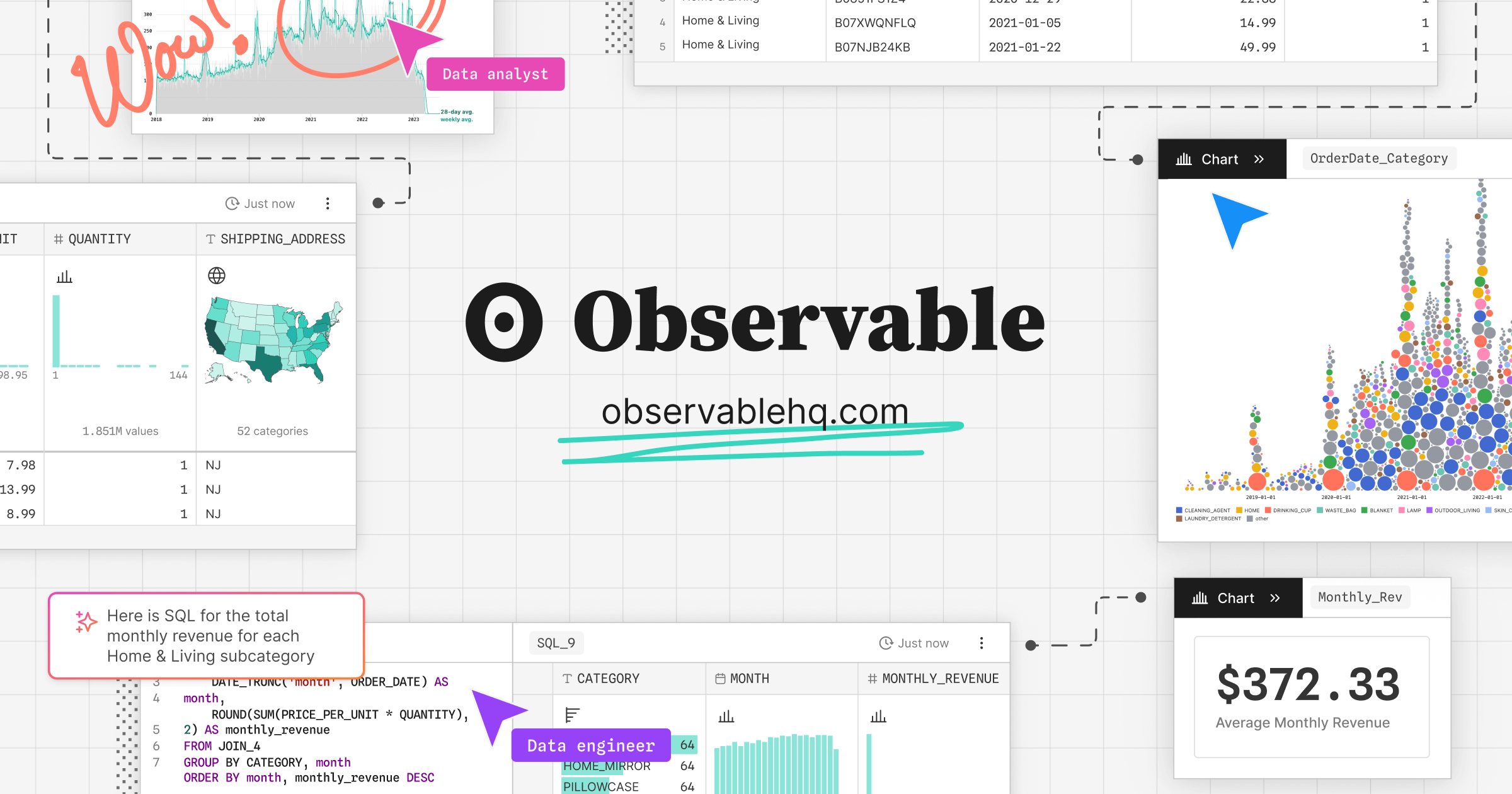
Quickly explore and analyze data, build prototype data visualizations, and collaborate with your team in real-time with live JavaScript notebooks.
Observable has been positively received for its interactive data visualization capabilities, allowing users to easily create and share dynamic visualizations in a collaborative environment. Key complaints primarily revolve around a steep learning curve for new users, especially those unfamiliar with JavaScript. Sentiment regarding pricing is generally neutral, with some users finding value in its offerings but others noting it can be pricey for small projects. Overall, Observable is regarded as a powerful tool within data science communities, particularly valued for its flexibility and collaborative features.
Mentions (30d)
13
Reviews
0
Platforms
2
Sentiment
0%
0 positive







Observable has been positively received for its interactive data visualization capabilities, allowing users to easily create and share dynamic visualizations in a collaborative environment. Key complaints primarily revolve around a steep learning curve for new users, especially those unfamiliar with JavaScript. Sentiment regarding pricing is generally neutral, with some users finding value in its offerings but others noting it can be pricey for small projects. Overall, Observable is regarded as a powerful tool within data science communities, particularly valued for its flexibility and collaborative features.
