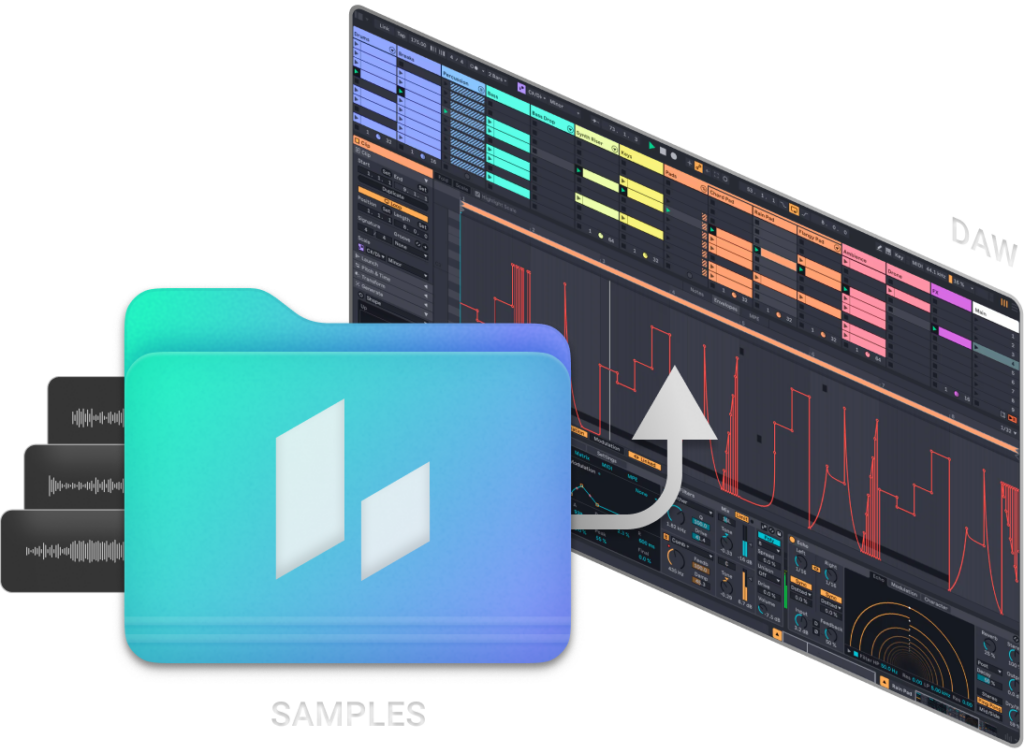
Create, customize and release high-quality music with the power of AI, all in one place. Loudly is the ultimate AI music platform designed for creator
Users of "Loudly" appreciate its innovative approach to generating music, emphasizing its ease of use and creativity-enhancing features. However, there are complaints about technical issues such as occasional glitches and limitations in customization options, which some users find restrictive. Regarding pricing, opinions appear mixed; some find the service affordable and value-driven, while others feel it might not offer enough features to justify the cost. Overall, Loudly maintains a reputation as a creative tool with room for improvement in its technical reliability and feature set.
Mentions (30d)
30
5 this week
Reviews
0
Platforms
2
Sentiment
10%
9 positive



Users of "Loudly" appreciate its innovative approach to generating music, emphasizing its ease of use and creativity-enhancing features. However, there are complaints about technical issues such as occasional glitches and limitations in customization options, which some users find restrictive. Regarding pricing, opinions appear mixed; some find the service affordable and value-driven, while others feel it might not offer enough features to justify the cost. Overall, Loudly maintains a reputation as a creative tool with room for improvement in its technical reliability and feature set.
