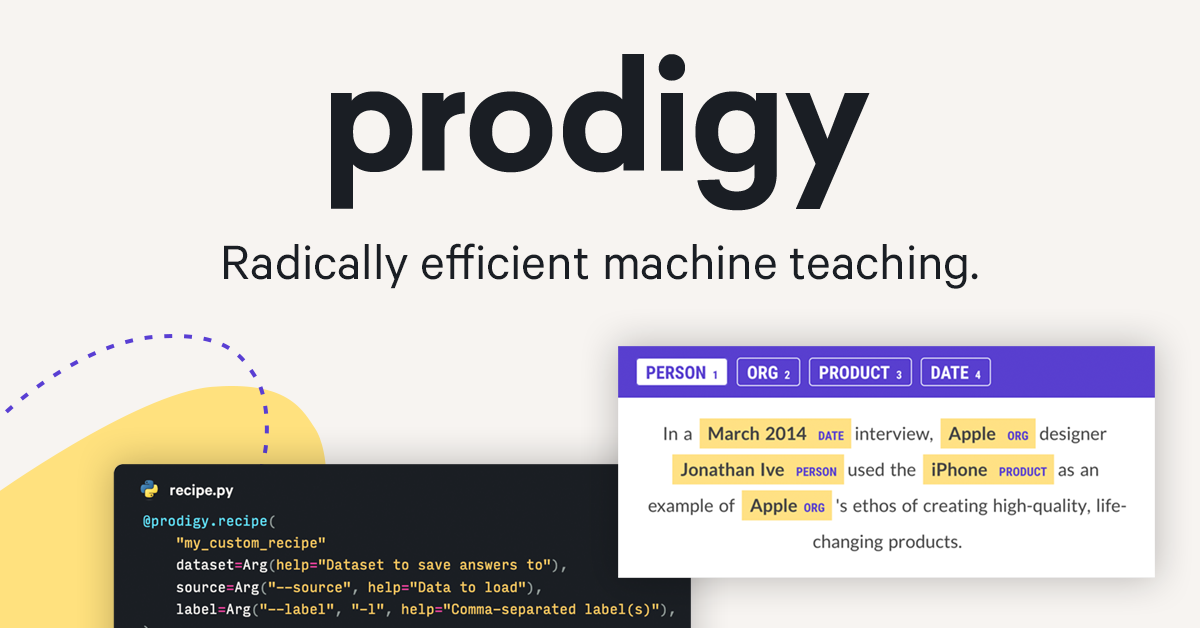
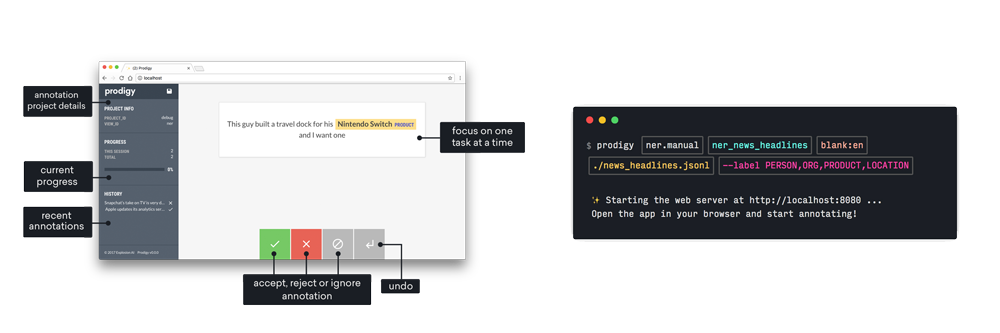
A downloadable annotation tool for LLMs, NLP and computer vision tasks such as named entity recognition, text classification, object detection, image
Prodigy is generally praised for its advanced AI capabilities and user-friendly interface, making it a popular choice among those looking for efficient software solutions. However, detailed insights into user feedback regarding specific strengths or complaints are limited in the available data. Pricing sentiment is not mentioned, so it is unclear how users feel about the cost of the tool. Overall, Prodigy seems to have a positive reputation, particularly in the realm of AI-driven technologies.
