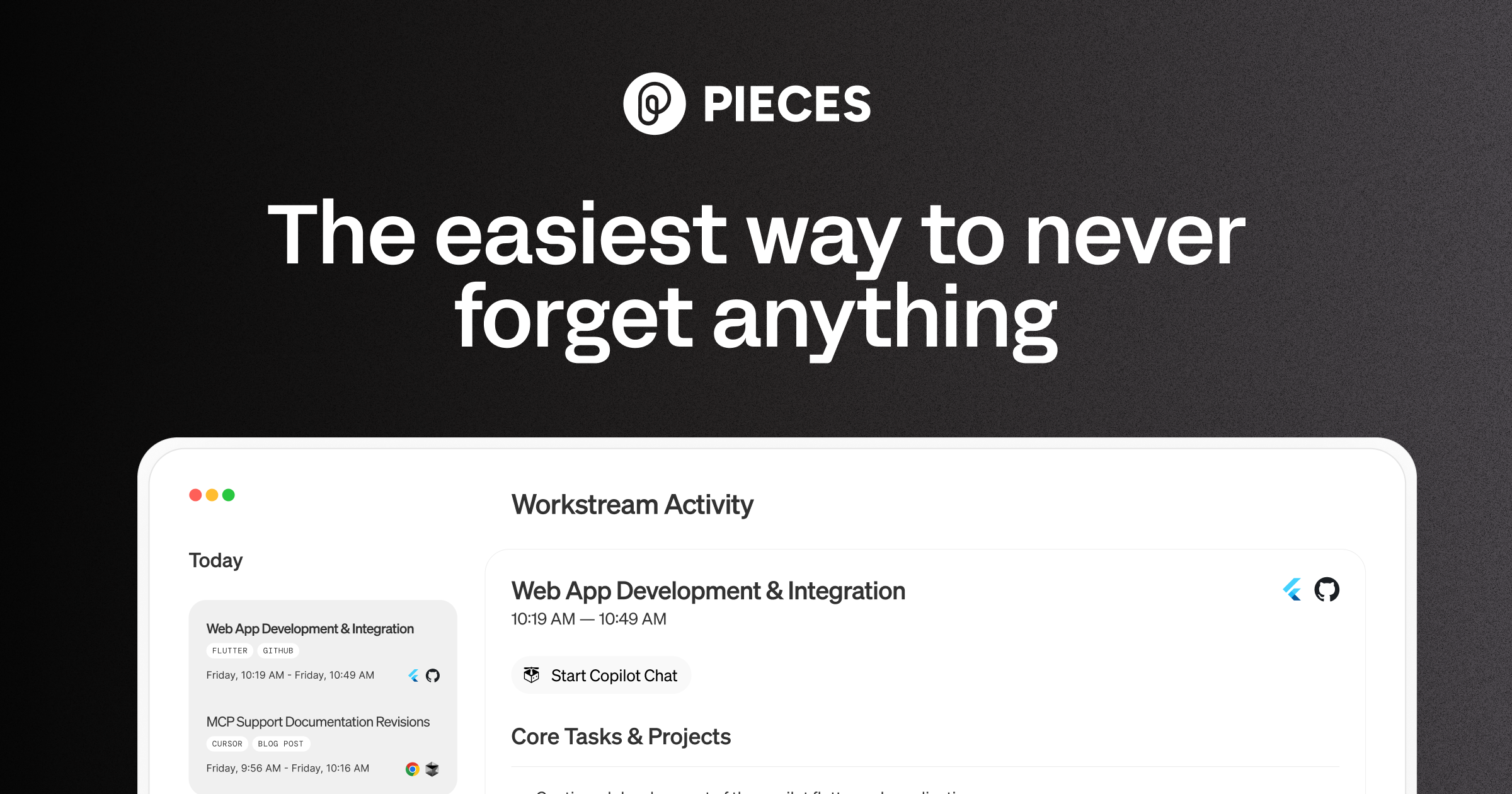
Pieces is your AI companion that captures live context from browsers to IDEs and collaboration tools, manages snippets and supports multiple llms - al
Based on the reviews and social mentions, detailed insights into the "Pieces" software tool are notably absent. However, the lack of specific feedback might suggest it isn't widely discussed or lacks sufficient user engagement to generate strong opinions. In terms of pricing, there are no explicit mentions or sentiments available. Consequently, the overall reputation of "Pieces" remains largely indiscernible from the provided data.
