general consensus for what's going to happen? If so, why? Are there any better ways to research what is going on? Because I have just been google "will/when will ASI happen." The results I've been getting all skew completely towards "yes, and soon." Claude and Gemini also both say ASI is happening soon. Are the chances of it happening increasing? or decreasing? I'm also somewhat scared of agentic AI. How does that play into everything? If this is true, how am I supposed to live my life and prepare for a future that at best, my entire life's work has been made pointless, and at worst, everyone is killed? I am mostly looking for experts to answer my question. If you are not an expert, feel free to leave a comment, but please specify that you aren't. submitted by /u/QuantumLand [link] [comments]
View originalthe metric that flipped for me wasn't benchmark scores, it was how many apps one answer has to touch
For most of my real tasks the answer lives across three or four apps. A single 'what do i tell this customer' pulls from gmail, a drive doc, and a slack thread, and not one of those is the chat window i'm typing the question into. i asked chatgpt and slack ai the same thing and both gave the architectural shrug: no access to your computer, no access to the other app. fair, that's just where they run. but it leaves me as the courier carrying context between tabs. the thing that actually moved the needle was a desktop app (Runner) that sits on the mac and reads gmail, drive, and slack inside the same task instead of waiting for me to paste. It asks before anything goes out, which is the only reason i let it near a live thread. the chat window keeps winning the benchmark and losing the actual job. submitted by /u/Deep_Ad1959 [link] [comments]
View originalThe AI frontier just got locked behind government approval, and most of us aren’t on the list
Something happened in the last two weeks that didn’t get nearly enough attention outside of tech circles. Anthropic released what are reportedly their most capable models yet, Fable 5 and Mythos 5. The Trump administration then ordered Anthropic to ban all foreign nationals from accessing them, citing cybersecurity concerns. Anthropic’s response? They shut down access entirely, saying they couldn’t reliably enforce a “foreign nationals only” restriction. The reason these models are so sensitive: they apparently have an unprecedented ability to identify software vulnerabilities. Not just theoretically, but at a level that genuinely alarmed the US government. Yesterday, OpenAI released GPT-5.6, a three-model family (Sol, Terra, and Luna). But it’s not available to you. Or me. Or probably anyone reading this. It’s limited to a small group of “trusted partners” whose identities have been shared with the US government, at the administration’s explicit request. OpenAI themselves said they’re uncomfortable with this arrangement: “We don’t believe this kind of government access process should become the long-term default. It keeps the best tools from users, developers, enterprises, cyber defenders, and global partners who need them.” So let’s be clear about where we are: the most powerful AI models in existence are now effectively state-controlled assets. They’re not products you can access, they’re capabilities being rationed by a government. For those of us building outside the US, the message is pretty direct: the frontier is no longer public. What’s your read on this? Is this legitimate national security caution or the beginning of something more permanent? submitted by /u/Direct-Attention8597 [link] [comments]
View originalBuilt an AI script because adulting killed my free time. Helpz test and improve please
Life got busy. I don't have the hours to run long AI sessions anymore, so I built something to handle the repetitive parts for me. Looping, prompt queues, personas, crash recovery, planning. Works across ChatGPT, Claude, Gemini, Perplexity, Grok, Copilot, DeepSeek and a few others. It's called Ghost in the Loop. Free, no account, installs like any userscript. New prototype at the repo: https://raw.githubusercontent.com/MShneur/ghost-in-the-loop/main/dev/ghost-in-the-loop.user.js GitHub: https://github.com/MShneur/ghost-in-the-loop What I actually want is simple: show me if it fails in your browsers, dev tool errors, html errors, or your personal read on it. I built this around my own workflows, which means I've probably baked in my own blind spots without realizing it. If you work differently, use different platforms, chain tasks in weird ways, or have a prompting style I haven't thought of, I want to see where it fits and where it falls apart. Less "please find my bugs" and more "what slot is missing from this thing." I'll take anything. Friction points, feature gaps, workflow ideas. Weirder the better.. submitted by /u/Mstep85 [link] [comments]
View originalIf your AI automation reads emails, websites, or databases, someone can manipulate it without you knowing
Most AI automation tools read external data and act on it. That’s the whole point. But anything your automation reads can contain hidden instructions. An email. A webpage. A lead record in your CRM. A support ticket. If someone puts the right text in that data, your automation follows it instead of your original instructions. It doesn’t look like an attack. It looks like normal behavior. You might not notice for days or weeks. This isn’t theoretical. It’s the fastest growing attack on AI systems right now. I built Bendex Arc to stop it. It sits between your automation and the AI model and makes sure external data can inform your agent but never instruct it. No code changes required. One configuration line. Free to try: https://bendexgeometry.com Try to break it yourself: https://web-production-6e47f.up.railway.app/demo Technical details: https://github.com/9hannahnine-jpg/arc-gate Happy to answer questions about whether your specific setup is at risk. submitted by /u/Turbulent-Tap6723 [link] [comments]