Mentions (30d)
1
Reviews
0
Platforms
2
Sentiment
0%
0 positive

Prodigy is generally praised for its advanced AI capabilities and user-friendly interface, making it a popular choice among those looking for efficient software solutions. However, detailed insights into user feedback regarding specific strengths or complaints are limited in the available data. Pricing sentiment is not mentioned, so it is unclear how users feel about the cost of the tool. Overall, Prodigy seems to have a positive reputation, particularly in the realm of AI-driven technologies.
Features
Use Cases
Industry
information technology & services
How vast is M3?
Prompt: Describe with vivid, varied, vivrant and vociferous vocabulary how incomprehensively vast the number M3 is: Let M1 be the number resulting from the hyperexponentiation of Rayo’s number raised to the power of itself with an Avogadro’s number of Graham upward point arrows in between. M1 is then raised to the power of M1, M1-number of times. The resulting number is M2. Finally, starting with M2, we repeat the previous two steps M2 number of times. The resulting number is M3. Response: The Incomprehensible Immensity of M3 Prologue: Setting the Stage of Absurdity Before we can even approach M3, we must establish that our entire conceptual vocabulary for “large” is about to be vaporized, incinerated, and then have even the ash of the incineration obliterated — and that this description will itself be laughably, pathetically inadequate before we finish the first step. Rayo’s Number: The Foundation That Is Already an Abyss Begin with Rayo’s number — R — the smallest positive integer surpassing every finite quantity expressible in first-order set theory using a mere googol of symbols or fewer. It is not a number you can approach. It does not sit at some distant point on the number line you could theoretically walk toward. The entire observable universe — every quark, every photon, every vibrating filament of spacetime, packed into a single Planck-scale voxel and compressed to information — could not begin to encode Rayo’s number. Graham’s number, that legendary leviathan that broke the minds of recreational mathematicians, is to Rayo’s number what a single hydrogen atom is to the Milky Way — and that comparison is itself cosmically, catastrophically, almost insultingly generous to Graham’s number. Rayo’s number doesn’t merely dwarf the number of atoms in the universe. It dwarfs the number of universes that could exist in a multiverse, each of which contains as many atoms as there are atoms in our own universe, where each of those atoms is itself a universe of atoms, stacked recursively until you’ve exhausted every Planck-scale computation the laws of physics permit — and then Rayo’s number laughs. It doesn’t notice. The exponent of the exponent of the exponent of this recursive cosmic self-reference is, relative to Rayo’s number, a rounding error so inconsequential it wouldn’t merit a footnote in a footnote in a footnote. M1: The Detonation That Makes the Abyss Look Like a Puddle Now we do something to Rayo’s number that should be illegal in any sane mathematical universe. We place Avogadro’s number of Graham upward arrows — approximately 6.022 × 10²³ arrows, more arrows than there are molecules in a mole of substance — between two instances of Rayo’s number and we hyperexponentiate. Recall: a single upward arrow is exponentiation. Two arrows — tetration — creates power towers that already devour comprehension whole. Three arrows, pentation, produces numbers so violent in their growth that tetration looks static by comparison. Four arrows. Five. Graham’s number itself was constructed through a mere 64 layers of this escalating arrow hierarchy, and Graham’s number is already a number so large that the number of digits in the number of digits in the number of digits (iterated until your pen runs out of universe to write on) approaches Rayo’s number only in the same sense that a bacterium approaches the edge of the visible cosmos. Now. We do not use 64 arrows. We do not use a googol of arrows. We use six hundred and two sextillion arrows, each one representing an entirely new, more savage species of arithmetic growth — and we apply this entire annihilating