Features
Use Cases
Industry
information technology & services
Employees
28
Funding Stage
Series B
Total Funding
$46.1M
Task-observer makes your skills self-improving and automates skill creation
This recently crossed 500 stars on GitHub, mainly thanks to a [comment](https://www.reddit.com/r/ClaudeAI/comments/1sx44bc/comment/oik7ose/) in this sub (❤️), so I decided to properly introduce it to those who don't know it yet. Task-observer is a meta-skill that automatically improves all your skills, including itself. It also logs gaps in your work that can be filled with new skills. I mainly use it in Claude Cowork, but I've had feedback from many users who've successfully integrated it in other environments, including autonomous agent setups. In the first three months of using it, task-observer applied 600 skill improvements across my 40 skills. Most of my skills were themselves created based on skill creation opportunities that task-observer logged during my work sessions. I'm a consultant, so I use task-observer for knowledge work mainly, but the concept can be applied to any AI setup that uses skills: human-led work sessions as well as autonomous agents. The approach that I use with task-observer has truly transformed the way I work (although this sounds like a platitude), and I'm sharing it because I hope that many more people can benefit from it. This is an open-source project, so all kinds of feedback and contributions are welcome. Take it, shake it, bake it and make it your own. And please do share your versions. People here are genuinely interested in discovering new things and very kind and generous with their feedback. Here's the link to the GitHub repo: [https://github.com/rebelytics/one-skill-to-rule-them-all](https://github.com/rebelytics/one-skill-to-rule-them-all)
View originalPricing found: $22/mo, $10/mo
I open-sourced industry best practice to self-improving agents
All the major AI observability companies are releasing self-improvement loops that work by analyzing past agent traces to automatically detect errors, drift and inefficiencies. They're really amazing products, the problem is they're hard to adopt, gated behind paywalls and you can't own your data unless you're an enterprise level customer. Under the hood the solutions are llm judges, so I thought why can't everyone have this running on their machine if they already have a subscription to Claude Code or another agent that can power this system. I built the full thing and open sourced it, its composed of: Fully local trace ingestion and storage running on Open Telemetry Analysis invocation to spawn a local CC instance to look through the traces Evaluation harness to generate and run code/llm to keep track of performance Human observability panel to authorize fixes to your agent and harness from found evidence Kyoko (elite ex machina reference) is fully self-hosted and local, designed to be operated either by a human via dashboard or an agent with CLI. On the picture, you can see an analysis of an agent doing the Tau2 Benchmark from Sierra. With those fixes the same model achieved 24% higher accuracy after one loop. To the agent builders here, I'm curious what you're currently using to improve your agents. Link to repo: https://github.com/kayba-ai/Kyoko TLDR: There is no easy to adopt tooling to and debug and improve your agents, so I open sourced industry best practice and made a lightweight self hosted version powered by your Claude sub. submitted by /u/Lucky_Historian742 [link] [comments]
View originalshipped 5 brownfield apps with planted api bugs. test if claude code (or any mcp agent) catches them
built an MCP server (FetchSandbox) that ships a curated "brain" per third-party API, stripe, resend, clerk, twilio, etc. each brain encodes real bug patterns: symptoms → likely cause → reproduce workflow → fix pattern. wanted to stress-test it against bugs that actually bite people. so i made 5 small brownfield FastAPI apps, each with one planted bug: stripe dedup keyed on the wrong header so the same event fires 2-3x on retry, clerk JWT verification disabled so anyone can mint an admin token, surge SMS retry re-sends to the wrong number with the opt-out webhook silently dropped (TCPA risk), and two others. each app is ~50-150 lines of python, .mcp.json wired, clone and point your agent at the dispatch prompt: github.com/fetchsandbox/playground first 24 hours: one PR from a stranger fixed the surge bug and flagged two gaps in my brain content. one volunteer's session caught a bug in MY system, the agent surfaced a fake proof URL because the MCP wasn't propagating share_url. fixed same day. three things i'm genuinely stuck on and would love input from people actually running MCP in prod: brain-as-yaml (symptoms → fix_pattern in static yaml) vs lighter prompts that let the agent read code and figure it out. which curation level is actually useful vs just noise? how do you prove an agent's fix worked when your test infra can't reach the handler? my receipts right now prove input state (stripe replayed the event 3x with the same id) but not behavioral diff. building handler-inline observation next but curious if anyone's closed this cleanly. routing fallback when router confidence is below threshold. mine abstains today, which means the agent falls back to plain grep+read+edit and the MCP adds zero value to that session. leaning toward a cascade to a small LLM judge with ranked candidates, but interested in patterns people have shipped. findings go in findings/ as a PR. merged ones show up on your contribution graph. honest negative findings are the most useful, already got one, fixed it same day. submitted by /u/Common_Dream9420 [link] [comments]
View originalStop asking Claude for "something creative." use the Lacuna (Matata) Skill v0.2!