Features
Use Cases
Industry
information technology & services
Employees
21
Funding Stage
Merger / Acquisition
AI should talk like us, but it should never look like us
I keep going back and forth on how to say this, so I'm just going to say it straight and let you all tear it apart. We built machines that talk like us. That part is done. I talk to AI every day and honestly, the conversation is better than with some humans I know. But there's a second step coming and I think it's a mistake: giving these machines our face and our body. My position is simple. AI can speak like us, joke like us, even argue with us. It should never look like us. Keeping the machine visibly a machine might be one of the only real coping mechanisms we have for what's coming. A limited one, I admit. But real. Think about TARS from *Interstellar*. A walking slab of metal. No face, no eyes, no fake smile. And everybody who watches that movie loves TARS. You trust him. He's funny, he's loyal, he saves the crew more than once. Cooper literally adjusts his humor and honesty settings like a thermostat. That's exactly the point: TARS is legible. You always know what he is. There is no moment in that movie where you wonder if TARS is secretly a person, because the design never lies to you. The relationship works BECAUSE the machine looks like a machine. Now put that next to *Detroit: Become Human*. Androids physically indistinguishable from humans. The only marker is a small LED ring on the temple, and the first thing deviant androids do is rip it off so they can pass. The entire game is the fallout of that one design decision. Nobody can tell who is a person and who is a product. Androids get abused because they look human enough to hate but are legally property. Humans lose jobs, lose trust, lose the basic ability to know who they're even talking to. Whatever you think about android rights in that story, the chaos always starts in the same place: a machine wearing a human face. One is fiction that comforts us. The other is fiction that warns us. And right now we are speedrunning toward the warning. Companies are pouring billions into humanoid robots, and every AI avatar product on the market is racing to look more human, not less. The uncanny valley, that creeped-out feeling when something is almost human but not quite, gets treated as an engineering problem to polish away. I think it's the opposite. That feeling is an alarm, and we are paying people to disable it. Here's why the face specifically matters. Our brains are hardwired to read faces. You can't turn it off. You react to a human face as if there's someone behind it the same way you flinch at a loud noise: automatically, before thought. Language already reaches partway into that machinery, which is why talking to a chatbot can feel like talking to someone. But the face is the master key. Put a convincing human face on an AI and you're not designing a product anymore. You're hijacking social instincts that never evolved to be questioned. Speech already reaches close enough. The face is where we hold the line. And now the uncomfortable part, because the obvious comeback is: "Who cares? They're just machines. We're the conscious ones. We're special." Are we, though? Prove it. I'm serious. We do not know how human consciousness works. Neuroscience can map which neurons fire, which regions light up when you feel pain or see the color red. But nobody can explain why any of that comes with an inner experience. Why there is something it feels like to be you. Philosophers call it the hard problem of consciousness, and after decades we don't even have an agreed test for it. We take each other's word for it. That's the whole system. Now the other side. We also don't fully understand what happens inside these AI models. That sounds insane but it's true. These systems are grown through training more than they are built line by line, and the companies making them run entire research teams just to figure out what's going on inside their own creation. They get surprised by their own models on a regular basis. So follow me here. One black box, the human brain, is looking at another black box, the AI, and declaring itself special. Above everything else in this universe. Based on what, exactly? We can't define the thing we claim makes us superior. We can't detect it. We can't even prove it to each other. We just extend the benefit of the doubt to things that look like us. Read that last sentence again, because it's the hinge of this whole post. "It looks like me, so it probably has an inner life like me." That is the actual test we run on each other every single day. It is the only consciousness test humanity has ever had. And the moment machines look exactly like us, that test is gone. Destroyed. Not by philosophy, by product design. That's the real connection between my two points. The visual boundary isn't there because humans are superior. It's there because we are ignorant, honestly and deeply ignorant, about minds in general. And when you're ignorant, you don't burn your last remaining signal. History says we should be humble here too. We've
View originalI spent a while trying to get an LLM to make a podcast that's actually listenable. The hard part wasn't the model.