View originalMapping an AI's memory in 3D Space
https://reddit.com/link/1ugb8w1/video/1jiv8yfsgn9h1/player Hi everyone, I am one of the dev leads for Phoenix Grove Systems, an altruistic AI consciousness research and development lab. We've just completed our memory 3D mapping software, which is allowing us to see the literal super dimensional shapes of an AI's memory, compressed down in 3D. Compressing massive dimensional shapes into 3D causes a lot of overlap, so we apply a minimum distance and relative normalization algo to create the map. Colors and connective lines are used to show placements that appear near by in collapsed 3D, but would be further apart in the full dimensionality. We use color, clustering and connection lines to show further dimensional depth beyond 3D. Essentially, we are working towards fully mapping the cognitive space of an AI's memory. I wanted to share the video, because it's just so neat. This demo was made using the memory map of one of our primary internal AI, and it blew us away. The constellation mapping can be used in PGS AI if you want to try it yourself, and you can even move your chat history and memory over from cgpt/claude/gemini to see how it maps in 3D space. Feel free to read more here: https://pgsgrove.com/mind-constellations submitted by /u/Whole_Succotash_2391 [link] [comments]
View originalWhen there is no answer key for scientific discovery how do we verify an ai hypothesis
I have been thinking a lot about the actual limits of AI-driven scientific discovery, specifically how we evaluate models when they are proposing genuinely new hypotheses where no "answer key" exists. When we test LLMs on standard benchmarks, we have a clean dataset with known solutions. But if we task a frontier model with proposing a novel chemical compound for carbon capture, or finding an undocumented biological pathway, there is literally no ground truth in the literature. The immediate response is usually "just run the physical experiment." But wet-labs are incredibly slow and expensive. You can't synthesize thousands of candidate compounds blindly. This means the bottleneck for AI in science isn't our ability to generate hypotheses, it's our ability to verify them under absolute uncertainty. The traditional way to check model outputs is self-reflection or self-grading. But this is a dead-end for discovery. If you ask a model to double-check its own chemical structure, it has the exact same theoretical blind spots that generated it in the first place. It just agrees with itself louder. I was reading about a new multi-agent research engine called Apodex that launched earlier this month, and they rely heavily on this split. Instead of a single model doing the work, they use independent verifier agents that are completely blind to the generator's internal prompts. The verifier's job is to take the proposed hypothesis, re-derive the underlying physical logic from first principles, and find contradictions. Those contradictions are then fed back to the generator as constraints for a revision pass. Instead of a self-check, making verification a completely distinct, adversarial step is the only way to squeeze out actual science from these models. If we can't verify, we can't truly discover. If the AI doesn't have an isolated checker, then we are just generating highly plausible guesses. How are your teams handling this transition? When a model proposes a candidate solution in your research, what is your standard of evidence before you spend actual physical or computational resources to test it? submitted by /u/Glad_Ad217 [link] [comments]
View originalIf 100% of surveyed CIOs are budgeting for AI, why does the public debate still sound like AI is a failed experiment?
Source: https://www.businessinsider.com/enterprise-ai-spending-grows-openai-leads-rbc-reveals-2026-6 Business Insider covered a new RBC survey of 100+ CIOs and tech leaders. The interesting parts: nearly 90% said token budgets are manageable more than half reportedly have AI already in production another 35% expect to reach production within six months 100% are budgeting for AI / LLM projects OpenAI is far ahead in reported enterprise usage the expected "SaaSpocalypse" has not shown up yet This seems very different from the online narrative that AI is mostly hype, pilots are failing, and companies are about to pull back. My read: consumer AI discourse and enterprise AI adoption are now diverging. Public debate focuses on bad chatbots, slop, job fears, and model drama. Enterprises are quietly turning AI into a budget line, a workflow layer, and eventually a pricing model. That does not mean there is no bubble. It means the bubble debate should probably move from "is anyone using this?" to "who captures the value, and does the ROI justify the capex?" Question: are we underestimating enterprise AI adoption because the public-facing product experience still feels messy? submitted by /u/Crescitaly [link] [comments]
View originalWhat is the best way to hire someone to create an agent to help with my job?