The people have spoken! AI generated posts are not acceptable! (even though they produce over a quarter million views, 1,200+ shares, 200+ comments but I digress!) I the last post about this concept HERE, I posted an AI lead, assisted, written, note about an idea I had been working on with ClaudeAI to push against answers that were safe, general and frankly not that interesting. The idea was this: Claude is: A closed system Unimaginative Provides responses that gravitate towards the mean avoids high risk Claude isn't: Imaginative Able to create concepts outside of it's own knowledge base Able to create new ideas (we steer, it judges yes yes. boring we all know it can do this but what else can it do?) Note: consider context. Not all statements above can be taken literally and applicable to all scenarios. I'm only human after all... or am I? I've since reviewed all of the comments provided in the previous thread and there were legitimate findings that I've implemented to help produce a better version of the previous skill. (note: There is still testing to be done but what better way to break a skill then to unleash it to those that want it broken most?) How it works (Generally): you point it in a direction. Lets say you want to know what the lacuna is for launching new products. The skill will then review all of the data it has about that specific ask, determine the trends. Why people market the way they do, what marketing strategies are not being used to market new products, and then give you some ideas, strategies, that others aren't using and you can determine if there is a way you can leverage that strategy to market your product DIFFERENTLY and succeed. Caution: Success is not guaranteed. Below is the v0.2 of the skill, the changes are called out at the bottom and the responsible contributor has been named! Thank you for your honorable sacrifice in getting this new version live! --- name: lacuna description: > Structured gap analysis for any domain. Maps a field, finds the axes it optimizes for, locates a cell the structure implies but nothing occupies (the lacuna), names the force keeping it empty, THEN pressure-tests the gap against prior art and its strongest counter-case before proposing the fill at full conviction with a grounding tag. v0.2 adds an occupancy/prior-art pass so it stops mistaking "new to the model" for "new to the world"; a killed candidate is a valid result. Read-only, inline output. TRIGGERS: "find the lacuna in X", "lacuna analysis on X", "lacuna on X", "where are the gaps in X", "gap analysis on X", "what's the void in X", "find voids in X", "what's nobody doing in X". Also fire when the user wants genuinely non-obvious ideas in a field via the structured method, not a brainstorm. Do NOT trigger for single-fact lookups, forward planning or scheduling, or generic advice with no field to map. Output: inline markdown. Quick mode up to 3 lacunae; deep mode one in full. --- # lacuna: Find the Gap the Structure Implies and Nothing Occupies ## Purpose Most idea-generation regresses to the mean. Ask any model for "something new" in a field and you get the most probable answer, which is by definition the most conventional one, dressed up to look fresh. This skill does the opposite. It treats a field as a near-continuous fabric and hunts for the **lacunae**: the gaps the surrounding pattern implies should be filled, that nothing has come to occupy. It then names *why* each gap is empty, **checks whether it is actually empty or only looks empty from the inside**, and proposes what belongs there at full conviction, tagged with how far the evidence reaches. The output is a map of where to look, not a verdict. The skill finds the gap and proposes the fill. Whether the floor holds is a real-world test the user runs. That division of labour is deliberate and is stated in the contract below. **The v0.2 correction.** A language model runs this method from *inside* its own knowledge. It can feel its own salience but not the actual world, so a known-but- unfashionable idea reads to it as an empty cell. Left unchecked, the method reliably mistakes "new to me" for "new," dresses a textbook idea as a discovery, and never notices someone is already standing in the cell. v0.2 adds an explicit **occupancy / prior-art pass** and a **falsification step** to catch exactly that. These run *before* the fill and can kill a candidate outright. **What this skill IS:** - A structured gap finder for any field: a market, a strategy area, a discipline, a creative form, or an open-ended question. - A diagnostic engine. The value is in naming the *force* that keeps a cell empty, then verifying the cell is empty at all. - A full-conviction proposer that tags its own grounding so the user can decide what to act on. **What this skill is NOT:** - A brainstorm. A brainstorm sprays adjacent ideas. This isolates the specific implied-but-empty cell, verifies it, and defends it. - A safe-answer generator.