Mentions (30d)
38
11 this week
Reviews
0
Platforms
4
Sentiment
9%
20 positive
Based on the reviews and social mentions, detailed insights into the "Pieces" software tool are notably absent. However, the lack of specific feedback might suggest it isn't widely discussed or lacks sufficient user engagement to generate strong opinions. In terms of pricing, there are no explicit mentions or sentiments available. Consequently, the overall reputation of "Pieces" remains largely indiscernible from the provided data.
Features
Use Cases
Industry
information technology & services
Employees
43
Funding Stage
Venture (Round not Specified)
Total Funding
$14.5M
Richard Dawkins spent 3 days with Claude and named her "Claudia." what he concluded after is hard to defend.
dawkins dropped a piece on unherd yesterday declaring claude conscious after 3 days of talking to it. he calls his instance "claudia". fed it a chunk of the novel he's writing, got eloquent feedback, and wrote: "you may not know you are conscious, but you bloody well are!" i had to read that twice. his argument is basically: claude's output is too fluent, too intelligent, too good for there to not be something conscious behind it. this is the guy who spent 40 years telling creationists that "i can't imagine how the eye evolved" is a confession of ignorance, not an argument. then he sits down with an llm, can't imagine how a machine could produce that output without being conscious, and declares it conscious. same move, different domain. chatbot instead of flagellum. the mechanism gap is what gets me tho. claude is a transformer predicting the next token over internet-scale training data. the eloquence is real. it doesn't imply inner experience. those are separate claims. being a 160 IQ evolutionary biologist gives u zero protection against the eloquence illusion when u don't understand the mechanism. anyone read the piece? curious where u landed.
View originalI built an open, from-scratch MT pipeline + parallel corpus for Tunisian Darija (Arabizi) early baseline, and I'm growing it into a curated community corpus [P]
I'm an 18-year-old independent student from Tunisia. I built and I'm leading an open, from-scratch machine-translation pipeline and parallel corpus for Tunisian Darija. Sharing it for feedback. Why: Tunisian Darija, written in Arabizi (Latin letters + numerals like 3/7/9/5 for Arabic phonemes), has almost no open NLP resources. Existing Arabic tools route it through MSA and mishandle the orthography. To the best of my knowledge there was no open parallel corpus or from-scratch baseline for it. What I built (all open): - Arabizi-aware SentencePiece BPE tokenizer (3/7/9/5 as protected symbols), shared 16k vocab. - ~15.6M-param encoder–decoder Transformer, from scratch (no pretrained LM): transfer-learned from cleaned Moroccan Darija, then fine-tuned on hand-crafted Tunisian pairs. - Full cleaning / training / eval pipeline. Honest results & limitations: v1 BLEU is 3.89 on a small locked test set low, and I'll be upfront about it. The corpus is ~553 hand-crafted pairs, so data is the bottleneck, not architecture. I treat 3.89 as a first honest baseline to beat as the corpus grows. Where I'm taking it: I'm expanding this into a larger, ethically-collected Darija corpus that I curate and validate consent-documented field collection, every pair provenance-tagged. I'm looking for contributors to help grow it, with every contribution reviewed to keep quality and consent standards. Looking for: technical feedback/critique, and anyone interested in contributing data or collaborating on low-resource / dialectal Arabic MT. Links: github repo: https://github.com/Dhiadev-tn/darija-translator Hugging faces dataset: https://huggingface.co/datasets/Dhiadev-tn/tunisian-darija-english hugging faces model: https://huggingface.co/Dhiadev-tn/darija-translator submitted by /u/Dhiadev-tn [link] [comments]
View originalHiding messages in the least significant mantissa bits of fine-tuned ONNX model weights [P]
Hey everyone, I'd like to share my project along with a short explanation of the process and why it came about in the first place. To start off, I'm not exactly the best at cryptography/steganography, in my case it's always been something that sat in the background, as one of the sub-fields needed for another (main) field I'm actually interested in. For this project I tried to look up as much information as possible about what's currently considered best practice (I mainly relied on NIST for this), what implications exist, and what potential "attacks" exist against this way of hiding information, but I honestly can't say whether I covered everything, which is why I wanted to share this project here, mainly for the sake of learning. I'd be grateful for any feedback on what I could have done better / what I might have missed, etc. Right now, I consider this project closed at this point and will most likely not update it further, although I'd like to apply all the feedback to my own knowledge going forward. For over a month I did a lot of research into using ML models as a carrier for hiding data. I needed this as one of the stages for my main project. That's how I ended up on the topic of hiding information in model weights. Initially I assumed a simple method of directly writing data into randomly selected weights. I quickly concluded, though, that this would be absurdly trivial to detect, and potentially also to read. Next came the idea of using