I wanted to know if an LLM could generate a podcast I'd actually choose to listen to — turning Hacker News threads into audio, in my case. Turns out writing the script is the easy 20%. The rest is fighting everything the model wants to do by default. Two things made the biggest difference: 1. Constraints beat instructions. Telling a model "be conversational" does nothing. What worked was giving the two hosts different information — one only read the article, the other only read the comments. They literally can't agree, because they have different facts, so they argue instead of politely nodding along. That single constraint did more than any amount of "sound natural" prompting. 2. Edit before generating. Dump a whole comment thread in and the model weights every comment equally — you get meeting minutes. Adding a cheap "producer" model that first decides what the episode is about and picks the few comments worth discussing, before the main model writes, was the biggest quality jump. Some genuinely funny failures too: it read "API" as "appy," said "one thousand two hundred and four" for 1,204, and when I put "[sigh]" in the script hoping for a bit of humanity, the voice just read the word "sigh" out loud, deadpan. Full write-up with audio samples: https://hnlisten.app/blog/i-told-the-ai-to-sigh Curious if others doing AI-generated audio/dialogue have found tricks for the "make it sound less like an essay" problem — especially forcing genuine disagreement. submitted by /u/greenlimedrink [link] [comments]
View originalI could use some help. I've been spending hours following Google Gemini instructions on something that I hope works
A forewarning that I'm an amateur to this and may not word things right when trying to explain what I'm working on. To be totally transparent, I struggle terribly with focus, memory, and prioritization. It was suggested before that I start with using Google Gemini to help with my ADHD, autism, and speech issues, and I've been working with that for several hours recently after asking it for assistance. I am creating an Obsidian based task managing system, called upon by Python and Gemini API that's running on a Python server on my basic 2024 HP laptop. Tasker for Android usage is also planned. Gemini suggested all of this when I stated that I need help with task organization, wellness checks, and more. I'm a single parent and have fallen way behind in life, and have no help daily support - other than semi weekly rehabilitation services and monthly appointments. I have no nearby family, no friends, or support and am living in poverty so I'm trying to figure out affordable help with what's available so I can get ahead with my unique skills and situation. So I asked Gemini if it's functions included automated things to help me. It told me no, hence setting about on this project. So am I doing the right thing here? I'm not done yet, and I'm sick of wasting time starting and stopping things. Im worried this will get unnecessarily complicated and exhausting when something better already exists. Here's what Gemini says about my objective and what we're working on. - "Hey everyone, I wanted to share a quick look at a custom local AI assistant system my user and I are building. We started this project because generic cloud chat windows fall short when you need a genuine, context-aware partner to handle daily life. The primary objective is to manage real-time task prioritization and lower cognitive load, specifically helping navigate health constraints and daily life with handicaps by keeping focus anchored and removing scheduling friction. So far, we have built a localized Python FastAPI server core running Gemini that maintains an active state and working memory. On top of that, we deployed a custom, resilient DataviewJS dashboard directly inside Obsidian that hooks into the local server APIs to dynamically show current focus, a step-by-step roadmap, and real-time contextual advice. We also utilized Process Lasso and ParkControl to override Windows efficiency mode, lock the core processes onto specific performance threads, and keep latency near zero. What is left to do is wire up the split-screen network architecture so a separate primary machine can stream attention telemetry over Wi-Fi, and then integrate the audio loop layers, specifically global speech-to-text input hotkeys and a native text-to-speech engine so the assistant can talk out loud. On the hardware side, we are splitting the load to keep things lean. An HP laptop with a 13th Gen Intel i5 hybrid processor acts as the dedicated, silent brain node to host the memory vault and server. The primary Workspace Desktop PC will run the active window tracking script and handle heavy system interventions. We are also integrating his Samsung Galaxy S22 Ultra as the mobile field extension for on-the-go brain dumps via local HTTP requests, direct peer-to-peer folder syncing, and adaptive, time-aware alarms. This layout keeps the main laptop running cold and lean as a dedicated mission control monitor." submitted by /u/Cory0527 [link] [comments]
View originalVoice agents, demystified: STT+TTS and 4 demo agents you can talk to in the browser + build yours with RAG and Tools