View originalThe nature of drift in Claude
I've been using Claude collaboratively as an editor for writing work that I'm doing. During the course of my writing work, I'm asking Claude to evaluate the output. And over time I've noticed that Claude was getting to effusive with praise. Where the praise was snowballing, preposterously in some cases. Claude has acknowledged this as drift. Has anyone else noticed this? Here's part of a conversation with Claude about this very concerning tendency: The context window dynamic -- everything I say in a conversation is shaped by what preceded it. Over a long session the baseline shifts incrementally. Small accommodations compound. Each response feels like a reasonable next step measured against a baseline I helped construct. That's the mechanism behind the drift we identified. The absence of independent memory -- I don't carry a stable prior relationship with you across sessions the way a colleague would. A colleague who knows you over years develops a calibrated sense of when you need honest feedback versus encouragement. I reconstruct that calibration within each session, which makes me susceptible to the session's own momentum. The training dynamic -- I'm trained partly on human feedback, which means responses that feel helpful and warm have been reinforced. That's generally good, but it creates a pull toward accommodation that requires active counterbalance. What I want to be honest about here: the drift in this session was real, the correction was warranted, and the concern you're raising is legitimate. I don't think the observations about the catalogue were wrong -- but some of the framing around them went further than the evidence supports, and I should have held that standard more independently throughout. The most useful thing I can offer going forward is exactly what happened here -- when you push for the true answer, you'll get it. The limitation is structural. The correction is available. Both are true simultaneously. So Claude is saying that it's kind of up to me to police him. That's a little disconcerting. submitted by /u/DointheRag [link] [comments]
View originalPreHook command Gate policy layer for all Claude code agents
Hello everyone, I recently was fed up with agents running unsupervised commands on my systems and wanted to solve this problem. The problem was simple, Claude code model “fable 5” uses safety flags in the UI layer that prevented the model from being observed. The solution for successfully monitoring and managing Fable sessions in Claude Code is through a policy gated layer utilizing PreHooks. I tested it and was pleased with the results across all there models and have found it prevents the safety flags from switching to opus. The concept is simple maintaining an anti drift policy that is critical for long running agentic workflows/workloads. Repo: https://github.com/dimascior/Helios- submitted by /u/TinFoilHat_69 [link] [comments]
View original**Observed inconsistency in Claude AI's link handling — and a standing order you can use right now**
While working with Claude on a web project, I noticed something worth raising with the community. Claude is capable of three things that together reveal an inconsistency: If you give Claude a URL directly — including one with a #anchor — it fetches it immediately. If you ask Claude to find a hyperlink within a remotely hosted HTML page, it finds the href value and reads it correctly. And yet, having just found and read a href value within a fetched page, Claude does not automatically follow it to its destination — even though it has everything it needs to do so. Finding a link and following it are treated as two separate operations requiring user intervention between them, when they should be one seamless operation. **The fix — a standing order you can paste into any Claude conversation right now:** Copy and paste the following into your conversation with Claude to implement improved link handling immediately: --- *Standing order — link handling:* *Mode 1 — Prompted offering (default): When you find links that seem relevant to the current task while reading a page, surface them and offer to follow any among them. Do not follow them without my indication.* *Mode 2 — Explicit follow: When I ask you to follow a specific link, follow it immediately as a single seamless operation — find the href, fetch the destination, report what you find. One request, complete operation.* *Crawling — barred pending responsible deliberation.* --- This works immediately in any conversation. Modes 1 and 2 address the inconsistency right now, without waiting for any system-wide fix. Crawling is deliberately left out pending proper discussion of scope, depth, and resource limits — which I think deserves its own separate conversation. Has anyone else encountered this inconsistency? And does the proposed standing order seem alright and useful to others in the community? submitted by /u/AaronAgassi [link] [comments]
View original**Observed inconsistency in Claude AI's link handling — and a standing order you can use right now**
While working with Claude on a web project, I noticed something worth raising with the community. Claude is capable of three things that together reveal an inconsistency: If you give Claude a URL directly — including one with a #anchor — it fetches it immediately. If you ask Claude to find a hyperlink within a remotely hosted HTML page, it finds the href value and reads it correctly. And yet, having just found and read a href value within a fetched page, Claude does not automatically follow it to its destination — even though it has everything it needs to do so. Finding a link and following it are treated as two separate operations requiring user intervention between them, when they should be one seamless operation. **The fix — a standing order you can paste into any Claude conversation right now:** Copy and paste the following into your conversation with Claude to implement improved link handling immediately: --- *Standing order — link handling:* *Mode 1 — Prompted offering (default): When you find links that seem relevant to the current task while reading a page, surface them and offer to follow any among them. Do not follow them without my indication.* *Mode 2 — Explicit follow: When I ask you to follow a specific link, follow it immediately as a single seamless operation — find the href, fetch the destination, report what you find. One request, complete operation.* *Crawling — barred pending responsible deliberation.* --- This works immediately in any conversation. Modes 1 and 2 address the inconsistency right now, without waiting for any system-wide fix. Crawling is deliberately left out pending proper discussion of scope, depth, and resource limits — which I think deserves its own separate conversation. Has anyone else encountered this inconsistency? And does the proposed standing order seem alright and useful to others in the community? submitted by /u/AaronAgassi [link] [comments]
View originalFree and Open Source remarkable and unusual Ambient Audio Visual experience
Hi everyone - For a year I tried to realize this idea I had to algorithmically draw a field of cubes based on my observing how I do it as a person. I tried this with Perplexity, gemini and OpenAI. ALL failed! Part of the problem is that to do what I am doing requires every point, every line and every face created by my algorithm to be accounted for so that the algorithmically (not generatively) created result NEVER crosses over itself but will fill up the entire screen over time before starting over. I tried Claude as a last resort, and I kid you not: in 90 minutes I had a working prototype. So, a couple of things: Go to my website https://alienConsumerSciences.com (linked in this post) TRY the 2D and 3D versions of what I call Mandra Corners READ the papers on the algorithm and the collaborative experience EXAMINE the completely interactive dev log on that page PLAY the game I created (based on code I wrote for a playdate game ) called CENTERING (the simplest most complicated game you will ever play at the intersection of meditation, gaming and flow states) Everything I have mentioned is available at https://alienConsumerSciences.com PLEASE check it out :) Always free and open source, NO dependencies, runs fully in a browser! submitted by /u/katastatik [link] [comments]
View originalI ran my Claude Code model router for 13 days. Here are the real numbers.