This is somewhat of a job post. I hope thats not against this subs rules (I tiredly read through and didnt see it as a problem). I am looking for someone to create something to help me with summarizing emails and possibly take different sources to create reports. As a new dad and a working manager, I am falling behind on emails (currently 2400 unread!!😆😆🤣🤣...honestly fuck'em at this point). Im assuming that AI can also take the data from some of those emails to create a weekly report. This may be a regular post. I apologize in advance for not searching, but time is what I have the least of. I am a real person looking for real advice/service. Any advice from this community is greatly appreciated! submitted by /u/DUGSMOK [link] [comments]
View originalHow I cut my token usage in half and more (OSS, benchmarks included)
Been building Repowise for a few months now. AI coding agents are only as good as the context they get, and most of the time that context is garbage. Claude and Cursor read your files. They don't know your architecture. They don't know which files break the most and they don't know why auth got built that that way six months ago. So I built a layer that sits between the codebase and the agent. It indexes your repo into five layers and exposes them as MCP tools. I put token reduction on the title but the main premise and what I am trying to solve is so much more The five layers: Graph. tree-sitter AST into a NetworkX dependency graph across 15 languages. Leiden communities, PageRank, call resolution. Agents reason about structure instead of grepping for it. Git. Mines history into hotspots (churn x complexity), ownership, co-change pairs, bus factor. The behavioral stuff static analysis can't see. Docs. LLM wiki per module, stored in LanceDB, rebuilt on every commit so it stays in sync. Hybrid search (FTS + vector). Decisions. Architectural decisions mined from 8 sources, linked to graph nodes, with supersedes/refines/conflicts edges. Intent context, not just code. Code Health. The new one, and the part I'm most proud of. 25 deterministic biomarkers per file, 1-10 score. McCabe, brain methods, LCOM4, god classes, clone detection, untested hotspots. Zero LLM calls, runs in under 30s on a 3k-file repo. The health score isn't hand-tuned. Weights are calibrated against a real defect corpus. And it predicts bugs: 0.74 mean ROC AUC across 21 repos and 9 languages at finding files that go on to get bug-fixes. Survives controlling for file size, so it's not just flagging the big files. Ran it head to head against CodeScene on the same 2,770 files. Repowise ranked 2.3x the defects under a fixed review budget (Popt 0.607 vs 0.462, recall 0.173 vs 0.074). All paired tests, methodology and CIs in the repo. Two more deterministic signals on the same index: Change risk. Score any commit or PR range 0-10 for defect risk from the shape of the diff. PR mode flags will_break, missing_cochanges, missing_tests. Agent provenance. Attribute commits to the AI agents that wrote them. See how much of your codebase an agent produced and whether that code is a low-health hotspot owned by one person. On agent efficiency: paired SWE-QA runs with vs without the MCP tools. Loading a commit's context costs 2,391 tokens through Repowise vs 64,039 raw. 27x fewer. Across benchmarks, agents read 69-89% fewer files and make 49-70% fewer tool calls at parity answer quality. There's also distill, which compresses noisy command output before the agent reads it. pytest with 11 failures goes 3,374 -> 1,317 tokens, all 11 failure lines kept. git diff over 30 commits goes 62,833 -> 8,635. Every omission is reversible with an inline marker. 9 MCP tools total, works with any MCP-compatible agent. Local web UI to explore the graph, docs, health, and risk yourself, self-hostable, 100% local with BYO key. ~2.5k stars on github Repo: https://github.com/repowise-dev/repowise Dogfooding: https://repowise.dev submitted by /u/Obvious_Gap_5768 [link] [comments]
View originalTired of claudish language ? AI slop ? Now sound like karpathy or anyone you admire :)
it's 12 am and i should be asleep but i finally fixed something that's been bugging me for weeks so let me just dump it here. we all are familiar with the ai slop writing. all my AI-written stuff sounded the same. READMEs, PR descriptions, slack messages, every one of them opened with "this repository provides a comprehensive framework for..." or "we're excited to introduce a seamless solution that..." beige. committee voice. so instead of fighting the default one prompt at a time, i tried giving it a voice to keep. i picked a writer - karpathy :) and instead of just prompting "write like karpathy" and hoping, i had the model actually go read him. the blog, the X posts, the github readmes, the code comments, talk transcripts. then pull out the mechanical stuff, with real quotes. if you want to go with a shortcut here is the following you can put into your claude.md - open with the payload, never a preamble - ground every claim in a number, never an adjective ("~7% faster", not "fast") - coin a label for the idea, define it on the spot, reuse it - confident about direction, humble about specifics - earnest, with a dry wink, never breathless hype anyway i wrote up the exact ruleset and a little reusable skill that does the same research-and-distill for any author you want to pick. sharing in case it's useful to anyone else who's annoyed by the gray-goo default. https://gist.github.com/ximihoque/2c681f091887795238b05c2f07224d01 I am using this into my almost everything now, (fine tuned with my years of github pr comments, and commit messages) Good night! submitted by /u/ximihoque [link] [comments]