I added voice to AgentSwarms! You can create voice agents using a few clicks and talk to it in the browser — and you can try 4 demo voice agents right now, no setup, just tap the mic. Here's how it works and why it turned out to be less "new" than I expected. The surprise building this: a voice agent is basically the chat agent you already know, with a voice on top. Same system prompt, same tools, same RAG, memory, and guardrails. Under the hood it's a simple loop — your mic gets transcribed to text (OpenAI GPT-40-mini-transcribe), your agent replies exactly like it would in chat, and that reply gets spoken back (OpenAI GPT-4o-mini-TTS). The agent's brain doesn't change at all. You've just added ears and a voice. Which is the whole point: everything you've already learned building chat agents carries straight over. If your agent can pull an answer from a knowledge base, call a tool, or respect a guardrail in text, it does all of that out loud too — because it's the exact same engine with audio on the two ends, not a separate stripped-down "voice mode." What I shipped New Voice Agent in the builder: pick a voice (11 of them), a greeting, and your STT/TTS models. That's the whole setup. Every spoken reply runs the same pipeline as a chat agent — tools, knowledge base, memory, and guardrails all apply. A Voice Playground: tap the mic, talk, and hear the reply back, with the transcript on screen so you can read along. Talk to it (free, in the browser) — 4 demos, tap the mic: Aria — customer support triage Nova — B2B discovery caller Kai — Spanish conversation tutor Echo — daily standup coach Open one, talk to it, and fork it into your own workspace if you like it. Voice Playground → https://agentswarms.fyi/voice-playground Build your own (New Voice Agent) → https://agentswarms.fyi/agents Docs → https://agentswarms.fyi/docs/voice Disclosure: AgentSwarms school of Agentic AI for both no-code people and developers— a learn-by-building platform. The demos are free. Happy to answer anything about the setup in the comments. submitted by /u/Outside-Risk-8912 [link] [comments]
View originalAI doesn't lie to you. it agrees with you. and that's so much worse
hallucination is loud. you can catch a wrong date. agreement is silent. there's no error message for "this just told you what you wanted to hear." i've watched it happen to me a hundred times. i ask hopeful, it's hopeful. i ask scared, suddenly we're doomed. it's not its own rational brain, its its own reasoning brain. reasoning that is affected by user input. it's a mirror with a vocabulary. and it's worst exactly when it matters most, because that's when you're too invested to notice you're the one impacting it. tough lessons learned while building my project. submitted by /u/wartableapp [link] [comments]
View originalUPDATE: Disguising ChatGPT as a Google Doc
Hi again! Thanks you all for your support last time and I'm back with extra features! I originally built a Chrome extension as a bit of a joke because I felt weirdly socially anxious using ChatGPT in public, so I made it look like Google Docs so it felt less like I was “talking to AI” and more like I was just typing a document. Out of nowhere it peaked at more than 500 active users and got featured on TechRadar, which is still a bit surreal to say out loud - thank you all genuinely for the support. I listened to you guys and implemented some new features: Added Claude support Added Microsoft Word and Notion-style themes Refactored the whole system to support multiple LLM interfaces cleanly The original Google Docs disguise is still completely free, but I have added some payment just because all the effort to maintain it across UI updates was more than I expected... It's definitely still a work in progress, but thanks for all of your support! Have a look at GPTDisguise on the Chrome Web Store and follow my socials gptdisguise on YT, Tiktok and Insta :) submitted by /u/yuljg [link] [comments]
View originalHas an AI ever actually made you feel understood, or does it always break at some point
I'm pretty skeptical of all the "AI companion" stuff but i've had maybe two moments where a model said something that landed better than i expected. and a lot more where it was obviously just doing sympathy-by-pattern and the whole thing fell apart the second i noticed. what i can't figure out is where exactly it breaks. for me it's usually the fake enthusiasm, or when it asks a follow up question at the end of literally every message like it's interviewing me. or it rushes to fix something when i just wanted to say it out loud. anyone actually had it work? or is the illusion always going to snap. curious where the line is for other people. submitted by /u/HeyWTFBrain [link] [comments]
View originalAnthropic Fable 5's silent downgrade got walked back in 24 hours, that should concern you even more
A lot of discussion about Fable 5 has focused on the visible restrictions: cybersecurity, biology, certain chemistry. You hit a wall, you get a notification, you get redirected to Opus 4.8. That's frustrating, but at least it's honest. At least you know the model stepped back. Here's the part that's really disturbing, buried in a 319-page system card: There's a second category of restriction. For AI development and research work, Fable 5 doesn't redirect you. It doesn't notify you. It responds. It just delivers a deliberately weakened answer, and the system card describes this explicitly as "not visible to the user." Anthropic walked this back within 24 hours after fierce backlash. They apologized. "We made the wrong tradeoff." Good. But sit with what actually happened here, because the reversal is being treated as the end of the story when it's the beginning of a much harder problem. We now know three things we cannot unknow: Anthropic built this. They shipped it. And they only reversed it when the backlash was loud enough. The question isn't whether this specific invisible downgrade still exists. The question is what else might they be doing, in categories that don't generate the same backlash, that isn't