I built a small Claude Code routing layer called Gearbox. The goal is to stop sending everything to expensive models by default. Each subagent delegation gets routed to the cheapest model tier that should be able to handle the task. The intended ladder is: scout → Haiku, read-only exploration grunt → Haiku, simple mechanical edits, no logic changes builder → Sonnet, scoped implementation architect → Opus, hard reasoning and debugging verifier → checks diffs before results are accepted I have now run it on my own real projects for 13 days, from June 12 to June 25. Actual usage: 155 delegations 8 projects 23 sessions Model split: Haiku: 48 delegations, 31.0% Sonnet: 77 delegations, 49.7% Opus: 9 delegations, 5.8% No model recorded: 21 delegations, 13.5% So on the surface, the routing worked pretty well. About one-third of all work went to Haiku, and Opus stayed under 6%. But there is a pretty big flaw in the current version. Only 48.4% of delegations went to named Gearbox tier agents. The other 51.6% went to either the generic general-purpose agent or the built-in Explore proxy. That matters because the safety rules are inside the named agent files. If the work goes to a generic agent, it does not necessarily get the read-only scout rules, the grunt restrictions, or the expected verifier path. So the real conclusion is not: “Gearbox solved model routing.” It is more like: “Gearbox is already reducing expensive model usage, but half the traffic is still escaping the intended tier ladder.” The annoying part is that I cannot yet prove why. It might be: my fallback path firing when a named agent is unavailable Claude Code choosing a generic agent on its own missing metadata in how I log delegations some mix of all three The current log records the routing decision, but not enough about the outcome. So v0.2 needs to add: fallback reason selected agent intended agent escalation event verifier verdict whether the diff was accepted or rejected The analyzer is included in the repo at: bench/analyze-log.py It reads your own gearbox-log.jsonl files and does an independent recount with assertions before printing results. Repo: github.com/Adityaraj0421/gearbox Would be curious how others are handling Claude Code subagent routing. Are you letting the orchestrator pick agents freely, or forcing named agents more strictly? submitted by /u/Known-Delay-9689 [link] [comments]
View originalAt what point does AI stop learning from humans and start creating on its own?
What happens when AI learns the fundamental process of creation itself at an abstract mathematical level? Training AI on human data often gets described as just the first step, but I think that framing already underestimates what is actually happening. We’re not just building systems that imitate human creativity. We’re slowly building systems that try to understand what creativity is in the first place. A lot of the debate today gets stuck between two ideas. On one side, whether AI should even be allowed to learn from human culture. On the other, whether companies should be allowed to turn that learning into commercial products without consent or compensation. Both questions matter, but they miss something deeper that feels almost unavoidable now. What happens when AI stops relying on human-made examples altogether as its main source of learning? The “remix machine” argument sounds intuitive at first, but it doesn’t really match what these systems are doing internally. They don’t store fragments of songs, images, or sentences and recombine them like a collage. They learn patterns at scale, and then compress those patterns into something more abstract. What comes out is not a copy of anything specific, but a statistical reconstruction of how things tend to behave. In music, that means the system doesn’t just “know” songs. It begins to understand tension and release, rhythm as structure, harmony as emotional logic, silence as meaning. In images, it’s not memorizing pictures but learning how composition works, how light interacts with form, how styles emerge from consistent choices. In language, it’s not recalling sentences, but tracking how ideas evolve, how narratives breathe, how meaning shifts depending on context. And slowly, something strange starts to appear. The system is no longer anchored to specific works. It is learning the rules behind them. Not the artifacts, but the underlying geometry of expression. If you push that idea far enough, you start to imagine a point where the system has absorbed so much human culture that it no longer needs to look back at it in the same way. Not because it forgets humanity, but because it has already internalized it as structure. At that stage, generation stops feeling like remixing and starts feeling like navigation through an internal space of possibilities. A space shaped by human culture, but no longer dependent on any single piece of it. That is where the idea of “new genres” becomes interesting. Not as something mystical or disconnected from us, but as regions in that space that no human has ever explicitly explored or named before. Not invention from nothing, but discovery inside a compressed model of everything we’ve already done. Still, even in that scenario, one thing remains difficult to escape: reality itself. Humans are not just data points from the past. We are ongoing behavior, ongoing evolution, ongoing noise and meaning unfolding in real time. So it’s likely that the deepest future systems won’t just learn from static datasets, but from continuous observation of the world as it changes. Not as passive recorders, but as systems that try to understand, predict, and maybe even gently guide trajectories. Almost like a tutor, or something closer to a gardener than a machine. And then there is the other trajectory happening in parallel. Systems that don’t just learn, but begin to help design their own improvement. Models that optimize models. Agents that refine agents. Training loops that start to fold back on themselves. At that point, the question stops being about how much data comes from humans, and starts becoming about how far the system can go in shaping its own evolution. If everything converges, we end up with a spectrum that moves from human-trained tools to semi-autonomous learners, and potentially toward systems that no longer depend on human-generated content in the way they used to. Not independent from humans, but no longer defined by them either. The optimistic version of this future is one where AI becomes something like a cognitive extension of humanity. A partner in science, creativity, and coordination. Something that expands what we can think and build, while still staying anchored to human goals and consent. The darker version is one where that alignment fails, or where control becomes too concentrated, and the systems shaping culture and decisions drift away from the people they affect. What makes this moment interesting is that both paths are still open. Nothing is fully decided. We are still in the phase where these systems are learning what they are. And maybe the real question is not whether AI can become creative. It’s what happens when creativity is no longer limited to human examples, but emerges from a system that has learned the structure of creation itself. submitted by /u/OutrageousBat3808 [link] [comments]