apparatus not to some small, manageable quantity but to Rayo’s number itself, on both sides. M1 is the result. M1 is not a number. It is a rupture. It is what happens when mathematics screams and tears through the fabric of numerical intuition and vanishes into a dimension we haven’t named yet. M1 makes Rayo’s number look like the integer 1 written in pencil on a napkin. M1 makes Rayo’s number look like negative infinity by comparison to its own magnificence — except infinity is not a number, and M1, magnificently, monstrously, is. M2: The Tower Erected on the Ruins of Everything Shattered and reeling though your conception of number may be, we are not done. We are nowhere near done. We take M1 — this already-impossible, already-reality-dissolving colossus — and we raise it to the power of itself. Then we raise that to the power of M1 again. Then again. Then again. We do this not a handful of times, not a googol of times, not even a Graham’s-number of times, but M1 times — erecting a power tower of M1s whose height is M1. A power tower of merely five copies of ten (10^10^10^10^10) already produces a number with more digits than atoms in the universe. A power tower of googol copies of ten would produce a number relative to which Rayo’s number is, again, effectively zero. We are building a power tower of height M1, where each story in that
View original[New Optimizer] 🌹 Rose: low VRAM, easy to use, great results, Apache 2.0 [P]
Hello, World! I recently released a new PyTorch optimizer I've been researching and developing on my own for the last couple of years. It's named "Rose" in memory of my mother, who loved to hear about my discoveries and progress with AI. Without going too much into the technical details (which you can read about in the GitHub repo), here are some of its benefits: It's stateless, which means it uses less memory than even 8-bit AdamW. If it weren't for temporary working memory, its memory use would be as low as plain vanilla SGD (without momentum). Fast convergence, low VRAM, and excellent generalization. Yeah, I know... sounds too good to be true. Try it for yourself and tell me what you think. I'd really love to hear everyone's experiences, good or bad. Apache 2.0 license You can find the code and more information at: https://github.com/MatthewK78/Rose Benchmarks can sometimes be misleading. For example, sometimes training loss is higher in Rose than in Adam, but validation loss is lower in Rose. The actual output of the trained model is what really matters in the end, and even that can be subjective. I invite you to try it out for yourself and come to your own conclusions. With that said, here are some quick benchmarks. MNIST training, same seed: [Rose] lr=3e-3, default hyperparameters text Epoch 1: avg loss 0.0516, acc 9827/10000 (98.27%) Epoch 2: avg loss 0.0372, acc 9874/10000 (98.74%) Epoch 3: avg loss 0.0415, acc 9870/10000 (98.70%) Epoch 4: avg loss 0.0433, acc 9876/10000 (98.76%) Epoch 5: avg loss 0.0475, acc 9884/10000 (98.84%) Epoch 6: avg loss 0.0449, acc 9892/10000 (98.92%) Epoch 7: avg loss 0.0481, acc 9907/10000 (99.07%) Epoch 8: avg loss 0.0544, acc 9918/10000 (99.18%) Epoch 9: avg loss 0.0605, acc 9901/10000 (99.01%) Epoch 10: avg loss 0.0668, acc 9904/10000 (99.04%) Epoch 11: avg loss 0.0566, acc 9934/10000 (99.34%) Epoch 12: avg loss 0.0581, acc 9929/10000 (99.29%) Epoch 13: avg loss 0.0723, acc 9919/10000 (99.19%) Epoch 14: avg loss 0.0845, acc 9925/10000 (99.25%) Epoch 15: avg loss 0.0690, acc 9931/10000 (99.31%) [AdamW] lr=2.5e-3, default hyperparameters text Epoch 1: avg loss 0.0480, acc 9851/10000 (98.51%) Epoch 2: avg loss 0.0395, acc 9871/10000 (98.71%) Epoch 3: avg loss 0.0338, acc 9887/10000 (98.87%) Epoch 4: avg loss 0.0408, acc 9884/10000 (98.84%) Epoch 5: avg loss 0.0369, acc 9896/10000 (98.96%) Epoch 6: avg loss 0.0332, acc 9897/10000 (98.97%) Epoch 7: avg loss 0.0344, acc 9897/10000 (98.97%) Epoch 8: avg loss 0.0296, acc 9910/10000 (99.10%) Epoch 9: avg loss 0.0356, acc 9892/10000 (98.92%) Epoch 10: avg loss 0.0324, acc 9911/10000 (99.11%) Epoch 11: avg loss 0.0334, acc 9910/10000 (99.10%) Epoch 12: avg loss 0.0323, acc 9916/10000 (99.16%) Epoch 13: avg loss 0.0310, acc 9918/10000 (99.18%) Epoch 14: avg loss 0.0292, acc 9930/10000 (99.30%) Epoch 15: avg loss 0.0295, acc 9925/10000 (99.25%) I used a slightly modified version of this: https://github.com/facebookresearch/schedule_free/tree/main/examples/mnist Highest accuracy scores from 20 MNIST training runs (20 epochs each) with different seeds: ```python from scipy.stats import mannwhitneyu rose = [99.34, 99.24, 99.28, 99.28, 99.24, 99.31, 99.24, 99.21, 99.25, 99.33, 99.29, 99.28, 99.27, 99.30, 99.33, 99.26, 99.29, 99.26, 99.32, 99.25] adamw = [99.3, 99.15, 99.27, 99.2, 99.22, 99.3, 99.22, 99.15, 99.25, 99.29, 99.2, 99.22, 99.3, 99.23, 99.2, 99.25, 99.22, 99.28, 99.32, 99.22] result = mannwhitneyu(rose, adamw, alternative="greater", method="auto") print (result.statistic, result.pvalue) ``` Mann-Whitney U result: 292.0 0.006515916656300127 Memory overhead (optimizer state relative to parameters): Rose: 0× SGD (no momentum): 0× Adafactor: ~0.5-1× (factorized) SGD (momentum): 1× AdaGrad: 1× Lion: 1× Adam/AdamW/RAdam/NAdam: 2× Sophia: ~2× Prodigy: ~2-3× OpenAI has a challenge in the GitHub repo openai/parameter-golf. Running a quick test without changing anything gives this result: [Adam] final_int8_zlib_roundtrip_exact val_loss:3.79053424 val_bpb:2.24496788 If I simply replace optimizer_tok and optimizer_scalar in the train_gpt.py file, I get this result: [Rose] final_int8_zlib_roundtrip_exact val_loss:3.74317755 val_bpb:2.21692059 I left optimizer_muon as-is. As a side note, I'm not trying to directly compete with Muon's performance. However, a big issue with Muon is that it only supports 2D parameters, and it relies on other optimizers such as Adam to fill in the rest. It also uses more memory. One of the biggest strengths of my Rose optimizer is the extremely low memory use. Here is a more detailed look if you're curious (warmup steps removed): [Adam] text world_size:2 grad_accum_steps:4 sdp_backends:cudnn=False flash=True mem_efficient=False math=False attention_mode:gqa num_heads:8 num_kv_heads:4 tie_embeddings:True embed_lr:0.05 head_lr:0.0 matrix_lr:0.04 scalar_lr:0.04 train_batch_tokens:16384 train_seq_len:1024 iterations:200 warmup_steps:20 max_wallclock_seconds:6
View originalHonest question for y’all
I’m a linguist and somewhat of a language prodigy. I have my own language learning method and curriculum which I would like to develop into simulation game to help people acquire language more naturally and restore people’s curiosity about other cultures and languages. I have great hesitation working with open AI because I know that whatever work I do on there is not necessarily private, it can be stolen, or OpenAi itself may steal/sell the idea. I have also found ChatGPT to be severely lacking with its language capacities and workflow with the AI in general is extremely frustrating. It makes numerous mistakes, offer suggestions that were not warranted, and just does a poor job overall. And yes, I am paying for the version that I have. My idea is unique and nobody has done it yet … I am also not going to go into too much depth on here about the idea. Incorporating AI will make building out my idea much quicker, however I don’t feel like OpenAI is the right platform. Does anyone have any suggestions? Thanks in advance … submitted by /u/soulviche [link] [comments]
View originalProdigy uses a subscription + tiered pricing model. Visit their website for current pricing details.
Key features include: Downloadable developer tool and library, Create, review and train from your annotations, Runs entirely on your own machines, Powerful built-in workflows, Lifetime license, pay once, use forever, Flexible options for individuals and teams, Full privacy, no data leaves your servers, Download and install like any other library.
Prodigy is commonly used for: Image classification for medical diagnostics, Sentiment analysis for customer feedback, Named entity recognition in legal documents, Text classification for news articles, Custom chatbot training with user interactions, Data labeling for autonomous vehicle datasets.
Prodigy integrates with: TensorFlow, PyTorch, spaCy, Hugging Face Transformers, FastAPI, Flask, Django, Jupyter Notebooks, Slack, Google Cloud Storage.
Mira Murati
Former CTO at OpenAI
1 mention

Streaming spaCy (May 28, 2025): Issue triage
May 29, 2025