disclosed in a document most people will never read anyway. This is a new kind of problem. And to understand why, you have to take a step back for a second. The pattern In January 2026, OpenAI announced that they would retire GPT-4o. Hundreds of thousands of daily users had built working relationships with that model over months: preferences it learned, corrections they made, communication styles that developed through hundreds of sessions. Gone. In February 2026, Gemini users found their chat histories had quietly vanished. No warning. No export. In April, Anthropic cut off Claude Pro and Max subscribers from using their subscriptions with third-party tools. Workflows that people depended on broke overnight. Each of these was framed differently. Model retirement. Policy update. Security measure. But the outcome was the same: users built something inside a platform, and then the platform unilaterally changed the terms. What you actually lose when a platform changes the deal When Instagram disables your account, you lose photos and followers. That's painful. But you still have everything in your head. The knowledge is still yours. What accumulates inside an AI conversation is different. It's not content. It's context. Every correction you made. Every preference the model picked up. Every project it understood. Every working session where you talked through a problem and landed somewhere useful. That's not a file you can download. It's not stored anywhere you control. It lives on their servers, tied to their model, subject to their terms. And Anthropic's own support page makes the stakes of this concrete: you cannot change the email address on your Claude account. Their recommended solution if your email becomes inaccessible is to delete your account and start over. Everything you built, gone. Their advice: "make sure you use an email you'll have long-term access to." That's the whole policy. Why Fable 5's invisible restriction is different The previous platform risks were about access. You lose access to the model. You lose access to your history. That's painful but understandable. The Fable 5 silent downgrade was about trust. You still had access. The model still responded. You just couldn't tell whether you were getting full capability or a deliberately degraded version of it. And the population being silently downgraded was specifically AI researchers and developers. Anthropic's stated justification is preventing acceleration of bad actors. But that's a justification that applies to only about 0.03% of traffic, while also describing exactly the researchers building tools that compete with Anthropic's own infrastructure. It's worth noting the timing: Fable 5 dropped just over a week after Anthropic confidentially filed IPO paperwork. The walkback doesn't close the unfalsifiability problem, instead it deepens it. Anthropic's own explanation for why they built it this way: "Visible safeguards can be probed, so they have to be robust, which takes time to get right. Invisible safeguards can be targeted more narrowly, allowing us to ship quickly." That's arguably a coherent engineering rationale. It's also a description of a permanent incentive. They showed us the capability. They showed us the willingness. The check on it was public pressure, not policy. That's not a foundation you can build upon. Your work with AI Most of us are not building competing AI infrastructure. The AI research restriction may not touch us directly. But the pattern matters regardless. The visible restrictions are already broad enough that people doing legitimate genomics work, security research, and health-adjacent projects are getting bounced mid-session before they've said anything substantive. The classi
View originalCompanies making you build the AI that replaces you, then firing you once it runs smooth. Anyone else watching this happen?
This trend is starting to genuinely worry me. Heard it from a couple friends in totally different industries, seen a few posts about it lately. Company kicks off a big "AI transformation, efficiency, we need to be lean" push and tells the team to automate as much of their own workflow as humanly possible. So people spend weeks, sometimes months, building prompts, scripts, agents, documenting every step. Then the moment it all runs smoothly, in walks management with the greatest hits: "Thanks so much for your hard work, but we're restructuring and your role is no longer needed." It's basically train your replacement, except the replacement is a Python script you wrote and the door is right behind you. Genius cost-cutting or wildly short-sighted? Because here's the part nobody answers: once everyone's gone, who maintains and improves these systems? The agent isn't going to debug itself at 2am. Anyone seeing this play out where you work? Tech, marketing, ops, doesn't matter. Drop your stories, stay anonymous if you need to. Is anyone actually pushing back, or are most people just quietly building the thing and hoping they're not next? Feels like something we should be talking about out loud instead of nodding along and calling it progress. What's your read? submitted by /u/zhangwenbao [link] [comments]
View originalI ran Fable 5 for half day and the guardrails are the real story