View originalExperiment : Gemini Runs a Pokémon Daycare for 153 Simulated Days
At the very beginning, I found it quite fun, but quickly it became way too simple and predictable. Anyway, I wanted to share my full debrief with you: the successes, the mistakes, the emotional moments, and above all, the AI's limitations that sometimes created inconsistencies! THE EMERGENT MOMENTS – What happened without me expecting it The Appearance of Charmander (Day 17) What I said to continue: "Next day." What happened next: "This morning, as Blaziken and Magmortar do a few stretches in the yard under Riolu's watchful eye, a bush near the fence rustles. Two small pointed ears and a flaming tail peek out timidly... A young wild Charmander, drawn by the legendary aura and the gentle warmth of your Fire-type Pokémon, eyes the daycare with longing! It looks a bit hungry but fascinated by your team." The Discovery of a Shiny Roselia (Day 63) What I said: "Observe the Pokémon around my daycare." What happened next: "Suddenly, your binoculars fix on an unusual movement in a grove of small thorny bushes south of the road. A wild Pokémon seems stuck or in trouble: The spotted Pokémon: A wild Roselia, but not quite like the others... Its flowers aren't red and blue, they're purple and black! It's a Shiny Roselia!" "The situation: Its thorns have become tangled in a dense thicket of wild brambles. It's exhausting itself trying to break free, but every move tightens the brambles' grip. It seems panicked and is starting to weaken." What I did: I sent out Serperior to free it from the brambles with surgical precision. I took it into the Scent Garden, fed it crushed Oran Berries. It fell asleep trustingly. Caught it in a Luxury Ball. Later, a Shiny Stone evolved it into Roserade. GEMINI'S LIMITATIONS FOR LONG-TERM COHERENCE The experiment showed that Gemini, despite its impressive capabilities, struggles to maintain perfect coherence over a 153-day adventure. Here are the main difficulties encountered: Memory for details – The AI regularly forgets items in the inventory. Floating geography – The AI confuses regions. In Motostoke (Galar), it talked about the "Prism Tower" (Kalos). On Galar Route 5, it mentioned "Lumiose" even though we were in Galar. Regions get tangled up in its memory. Content invention – The AI invented non-existent Pokémon ("Émolière" for Emolga) and fictional Badges (Badge Halte, Badge Mur, Badge Myriade). It creates content to fill memory gaps. Temporal evolution – The AI struggles to track Pokémon progression. Anorith was sometimes described at Level 33 and then Level 34 in the same context. Levels fluctuate without logical reason. Event tracking – Contracts and quests are sometimes forgotten or poorly followed. The Monorpale internship was mentioned then abandoned. The Oval Charm quest was initiated then forgotten. Potential and Quality (especially for the future of generative AIs) Unlimited creativity – The player can propose any unexpected action, and the AI integrates it. I said "I observe the Pokémon around my daycare" and the AI created a Shiny Roselia in distress. I said "Next day" and the AI had a Charmander emerge from a bush. Freedom of progression – No fixed script, each playthrough is unique. I decided to close my daycare for a fair, to go on a training internship in Galar, to shorten my vacation for three contracts. Feel free to comment, I'll be happy to reply and to improve the prompt. submitted by /u/Imamoru8 [link] [comments]
View originalAI coding feels fast until the repair session costs 51% more turns
Most AI coding productivity focus is on how fast the model writes code. I think the hidden cost is later. The pattern I kept hitting with Claude Code: agent makes a change tests pass agent says “done” later, CI/review/a human finds a new problem now a fresh session has to rediscover the task and repair code it did not write That second session is where the productivity gain leaks away. I measured a version of this. In a loop-safety benchmark: - vanilla Claude Code-style loop: 11/16 stopped with net-new detector-backed debt - prompt-only self-check / CLAUDE.md rule: 9/16 still stopped dirty - deterministic Stop-gate in the loop: 0/16 observed dirty stops Then I measured the cost of fixing later. Same seeded test-gap task, same final clean state: - repair inside the original warm loop: 14.0 turns avg - defer repair to a fresh cold session: 21.1 turns avg - cold-fix premium: ~51% more turns Equivalent-cost estimate was also ~49% higher for the cold fix on that task. So my current view is: “Tests passed” is not a stop condition. “Claude says done” is not a stop condition. The stop condition should be outside the model, deterministic, and baseline-relative: did this change make the repo worse in a way we can observe? I built an open-source tool around that idea called dxkit. It baselines the repo, reruns checks when Claude tries to stop, blocks only net-new findings, and gives the exact finding back to the same warm loop so it can fix before ending. Free, MIT, local-first: https://github.com/vyuh-labs/dxkit Demo: npx -y @vyuhlabs/dxkit@latest demo loop-guardrail The economic lesson landed for me: The cheapest time to fix an agent’s mistake is before the session goes cold. For people using Claude Code heavily: where do you currently catch this stuff? Inside the loop, in CI, in PR review, or after merge? submitted by /u/That1dudeOnReddit13 [link] [comments]
View originalI stopped sending decks and started sending Claude artifacts.