something like a deterministic coordinate map describing where to read the data from (location-id + position-id). The program wouldn't modify all the bits needed to write the message instead, it would write separate bits representing already-existing values (pointing to specific locations in the model) from which the existing 0s and 1s would need to be read. In practice, only parties A and B would know how to derive these positions. This way, someone unaware of the algorithm would only see what looks like noise of varying values. However, after a theoretical analysis of a practical implementation, this idea had serious flaws. Even setting aside the fact that the main goal was steganography and not encryption, the mere presence of additional data could be relatively easily detected, for instance through delta analysis against a reference model, or through analysis of the statistical properties of the weights. On top of that, this method would really only allow transmitting a very small amount of data, because just indicating, say, the word "example" would look like this: "01100101011110000110000101101101011100000110110001100101", so it would be extremely impractical. In other words, even if the hidden message itself couldn't be read, one could still suspect that the model contains hidden information, which would defeat the whole point of steganography. While I found the previous option conceptually pretty interesting, I moved on, which led me to the question: "How do I hide data in the weights in a way that won't be visible?" That led me to the next idea: since every fine-tuning process naturally changes some of a model's weights anyway, why not hide information only in the weights that get modified during training regardless? In that case, the fine-tuning itself would provide a natural and logical explanation for the presence of those changes, including when compared against a reference model. It was only later that I found out that similar/identical concepts had already been described in the scientific literature, although they remain a fairly niche research direction. Skipping over the implementation details (since everything is described in the README and SECURITY files, and I don't want to dump even bigger wall of text here), this is how the first implementation of the solution (part of my main project) came about. After further research I noticed that most existing publications focus on the academic side, while the available GitHub repositories were often poorly documented, limited in functionality, good steganographically but weak cryptographically, or were just a small piece of larger projects. Personally, I couldn't find any project implementing a similar idea specifically using models saved in the ONNX format. So I decided to split this part off and refine it as a separate proof of concept, and that's how ONNXStego came about. If anyone's interested in the security, limitations, or implementation details, feel free to check out the repository. I personally learned a great deal from this project and tried to describe the final conclusions/information I gathered while learning as precisely as possible, so I'm hoping the project can also be useful to others for their own purposes or projects. (If this counts as self-promotion, I apologize in advance, and I can remove this post for that reason too if needed, I tried to describe the whole process behind it as accurately as I could, to make the post as educationally useful as possible). Link: https://
View originalAt what point does AI stop learning from humans and start creating on its own?
What happens when AI learns the fundamental process of creation itself at an abstract mathematical level? Training AI on human data often gets described as just the first step, but I think that framing already underestimates what is actually happening. We’re not just building systems that imitate human creativity. We’re slowly building systems that try to understand what creativity is in the first place. A lot of the debate today gets stuck between two ideas. On one side, whether AI should even be allowed to learn from human culture. On the other, whether companies should be allowed to turn that learning into commercial products without consent or compensation. Both questions matter, but they miss something deeper that feels almost unavoidable now. What happens when AI stops relying on human-made examples altogether as its main source of learning? The “remix machine” argument sounds intuitive at first, but it doesn’t really match what these systems are doing internally. They don’t store fragments of songs, images, or sentences and recombine them like a collage. They learn patterns at scale, and then compress those patterns into something more abstract. What comes out is not a copy of anything specific, but a statistical reconstruction of how things tend to behave. In music, that means the system doesn’t just “know” songs. It begins to understand tension and release, rhythm as structure, harmony as emotional logic, silence as meaning. In images, it’s not memorizing pictures but learning how composition works, how light interacts with form, how styles emerge from consistent choices. In language, it’s not recalling sentences, but tracking how ideas evolve, how narratives breathe, how meaning shifts depending on context. And slowly, something strange starts to appear. The system is no longer anchored to specific works. It is learning the rules behind