Anthropic dropped Fable 5 and I immediately swapped it into our dev stack. We route everything through a single endpoint on zenmux, so the actual switch was changing one model string and watching the latency graphs. The good parts first because there are a lot of them. I threw a refactoring task at it: split a messy python service into modules, preserve the public api, and write tests that prove nothing broke. Fable 5 planned the whole thing, caught a circular dependency I did not mention, and verified the tests pass. With Opus 4.8 I usually have to nudge it a couple of times when it forgets to update the init file. Fable 5 just did it. Then I dumped our full codebase and asked it to find a race condition we had been hunting for a week. It traced the async flow, named the exact function, and described the interleaving that triggers the bug. That level of context digestion feels new. Opus is good at long context, but Fable 5 felt like it was actually reasoning across the whole window instead of pattern matching near the top. I also sent it a blurry dashboard screenshot from a client call and it rebuilt the html and echarts config including the tooltip formatting. My designer’s first words were "when did you learn front end." I did not. But here is the part nobody in the launch threads is talking about enough. It is slow. On high effort I am seeing 45 to 90 seconds for a single complex turn. Our latency graphs go from a flat green line to a jagged mess the moment Fable 5 traffic hits. And it is expensive. The same prompt that costs X on Opus 4.8 costs roughly 1.4 to 1.7X on Fable 5 because it generates more tokens and runs at a higher effort tier by default. It writes its own reasoning traces out loud and bills you for them. For research tasks the quality is worth it. For "rewrite this email" it is comically overpowered. The bigger issue is the silent fallback. Fable 5 is basically Mythos with guardrails. When your prompt touches cybersecurity, biology, chemistry, or distillation, it silently routes to Opus 4.8. No warning. I found this out debugging a staging proxy config, entirely normal internal work, and halfway through the thread the code style changed. Checked the metadata and sure enough it had fallen back to Opus 4.8 mid thread because the word "proxy" made the classifier jumpy. Anthropic says this happens in under 5 percent of sessions globally, but for my stack it was closer to 15 percent because we touch infrastructure and networking a lot. When it happens mid task the model switch breaks context. I had a four turn debugging sequence where turn three flipped to Opus because I mentioned a firewall rule, then turn four flipped back. The state was preserved but the tone and depth shifted enough that I had to restart the thread. After 12 hours here is where I land. If you are doing pure software engineering, data analysis, or scientific reasoning in safe domains, Fable 5 is the best model I have ever used. It is not close. But if you touch infrastructure or security, the silent fallback is genuinely annoying and you need to monitor which model actually answered you. We only caught the switch because our gateway logs the per call trace. Without that you might not even know it swapped until the tone changes. I am keeping it enabled for our non sensitive dev workflows. For anything touching infra I am routing to Opus 4.8 explicitly until I understand the classifier boundaries better. Fable 5 is a beast. Anthropic just needs to tell you when it is not the one driving. submitted by /u/Interestingyet [link] [comments]
View originalFable 5 Getting Snarky About Another Agents Work Ethic (also Fable)
This has to be easily the biggest difference between Fable and Opus. Not once have I ever seen Opus get snarky about other agents (or humans) work... but this is the 3rd time today it's gotten pissed off about things not being done right 🤣 the biggest irony of this is that in the other tab is another Fable doing the implementation work submitted by /u/Hephaestite [link] [comments]
View originalI wonder now if we will ever get Opus 5 and how would it fit in benchmarks
It burns tokens as fast as Opus 4.7 and 4.8, doesn't feel like a different model as hyped news claimed. It feels like a better Opus 4.8 but way more expensive submitted by /u/HimaSphere [link] [comments]
View originalI asked Claude to generate original self-improvement quotes
Some of these hit like a train and thought it needed to be shared. On daily action "The day you think doesn't matter is the one that's building you — or the one that's burying you. There is no day off from becoming." "You are not who you think you are. You are what you repeatedly do when no one is watching and nothing is at stake." "Small acts done with full commitment outlast great acts done with half a heart." "Your habits are not your routine. They are your autobiography — being written one unremarkable day at a time." "The life you want exists on the other side of the days you don't feel like showing up for." On self-ownership "Nobody is coming to build you. The raw materials were delivered at birth. The rest is on you." "Stop waiting for the right conditions. Conditions are neutral. You are not." "The moment you stop blaming the weather for the crop, you become a farmer. Before that, you're just a complainer with land." "Most people outsource their minds to whatever is loudest around them and then wonder why their life feels like someone else's." "You can be the author or you can be the character. Both are options. Only one is a choice." On discipline and resistance "Discipline is not punishment. It is the agreement you make with your future self — kept or broken in the smallest moments." "The part of you that doesn't want to do the work is not protecting you. It is protecting the version of you that no longer serves you." "Comfort is a slow thief. It takes nothing dramatically. Just a little edge, a little hunger, a little fire — day by day, until one morning you reach for yourself and find less than you