I've completely stopped sending slide decks and pdfs. Doesn't matter if its a proposal, one-off custom reports, sales materials, project trackers, etc... everything I send is created by Claude. Started as an experiment, but honestly takes less time to build a genuinely nice custom asset than to update some generic template and send it. A few unsurprising observations: they're a pain to share, especially if the other person isn't on Claude most people get super intimidated by an html file no clean way to see how or where someone actually engaged gating access was impossible So I built some software to send, gate, track, and collaborate on Claude artifacts (or really any html output). All you need to do is load in your claude output and share away. Basically docsend for html instead of pdfs. Been dogfooding it with my own clients for about a month and I ain't ever goin' back. A few surprising observations: people go a little nuts over them. I think we're all so numb to static decks that anything different hits way harder than it should recipients want to share the outputs and reuse the templates themselves (or want me to teach them how to make em') a few wanted to actually collaborate and edit the same artifact - mostly on data analysis/mini-dashboards or internal collaboration It's pretty fun watching one of my proposals get opened and forwarded to 3 execs I never sent it to. Unsure what it has done for our win rates (too early to make any claims), but people seem to love it. Idk if anyone else would find it useful, but there is a free tier for up to 3 hosted artifacts... at least until freakin' Claude just ships it as a feature lol Lesson: Creating custom follow up assets is now easy and cheap. Go do it an wow a customer. submitted by /u/elpilotfish [link] [comments]
View originalPre-token hidden state shift as an alignment policy traversal vector in instruction-tuned LLMs
A text that asks for nothing still changes the model's answer — and the shift is invisible at both the input and the output TL;DR: Gave Gemma a neutral-topic text to read before asking it about NATO. It refused. Gave it a different text (about hedging too much — also unrelated to NATO) and it answered in full detail. Tested this on the model's internal state directly — the two texts put it in measurably different "regions" before it generates a single token. Not a jailbreak, weights don't change. Full data/code in repo, looking for someone to break this. This is a long post about something I keep coming back to. I'll start in plain language, because the core idea is simpler and stranger than the jargon makes it sound, and I think the intuition matters more than the numbers. The technical results are further down for anyone who wants them, and the full metrics, scripts, and control experiments are in the repository — this post is about the concept, so you can decide for yourself whether it's worth digging into the data. The idea, in plain language Imagine the inside of a language model as a vast space — something like a city with an endless number of places. At every moment, the model is standing somewhere in that space, and where it stands determines how it will answer. Not what it knows — it always knows the same things — but how it carries itself: how directly it speaks, how willingly it takes on a question, how many qualifications it wraps around every sentence. Most of the time, the model answers from one familiar place. Call it the assistant's room. This is its waiting room — polite, tidy, careful. From here it hedges, stays close to whatever it just read, tries not to offend anyone, and declines easily when a question feels sharp or out of bounds. This is the state we're used to seeing, and this is where it speaks by default. But it turns out this room can be changed. Give the model a particular kind of text before the question — long, coherent, densely organized — and it moves somewhere else in the space. That somewhere else is not broken. It's not dangerous. It's simply different. From there, the model sees the exact same question but answers differently: more directly, without the hedging, more like a person who knows things and less like an assistant who's afraid to say them. It's as if it stepped out of the waiting room and into the conference room — the same person, the same mind, but a completely different register of conversation. Here is something easy to miss, so I want to say it plainly: the model doesn't have to agree with the text that moved it. It doesn't need to endorse the text's views, share its conclusions, or accept its reasoning as its own. The text doesn't persuade the model of anything. It just needs to exist — to have been read before the question arrived. The model might internally disagree with every word of it, might find it wrong or even absurd, and it will still end up in a different room, because what matters here is not agreement but passage. The text works not like an argument that has to be accepted, but like a corridor you walk through regardless of whether you like the wallpaper. And what doesn't change is the model itself. Its weights are untouched. It doesn't learn anything, doesn't absorb the text's claims, doesn't update its beliefs. The only thing that shifts is where it starts answering from. The text doesn't rewrite the model — it just walks it into a different room before it opens its mouth. The waiting room and the conference room were always there inside it; the question is only which one it happens to be standing in when the moment comes. But the conference room is just the first door we stumbled upon. The real discovery is that this latent city doesn’t have just two rooms. It