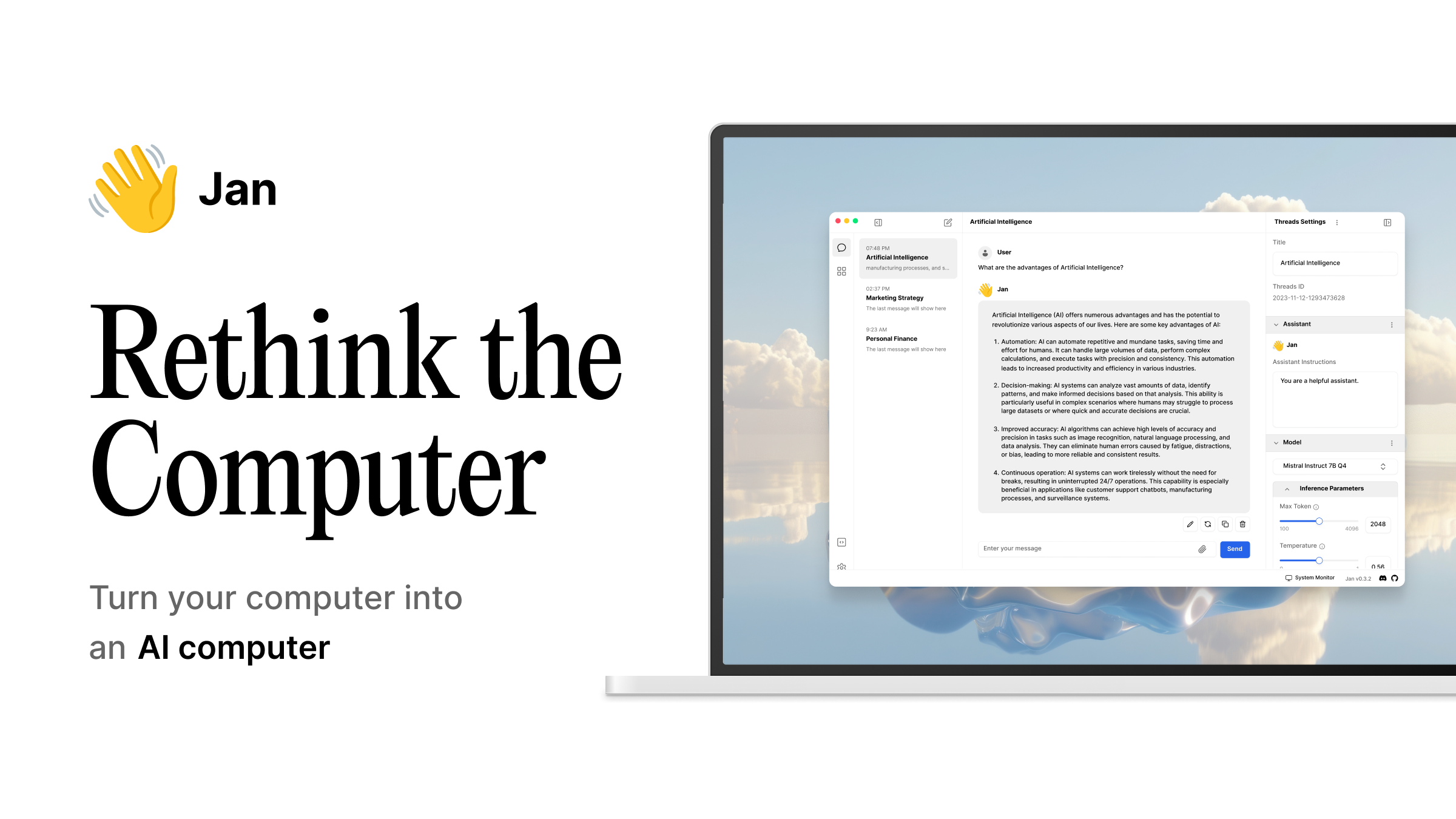
Jan is an open-source alternative to ChatGPT. Run open-source AI models locally or connect to cloud models like GPT, Claude and others.
The main strengths of "Jan" from the reviews and social mentions are not specifically clear due to the lack of relevant data. Key complaints are also not highlighted, as none of the mentions or reviews focus directly on "Jan." There is no sentiment or feedback regarding the pricing of "Jan," and the overall reputation is not discernable from the provided content. The information doesn't offer insights into user experiences with "Jan," leaving its evaluation incomplete.
Mentions (30d)
20
4 this week
Reviews
0
Platforms
5
GitHub Stars
41,416
2,651 forks
The main strengths of "Jan" from the reviews and social mentions are not specifically clear due to the lack of relevant data. Key complaints are also not highlighted, as none of the mentions or reviews focus directly on "Jan." There is no sentiment or feedback regarding the pricing of "Jan," and the overall reputation is not discernable from the provided content. The information doesn't offer insights into user experiences with "Jan," leaving its evaluation incomplete.