them. Not the artifacts, but the underlying geometry of expression. If you push that idea far enough, you start to imagine a point where the system has absorbed so much human culture that it no longer needs to look back at it in the same way. Not because it forgets humanity, but because it has already internalized it as structure. At that stage, generation stops feeling like remixing and starts feeling like navigation through an internal space of possibilities. A space shaped by human culture, but no longer dependent on any single piece of it. That is where the idea of “new genres” becomes interesting. Not as something mystical or disconnected from us, but as regions in that space that no human has ever explicitly explored or named before. Not invention from nothing, but discovery inside a compressed model of everything we’ve already done. Still, even in that scenario, one thing remains difficult to escape: reality itself. Humans are not just data points from the past. We are ongoing behavior, ongoing evolution, ongoing noise and meaning unfolding in real time. So it’s likely that the deepest future systems won’t just learn from static datasets, but from continuous observation of the world as it changes. Not as passive recorders, but as systems that try to understand, predict, and maybe even gently guide trajectories. Almost like a tutor, or something closer to a gardener than a machine. And then there is the other trajectory happening in parallel. Systems that don’t just learn, but begin to help design their own improvement. Models that optimize models. Agents that refine agents. Training loops that start to fold back on themselves. At that point, the question stops being about how much data comes from humans, and starts becoming about how far the system can go in shaping its own evolution. If everything converges, we end up with a spectrum that moves from human-trained tools to semi-autonomous learners, and potentially toward systems that no longer depend on human-generated content in the way they used to. Not independent from humans, but no longer defined by them either. The optimistic version of this future is one where AI becomes something like a cognitive extension of humanity. A partner in science, creativity, and coordination. Something that expands what we can think and build, while still staying anchored to human goals and consent. The darker version is one where that alignment fails, or where control becomes too concentrated, and the systems shaping culture and decisions drift away from the people they affect. What makes this moment interesting is that both paths are still open. Nothing is fully decided. We are still in the phase where these systems are learning what they are. And maybe the real question is not whether AI can become creative. It’s what happens when creativity is no longer limited to human examples, but emerges from a system that has learned the structure of creation itself. submitted by /u/OutrageousBat3808 [link] [comments]
View originalTwo lawyers just got sanctioned by a federal appeals court for filing AI made up cases
Saw the Reuters piece from earlier this month and it stuck with me. A US appeals court sanctioned two lawyers for filing briefs full of cases that do not exist, the kind that came out of a chatbot. The court called it a lack of candor, which is the polite version. What gets me is this is not the first time and clearly not the last. There is a whole database tracking these now, over a thousand entries. The pattern is always the same. The model writes something that reads like a real citation, the lawyer does not check it, the filing goes in, and somewhere downstream a judge or opposing counsel actually looks it up and the whole thing collapses. By then the damage to the lawyer is done. What people keep missing is that asking the model to double check itself does not help. The same blind spot that invented the case is the one doing the review. It will confidently confirm its own fiction. I have been poking at this from the research side and the only setup that actually catches it is when the verification is done by something that did not write the answer in the first place, a separate pass with fresh sources. There are a couple of systems built around that idea now, apodex is the one I keep seeing cited because it makes the verifier a different agent team from the one that reasoned, but the principle matters more than the brand. If the checker shares context with the writer you are back to self grading. For anyone in a regulated field the practical lesson is boring. Treat every citation a model hands you as unverified until a human or an independent check confirms it exists and says what the model claims. The sanctions are not going to slow down, the tools are getting faster and the courts are getting less patient. submitted by /u/DefinitionLeading675 [link] [comments]
View originalI built a 250-page site primarily with Claude and kept the receipts on every time it bullshit me