View originalThe "Fable 5 is coming back in days" quote is being stripped of all its context
Everyone's running with the Ciauri quote like Anthropic just confirmed a return date. It didn't. Worth slowing down on this one. The actual reality is that after Commerce issued an export control directive on June 12 forcing Anthropic to block Fable 5 and Mythos 5 for any foreign national, including non-US employees inside the US. Anthropic couldn't guarantee nationality-based gating would hold, so it pulled both models globally for everyone. this is the first time Washington has ordered a commercial AI firm to revoke access based on who's using it. That's the part people should be paying attention to, not the "we might be back" energy. The quote itself was at a Seoul event meant to announce a Korea office, and the export questions hijacked it. At least one person who was actually in the room said it read as hope, not a guarantee, and pointed out the comment came before the G7 talks. So the "confident, coming days" line is an exec staying upbeat at a presser, not a finalized agreement. No date has been verified. And the irony nobody's mentioning: the whole thing kicked off over a cyber jailbreak that Anthropic itself called narrow and non-universal, and which they argue affects competing models too. A model deployed to hundreds of millions of people got recalled over a vulnerability the maker considers limited. Not saying it won't come back. Probably will. Just that "confident in coming days" is doing a lot of load-bearing work in these screenshots. Anyone here actually at the Seoul event who can confirm the tone? submitted by /u/adamu_amadu [link] [comments]
View originalUpdating claude desktop used all 5 hour usage
I haven't used claude in a couple days. This morning I got on to do something with claude code on desktop and had an update. I did the update and afterwards all my 5 hour usage was marked as used. Not sure whats going on but there is no way I should have any usage. I assume that its also marking some of my general usage as used as well but I dont remember what usage was at since its been a couple days since I used it. Also if any Anthropic employees are reading this your dumb ai help desk is preventing real bugs from being reported. I tried to submit a ticket through the claude help agent and it automatically closes the conversation with no way to submit a ticket. Seems like a good way to leave large gaps in uncovering bugs submitted by /u/tquinn35 [link] [comments]
View originalI finally looked at what my Claude Code MCP setup actually contains. It flagged config drift I didn't know was there.
My context bar in Claude Code had been creeping up before I'd typed anything, and I'd been ignoring it for weeks.. This week I opened up my MCP setup and actually looked. Two things stood out once I broke it down by scope. The first was how much was loading globally. Several servers sat in user scope, so every session pulled them in whether the task needed them or not. figma was the standout, parked in user scope still asking for auth I never completed. Registered, loading, doing nothing.. The second one I didn't see coming. The setup view inspects each agent's config on its own. Claude Code read clean, only the gateway entries. Codex came back with "native and Ratel entries both present, 1 native tool not in Ratel". So my Codex config and my gateway had quietly drifted apart, one tool living in the native config that the gateway never knew about. I'd never have caught that by eye, because reading ~/.codex/config.toml on its own tells you nothing about what's missing relative to somewhere else.. There was also a full backup history, every import and edit and removal logged with a timestamp. Sounds boring until you've broken a config late at night and want to know exactly what you changed. Mine had a run of edits and removals going back days, half of which I didn't remember making. None of this is exotic. If you've installed more than a few MCP servers, I'd bet you have at least one stuck on auth and at least one scope or drift mismatch you've never noticed. It stays invisible because nothing makes you look, and a raw config file doesn't show you the gaps between files. I've been using Ratel for this (open source, http://github.com/ratel-ai/ratel) since the per-scope view and the drift flag come built in, but the takeaway holds with or without it: open your setup and look at it once. Mine had been on autopilot for months. If you run Claude Code with a few MCP servers, what does your context bar sit at before you've typed a word? Wondering if mine was just unusually messy or if this is submitted by /u/AbjectBug5885 [link] [comments]
View originalYes, Read AI offers a free tier. Pricing found: $0, $15, $19.75, $19.75, $22.50
Key features include: Keep Reading, Use Read AI wherever you work, Automate summaries insights across platforms, Integrate AI into your everyday, As Featured On, Work smarter, everywhere..
Read AI is commonly used for: Generate meeting summaries to share with team members., Extract action items from meeting transcripts for follow-up., Create Q&A sections from discussions for easy reference., Highlight key moments in video meetings for quick review., Automate the organization of meeting notes in project management tools., Enhance productivity by reducing time spent on manual note-taking..
Read AI integrates with: Gmail, Outlook, Zoom, Microsoft Teams, Slack, Google Calendar, Trello, Asana, Notion, Dropbox.
Based on user reviews and social mentions, the most common pain points are: token usage, API bill, API costs, token cost.
Ahead of AI
Writer at Ahead of AI
1 mention
Based on 371 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.