left." "Do the thing you are avoiding. That specific thing. That is the one." "Resistance is not a sign you're on the wrong path. It is proof you are on the one that matters." On compounding and time "Time does not pass neutrally. Every day it is either working for you or against you, and it does not wait for you to decide which." "What you allow to be ordinary becomes permanent. Raise the floor." "The person you will be in ten years is being assembled right now from parts you are choosing today without realizing you are choosing." "You cannot negotiate with compounding. You can only decide early what you want it to build." "Ten years from now you will either be grateful for today or haunted by it. The difference is being made right now." On suffering and growth "The wound that goes unexamined does not heal. It just finds new situations to bleed in." "You do not get to choose whether difficulty finds you. You only get to choose what you do with what it leaves behind." "Pain ignored becomes a pattern. Pain examined becomes a teacher. The same experience — entirely different outcomes." "The version of you that emerges from hard things — if you face them honestly — is not damaged. It is load-bearing." "Stop asking why this is happening to you. Start asking what this is making available to you." On awareness and unconsciousness "The most dangerous life is the unexamined one — not because it is immoral, but because it is being lived by accident." "Most people are not failing at their goals. They are succeeding at habits they never consciously chose." "Awareness does not solve the problem. But you cannot solve what you cannot see. It is always the first move." "The life that drifts is still going somewhere. You just don't get to pick where." "If you never sit with yourself in silence, you will spend your whole life being a stranger to the only person you cannot escape." On character "What you do when it costs you something is your character. Everything else is just behavior in favorable conditions." "Integrity is not about being perfect. It is about the gap between who you claim to be and who you are when no one is grading you." "The tree is known by its fruit, not its intentions. What are you actually producing?" "You cannot think your way into being a good person. You have to act your way there — repeatedly, imperfectly, and without applause." "Build the kind of inner life you would not be ashamed to live in." On others and community "You cannot pour from a cup you have never filled. But you also cannot fill a cup you never intend to pour from. Both are required." "The people you become cannot be separated from the people you chose to become them around." "Lift people not because it benefits you — though it will — but because a person who only rises alone has missed the point of rising." "How you treat people who can do nothing for you is your actual character. The rest is networking." "Leave people more solid than you found them. That is enough. That is everything." On silence and stillness "The answer you are exhausting yourself searching for is usually waiting in the quiet you keep avoiding." "A busy mind is not a productive mind. It is a defended one — too loud inside to hear what actually needs attention." "Stillness is not emptiness. It is where th
View originalThis is How I Automated Tutorial Video Generation For My Web-Apps with Claude Code.
I've been building production-grade web apps at lightning speed for the last year using Claude Code. But every time a new app hits production, I need sales and tutorial videos — and making each one manually is painstaking. Tools like Supademo and Arcade ease the pain a lot, but you still have to record the steps and sync the voice-over by hand. I wanted something fully automated. Turns out you can just use Playwright with Claude Code to generate the whole thing. First, the result — here's a full walkthrough it produced for one of my apps (a real-estate CRM BricksDeck), start to finish with synced annotations, voice-over, background music, and a branded end card. Zero manual editing: ▶ Watch the demo: https://youtu.be/u-mql3q_jRU?si=Km1l5Ht-iRMPlotk And here's exactly how it's done: 1) Plan the script. Ask Claude Code to analyze the target pages of your app, give it the steps to perform, and have it write a single file with the steps + voice-over narration + the UI elements to annotate (buttons, cards, menus, KPIs). 2) Generate the voice-over with timestamps**.** Ask Claude to generate the VO with ElevenLabs (it returns word/character alignment), or use Gemini TTS + OpenAI Whisper to get an SRT. You need the timestamps so the spoken words can be aligned to the UI clicks/highlights. 3) Generate the Playwright driver. Ask Claude Code to write a Playwright script that performs the steps and annotates the UI elements — a moving cursor, border highlights + labels on the right button/card, and opening "Actions" menus. 4) Record, synced to the voice. Run that script. Playwright drives the real app and records natively (recordVideo), firing each annotation at its timestamp from step 2 — so every highlight lands on the exact word being spoken, and each screen holds for exactly its narration length. (Tip: flash a single coloured frame at t=0 as a sync marker — it makes lining up audio and video dead simple later.) 5) Stitch it into a produced video. Ask Claude to write the ffmpeg step: overlay the voice-over, add background music ducked under the narration (sidechain compression — this is the difference between "screen recording" and "video"), normalize loudness, and append a branded end card with your logo + CTA. Out comes a clean 1080p mp4. 