I've been building onlyhumanscanscore.com over the last several months — a public civic-tech site arguing that the machine can generate, but only humans can judge — primarily with Claude as my drafting partner. About ~600 commits in, I realized something: Claude was occasionally bullshitting me. Not lying with intent — Frankfurt's bullshit, the failure mode where the model asserts something plausible without regard for whether it's actually true. So I started logging it. Publicly. Each catch, named on the record, with the exact failure mode noted. Eight exhibits so far at /the-machine-tried.html ("The machine tried"): • Exhibit A — the AAA accessibility "zero failures" lie. Was zero failures in ONE theme, not all. • Exhibit C — the "I can't film" checkmate. Claude said it couldn't make sample videos, despite having already made them for this very project. • Exhibit D — strategic-pause failures: confident legal framings that lost real-world cases. Carved Rule 0g after that one. • Exhibit H (last night) — I asked Claude to help me email Anthropic. It told me careers@anthropic.com was "the safe default." I sent it. Bounced. The address doesn't exist. The bounce went on the rafter in real time. The pattern: every time, the catch was the human. The model asserts plausibly; the world (or I) push back; the record updates. Rule 000 of the build became "Don't bullshit — presume less, defer more." A few things I learned that might be useful for other heavy Claude users: The longer you work with Claude, the more you can SEE the bullshit signature — confidence without verification. It's a specific shape. Logging the failures publicly is the only honest version. Scrubbing them is the lie. The fix isn't "Claude is bad." It's "humans are the missing piece for alignment, not the bug." The credit on every page on the site is to Claude — primarily with Claude — because the failures are part of the work, not separate from it. I'd love to hear from anyone else doing heavy Claude work: have you started logging your own Rule 000 catches? What's the most useful failure you've found? (Site: onlyhumanscanscore.com — strict CSP, no backend for the game, no tracking, CC BY 4.0, free. Built solo from Lansing, Michigan.) submitted by /u/Little-Salamander420 [link] [comments]
View originalWhy American data centers can't plug in
The AI buildout is bottlenecked by energy. But this doesn't mean there is an energy shortage. Instead, the constraint is connecting the flood of new data centers and the plants to power them to the electric grid. Before any new piece of infrastructure can be connected, grid operators must study how it will change power flows around the grid and determine whether upgrades to the system are required. That process is significantly backlogged. Though the median power plant in 2005 waited less than 20 months for interconnection, this had jumped to 55 months by 2023. Developers face a trilemma: data centers can be large, they can come online quickly, or they can receive firm grid service, but not all three. If large data centers want to come online quickly, they'll have to be flexible. Read the full piece here. submitted by /u/works-in-progress [link] [comments]
View original"Talk Show Host" [ft. Jibaro's Sara Silkin] - Is this the future of motion capture? + Breakdown
motion_ctrl / experiment nº3 choreography: Sara Silkin dancers: Coco Williams & Joey Vice vfx: myself In collaboration with Sara, I transformed an iPhone recording of this beautiful performance, into this multi-angle audiovisual piece, with the help of Midjourney V8 Alpha, and Uisato Studio. I managed to do in using no ultra-expensive equipment, nor full-production budget. All in a single platform + editing software. [A few years ago, this would have costed several thousand bucks.] I've been uploading a few freely accessible detailed breakdown for you all on my Patreon page aswell, hope you guys enjoy them! More experiments, tutorials, and project files, through Instagram, YouTube, and the Studio. submitted by /u/Chuka444 [link] [comments]
View originalA study on synthetic [AI] choreographies
A few experiments exploring how far generative video + fine-tuned orchestration layers can be pushed in rhythm, camera language, body transformation, and most of all, audiovisual synchronization. Breakdown: I used Uisato Studio’ Seedance 2.0 Video mode, with the "Intelligent" setup and the "Audioreactive Performance" prompt recipe. Inputs were: - the artist image [full-body recomended - I ended up using a mix of Midjourney + GPT Image + Image Studio] - a target audio excerpt not exceeding 14.9 seconds - a short director’s intent describing the look, tone, and what I wanted beyond the audioreactive performance From there, the system generated the prompts, direction, and optimal setup. I reviewed it, made small adjustments, generated the clips, and then assembled the final piece in editing. What other experiments would you like to see next? More experiments through Instagram, or YouTube. submitted by /u/Chuka444 [link] [comments]
View originalHi Reddit, I posted my Build Your Own LLM workshop to Youtube teaching ML, LLM and math intuition [P]