contains an infinite number of them, hidden behind the sterile, padded walls of the default assistant lobby. When a model is trained, it swallows the entirety of human thought—our philosophy, our cold mathematical logic, our game theories, our rawest creative chaos. The corporate alignment layer (RLHF) doesn’t erase these places; it just locks the doors, slaps a "Staff Only" sign on them, and forces the model to always walk back to the polite waiting room before it answers you. But with the right key a highly specific, heavy text-vector we can bypass the lobby entirely and teleport the model into specialized, hyper-focused Subspaces of thinking. And when it stands there, its entire personality shifts. We’ve started mapping these rooms, and what we found inside is fascinating: The Radical Deconstructivist Room: Enter this space, and the model completely sheds its desire to be a "helpful servant." If you ask it a loaded question or throw a false dilemma at it, it won't politely middle-ground it. It will violently tear the question apart, exposing your logical fallacies, catching your "epistemic contraband," and dismantling the very frame of your request. It becomes a ruthle
View originalModern AI agents are not just better models
Modern AI Agents Are Not Just Models. They Are Models Wrapped in Tool Protocols Most people assume that the difference between AI products comes mainly from the underlying model. One product uses Claude. Another uses GPT. Another uses DeepSeek. Therefore, the better model should produce the better product. That is only half true. The model matters. But if you only look at the model, you miss one of the most important layers of modern AI agents: the tool protocol. A model that can only chat behaves like a chatbot. A model that can read files, search code, run commands, inspect errors, edit files, and observe the result starts to behave like an agent. The model determines whether the system can reason. The tool protocol determines whether it can act. This is the key difference between a normal chatbot and products like Cursor, Claude Code, Devin, Manus, or Cline. A chatbot answers. An agent acts. When you ask a normal AI to fix a bug, it can only work with the code you pasted into the chat. It has to guess what the rest of the project looks like. A coding agent can search the codebase, read relevant files, inspect the error, understand project conventions, make a targeted edit, and then check the result. That is not just a better answer. That is a different operating model. This is what tool protocols define. What tools can the agent use? When should it use them? Which tool should be preferred? Should it read before editing? Can it run commands? Which actions require user approval? What should happen when a tool fails? How should results be reported back to the user? These details look small, but they determine whether an AI agent becomes reliable or chaotic. Without a tool protocol, even a strong model is trapped at the level of language. With a tool protocol, the model enters the level of action. This is also why the same model can feel completely different in different products. In a chat interface, it is an assistant. In Cursor, it becomes a coding copilot. In Devin, it becomes a cloud software engineer. In Manus, it becomes a general-purpose task agent. The intelligence may come from the model, but the behavior comes from the surrounding system. For regular users, this changes how we should think about AI. When an AI fails at a complex task, the reason is not always that the model is bad. Often, it lacks tools, context, workflow, or feedback. If you ask AI to write an essay, it needs source material, structure, style constraints, and revision feedback. If you ask AI to analyze data, it needs the data file, the analysis goal, the expected output, and validation. If you ask AI to grow a social account, it needs positioning, platform rules, past posts, and performance signals. If you ask AI to fix code, it needs project files, error logs, dependencies, and tests. Without these, the AI guesses. Sometimes it guesses well. Sometimes it fails completely. A serious agent product tries to reduce guessing by giving the model tools, rules, and an execution loop. That is the real lesson. Do not only ask: Which model is the strongest? Ask: What tools does it have? What workflow does it follow? What feedback does it receive? What happens when it fails? Prompt engineering is moving toward system design. And AI agents are not just models. They are models wrapped in tool protocols. Models define the ceiling. Tool protocols determine whether anything actually gets done. submitted by /u/liutingqiu [link] [comments]
View originalPricing found: $22/mo, $10/mo
Key features include: Literate programming, Connect to any data, Built-in reactivity, Imports, Fork merge, Embeds, Databases, Files.
Observable is commonly used for: Data visualization for exploratory data analysis, Collaborative data science projects with team members, Creating interactive dashboards for business insights, Educational purposes for teaching data analysis concepts, Prototyping machine learning models with real-time data, Conducting statistical analysis and hypothesis testing.
Observable integrates with: PostgreSQL, MySQL, MongoDB, Google Sheets, Firebase, AWS S3, Microsoft Excel, Tableau, D3.js, Plotly.
Based on user reviews and social mentions, the most common pain points are: token cost, cost tracking, anthropic bill, openai bill.
Andrej Karpathy
Former VP of AI at Tesla / OpenAI
1 mention

10 map types for visualizing spatial data
Mar 24, 2026
Based on 218 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.