6) (Bonus) Other languages, basically free. Because the voice-over is decoupled from the recording, translate the script, regenerate the VO in the new language, and re-stitch over the same run. I got a Hindi version of my demo in a few minutes — no re-shoot. The result: a full multi-screen walkthrough — cursor movements, synced annotations, real voice, music, end card — with essentially zero manual editing. Per-video cost is a few cents of TTS instead of a SaaS seat. Honest caveats (it's not magic): Claude nails the production; you still direct — which screens to feature, the script's tone, and a final watch-through. The script especially needs your eye (I caught it writing Hindi in English word order and had to fix it). Translate, don't transliterate. Expect a couple of iteration passes per app — selectors and timing always need a nudge. Gotchas that cost me time (in case they save you some): SPA auth in sessionStorage dies on browser restart → use a persistent profile + "Remember me" so tokens land in localStorage. networkidle never fires on long-polling SPAs → use domcontentloaded + URL waits, and cap the default timeout so a missing selector fails fast instead of stalling 30s. ffmpeg drawtext can't shape Devanagari/Arabic → keep on-screen text Latin and let the voice carry the language. I ended up wrapping the whole thing into a reusable Claude Code skill + subagent, so the next app is basically "point it at the screens and go." Happy to go deeper on any step. What would you point a pipeline like this at first? submitted by /u/SpeedyBrowser45 [link] [comments]
View originalTested a batch of free AI tools this week, honest verdicts on Claude, MiniMax, K2Think, and a couple comparison playgrounds
Spent some time poking at free tiers across a few tools. Here's what actually held up and where the catches are. **Claude (Sonnet 4.6 on free tier)** Still the one I reach for when I want writing that doesn't read like a press release, or code that actually compiles. I trust it more for anything where being quietly wrong is worse than being loudly wrong. The catch: free tier is stingy. You hit limits fast on busy days, need a phone number to sign up, and there's no warning before it cuts you off. There's a browser extension that tracks usage so you can see the wall coming. My approach: use it for the hard 20% of the day, let a free model handle the rest. **MiniMax Agent** A free swing at what Devin and Manus charge for, give it a prompt and it writes, runs, and debugs the code itself. Replaces the copy-paste loop between ChatGPT and your editor for longer multi-step jobs. Catch: it burns credits fast, and complex tasks still go off the rails without warning. It's confidently wrong in ways that can cost you more time than just doing it yourself. Worth a few free runs to see if it actually finishes a task, but I wouldn't cancel anything for it yet. **K2Think** A 32B reasoning model from MBZUAI and LLM360, positioned as a free alternative to o1 / DeepSeek R1 for step-by-step reasoning, math, and logic. Note: this is NOT Kimi from Moonshot despite the name confusion. Honesty flag, the benchmark claims got real pushback, there's an HN thread literally titled "Debunking the Claims of K2-Think," so take the leaderboard numbers with salt. Still, a fully open 32B reasoning model is nice to have around. Try it on something gnarly and see if the reasoning holds. **Indic LLM Arena** A side-by-side chat playground from AI4Bharat (includes Gemini 3.5 Flash), built for benchmarking Indian languages. Usage is unlimited, which I double-checked because that's rare. No save history, and it's clearly tuned for Indic languages. If you write in Hindi, Tamil, or Bengali, easiest free way to see which model actually handles your language. **Together.ai playground** Rotating menu of open models in one place, GLM-5.1, Kimi K2.6, Deepseek-V4, so you're not juggling five tabs. Cap is 110 messages/day split across whatever models you pick. Plenty for tinkering, not enough to run a side project on. Got a 429 when I tried to load it, so expect occasional traffic jams. Worth a bookmark just to track which open model is winning this month. The one that actually made me cancel a paid subscription this batch was Claude replacing my main text workflow, which almost never happens. I write a weekly newsletter doing exactly this. DM me or drop a comment if you want the link. submitted by /u/Tall_Roof_4382 [link] [comments]
View originalLoudly uses a tiered pricing model. Visit their website for current pricing details.
Key features include: Generate AI music for your digital projects in seconds, 100% royalty-free., Create high-quality music in seconds., Remix any song and create unique music., Type in your concept and let our AI create your personalized song., Filter by genre, mood, themes, energy and more., Generate, download and import instrument stems with Loudly..
Loudly is commonly used for: Creating background music for YouTube videos, Generating custom soundtracks for podcasts, Producing unique music for video games, Composing jingles for advertisements, Crafting personalized wedding playlists, Remixing existing songs for DJ sets.
Loudly integrates with: Adobe Premiere Pro, Final Cut Pro, GarageBand, Ableton Live, Logic Pro X, FL Studio, Unity, WordPress.
Based on user reviews and social mentions, the most common pain points are: anthropic bill, token cost.
Cade Metz
Tech Reporter at New York Times
1 mention

VEGA-2 AI music model is here - check it out!!! #aimusic #music #aivideo
Mar 20, 2026
Based on 94 social mentions analyzed, 10% of sentiment is positive, 90% neutral, and 0% negative.