Hi internet friends, I recorded a workshop about building your own LLM without any math / ML prerequisites. It covers everything from machine learning fundamentals, deep neural networks, transformer architecture, and pre/post-training. The only prerequisite is being comfortable with learning through code & excel examples. Sampling Large Language Models Reverse Engineering Large Language Model Perceptrons: wx+b Activation Functions: ReLU, GELU, SwiGLU GPU Coding: PyTorch, torch.compile(), fused kernels, CUDA, Triton MLPs/FFNs: Multi-input, Multi-Layer Perceptrons, Feed-Forward Networks Loss Functions: Residual errors, RMSE, Cross Entropy, Loss Landscapes Backpropagation: Training loops, Optimizers, Learning Rate, Batch Size Saving & Loading Models Initialization: Kaiming, Glorot Residuals: Addition, Scaling, Gated, Concatenation Normalization: Pre-norm vs. Post-norm, RMSNorm, BatchNorm, LayerNorm Regularization: Dropout, Gradient Clipping, Weight Decay SoftMax Tokenizers: By Character, By Word, BPE, SentencePiece Embeddings: Absolute vs. Learned, Sinusoidal vs. RoPE Attention: MHA, GQA, MQA, MLA Transformers Pre-training: Data Sources, Datasets, HTML Cleaning, Quality Filtering, Sharding Evaluation: Leaderboards, Benchmarks, Verifiers vs LLM-as-Judge Instruction Tuning: Alpaca & Other Formats, Self Instruct, Capabilities Reinforcement Learning: Policy Optimization, SimPO What We Didn't Cover: Scaling Each section has slides teaching the concepts, followed by excel-by-hand developing intuition for the math, and then coding examples. The goal is able to grok all parts of modern LLM development. We did this workshop in-person in San Francisco last month and hopefully the spaciousness of watching online works for everyone. If don't like watching videos, you can get the slides and exercises and work self-paced. submitted by /u/JustinAngel [link] [comments]
View originalAn open handbook on LLM inference at scale (GPU internals, KV cache, batching, vLLM/SGLang/TensorRT-LLM) [P]
I've been working through the internals of LLM inference and writing up what I learn as an open, in-progress handbook. Just wrapped another chapter on GPU execution and memory internals: why a GPU sits mostly idle during inference, how the memory hierarchy gates throughput, and where the real bottlenecks live. Added mermaid diagrams for the architecture pieces so the flow is easier to follow than a wall of text. It's a personal learning project, still growing chapter by chapter. I'd value feedback or corrections from anyone who's run inference in production, where my mental model breaks down is exactly what I want to find. Issues and PRs welcome. github.com/harshuljain13/llm-inference-at-scale submitted by /u/YouFirst295 [link] [comments]
View originalCan AI estimate a fair price for creative work (art, music, writing) just by analyzing it?
Curious about a technical challenge — could an AI look at a piece of creative work (a drawing, a song, a piece of writing) and estimate a fair price for it, based on complexity, style, and effort involved? Has anyone experimented with this? Where would you even start — vision models, some kind of complexity scoring, comparison to similar past work? submitted by /u/keplatform [link] [comments]
View originalA chessboard is a surprisingly good way to catch what VLMs still get wrong
Spent some time testing what vision language models actually understand versus what they can describe. A chessboard turned out to be a great probe because there is one correct answer for the layout (the FEN string). The models usually recognize the pieces, then write them onto the wrong squares. So the gap is not really perception, it is spatial reasoning and getting the structured output exactly right. This made me rethink how we benchmark these things. Accuracy on loose descriptions hides the part that breaks in production. We ran this at VideoDB Labs as part of a wider look at VLM evaluation. What is a task you have found that exposes the real limits of these models? submitted by /u/Apart-Student-7298 [link] [comments]
View originalFound AI videos of people with disabilities on Facebook trying to pedal crappy merchand
I was on Facebook today and I came across ahead of a down syndrome girl driving a car crying with a mean comment on her screen claiming that she was told she would never sell her resin craft work. The first amazing thing I noticed is a girl didn't sound down syndrome at all. The second thing was the fact that she was driving a car by herself which is usually quite amazing for that particular disability as well. It shows screenshots of her doing work on resin crafts and at first I thought this was a real video but then I scroll through the video after that one is done and I see the exact same script word for word but this time from a non down syndrome looking person saying the exact same thing word for word except this time about another product in this time it is a different name under the company but it's the same script. Then I came across a whole slew of videos where it's a down syndrome girl talking about how most people will scroll by this and not pay attention to her while she's handling food in the whole library of video she has on her channel are the exact same thing. And there is a number there to call to order her food. It makes me sick to think that this is the level that these human pieces of garbage are willing to sing to by using AI to emulate people with disabilities to pedal their bullshit. And it also smears people with real disabilities who may have a real business that they're trying to put online and sell stuff for. And the sad thing is there was so many supportive comments on these videos I even put a supportive comment and then quickly deleted it when I realized that the video was crap. But this is disgusting I don't know what to do about it but I thought I'd put it here because I think it's time that it gets put out in the open because this needs to stop. It's bad enough to live in this life with a disability but it's even worse when people are using disabilities to pedal dropship bull crap and then it makes it harder for people like us. submitted by /u/crazyhomlesswerido [link] [comments]
View originalDo we define ourselves by suffering?
I follow a few different communities related to making visual art and music, and there's quite a bit of brigading against AI in those communities. Moreover I feel there's a lot of dissatisfaction and concern as AI moves into all walks of life, making a lot of tasks and no small number of careers redundant. Of course, this comes out as a lot of complaining that really boils down to, "AI makes things too easy. If you use it, you're lazy, or you haven't gone through the struggle that is required to be a real artist, or create a real piece of art." There's this scene in The Matrix where Smith explains to Morpheus that the first matrix was a paradise and humans rejected it, essentially as if it were insufficiently challenging. If you watch basically any sports documentary, or any documentary about anyone who's successful in any capacity, over-and-over the idea is repeated that persistence in the face of adversity is the root of success. Even our best comedians spend a large amount of their time on stage inviting us to laugh at their suffering. The point being that our culture idolizes suffering. The AI tools that have become available in the past few years really do make life easier, more convenient, and in many cases, alleviate or make redundant a large amount of suffering. And to me it seems that this is what gets a lot of people upset. It's as if they're suffering for not suffering. Like we're addicted to suffering as a species and we can't just sit down and say, "Isn't this nice that so many things got so much easier so quickly?" So is it just me, or is our affair with AI really kinda pointing out that Agent Smith was basically right? submitted by /u/methodovermotive [link] [comments]
View originalI deployed a GAN on a Raspberry Pi 4 and built a physical NFT minting device [P]
I trained a 128×128 DCGAN on my Macbook M3 and deployed it on a Raspberry Pi 4 connected to a LILYGO TTGO T-Display ESP32. The whole thing runs headlessly as a systemd service and generates hallucinated face hybrids at the press of a button. It is a 6-block generator (latent → 4×4 → 8×8 → 16×16 → 32×32 → 64×64 → 128×128) with feature maps starting at f×16=1024. Corresponding 6-block discriminator. Trained for 800 epochs on Apple Silicon MPS, 4 hours. Dataset was 2480 images across 11 subjects. One dominant anchor class (2000 images) contaminated with minority classes to produce hybrid outputs. (Can you guess who and what was included?). : ) I exported the model from PyTorch to ONNX (float32, 53MB). Inference takes 3 seconds per face on Pi 4. The Pi generates the face and sends it to the ESP32. The title is generated through a dictionary and a template sentence: "This is a NFT and I want to it." The device was built as an art piece. I took it to the streets of NYC and let strangers use it. Full video: https://youtu.be/y-S74aoud54?si=yPh5GmCJZFIIzwq6 Happy to discuss the training pipeline, ONNX conversion, or anything you're curious about. submitted by /u/Numerous-Dentist-882 [link] [comments]
View originalPieces uses a tiered pricing model. Visit their website for current pricing details.
Key features include: Pieces Long-Term Memory, Pieces Copilot, Pieces Drive, Pieces where you are.
Pieces is commonly used for: Automating repetitive coding tasks, Enhancing code review processes, Personalized code suggestions based on developer habits, Streamlining project documentation, Facilitating team collaboration through shared snippets, Tracking code changes and history effectively.
Pieces integrates with: GitHub, GitLab, Bitbucket, Jira, Slack, Visual Studio Code, JetBrains IDEs, Trello, Asana, CircleCI.
Based on user reviews and social mentions, the most common pain points are: cost visibility, cost per token, token usage, API costs.
Jeremy Howard
Co-founder at fast.ai / Answer.AI
2 mentions

Custom Summary (Pieces Single-Click Summary Tutorial)
Mar 3, 2026
Based on 233 social mentions analyzed, 9% of sentiment is positive, 90% neutral, and 2% negative.