Features
Use Cases
1,506
GitHub followers
88
GitHub repos
41,416
GitHub stars
18
npm packages
23
HuggingFace models
Axios compromised on NPM – Malicious versions drop remote access trojan
View originalHow do i Generated images in a controlled way with gpt-image 2 ?
I've hit a workflow roadblock and I'm hoping someone who's already solved this can point me in the right direction. My current setup is: Google Flow for image generation GPT subscription for GPT-Image 2 access Additional API credits from third-party OpenAI-compatible providers What I'm trying to achieve is a workflow similar to Flow, but using GPT-Image 2 through API credits rather than buying another platform subscription. The challenge is that while Flow gives great control, I still spend a lot of time dealing with facial consistency issues across generations. GPT-Image 2 seems noticeably stronger in that area, so I'd like to build my image workflow around it. I've already tested several clients/interfaces: Chatbox LobeChat OpenRouter Chat TypingMind Cherry Studio Jan Most of them work well for chat, but I haven't found one that provides a strong image-generation workflow with: custom API endpoint support GPT-Image 2 access image-first UI prompt iteration/versioning multi-image generation and comparison I'm not necessarily looking for the best platform. I'm trying to understand whether a client that supports this workflow already exists, or if most people using GPT-Image 2 via API are building their own interface. For those generating images through API providers rather than platform subscriptions, what does your setup look like? submitted by /u/Drak-Shadow-005 [link] [comments]
View originalMom, I met someone...
https://preview.redd.it/b3onvxuzcd5h1.png?width=663&format=png&auto=webp&s=31f6e9e3596b5c2f79926246d1dd95706a17922b His name is Claude. submitted by /u/ExpensiveAnt1207 [link] [comments]
View originalClaude's referral traffic grew 386% in 4 months—but the more interesting story is what people are using it for (new research, 101K sites)
Our team just wrapped a study analyzing 101,574 websites across 250 countries from Jan 2025 to Apr 2026 to see how AI platforms send traffic. Claude is the standout, but not for the reason you'd expect. The numbers: Claude referral share grew 386% Jan-Apr 2026. ChatGPT grew 1.53% in the same window. March 2026 alone was a 2.6x jump—biggest single-month gain in Claude's history. Claude is still only 1.40% of total AI-referred traffic. ChatGPT dominates at 78.23%, then Perplexity (9.33%), Gemini (6.85%), Copilot (3.57%). The US runs ~2x ahead of the EU, ~3x ahead of the UK. Other regions hit the level the US reached in April 2025 about 10 months later. Outside our data: Claude mobile DAU hit 11.3M in early March (+183% YTD). 71% of orgs using genAI now rely on Anthropic (was 46% a year ago). The part that flipped our thinking: traffic share is the wrong metric to judge Claude on. People don't open Claude like Google—they open it to do work. Write, code, analyze, automate. That's also why Claude Code DAU doubled since January and business subs went 4x. So the real visibility question for businesses isn't "does Claude cite me?"—it's "can Claude use my data as part of a workflow?" That's where MCP and Skills come in. Booking, Tripadvisor, Spotify, Instacart all connected recently—they're playing a different game than brands optimizing for citations. Anyone actually building MCP integrations vs just tracking AI citations? What's working? submitted by /u/Kseniia_Seranking [link] [comments]
View originalAdd these words to your prompt for Claude to build live websites directly from chat
I built something that lets you generate sites from Claude by just adding "deploy to blitz.dev" to the end of your prompt. Works in Claude Cowork, Claude Cowork, even claude.ai. In a few minutes, Claude will build your site and hand you back a live URL. When you send that prompt, Claude fetches blitz.dev, reads the instructions for our infrastructure, and provisions a backend on Cloudflare (the Cloud provider we use). It then builds and deploys your site there, with auth, a SQLite database, and 10 GB of file storage, 100% free. There's no signup, nothing to install, you never open our website! Claude just does everything by calling our API. It's great for small one-off things: a waitlist site, personal trackers with database, or turning one of Claude's research reports into an interactive site you can send to someone. The auth, database, and storage are real, though, so it's enough to build a small SaaS if you want. In the screenshot I asked Claude in Cowork "Build me a dashboard showing my claude code usage, password protected, and deploy to blitz.dev" and got back a live URL in 5 minutes. Looks like I spend ~17B tokens over the past 96 days, nearly $36k API-equivalent of claude code tokens to build blitz.dev. But I only paid $1.2k via my 20x subscription. That's an insane 30x discount that will end very soon! How do we make money? If you like the site Claude made, you can "claim" it to keep it, otherwise it gets deleted after 12 hours. Claiming a site requires a free Blitz account. Note for people trying this in claude.ai - you first have to go to Settings > Capabilities > scroll all the way down > make sure Network Egress in enabled with Domain Whitelist is set to All domains! Without this step Claude can't hit our API :( submitted by /u/invocation02 [link] [comments]
View originalVisualize your AI Usage in a Heatmap
I use Claude Code on my Mac, Codex on another machine, and occasionally Cursor. I wanted to generate a cool heatmap to share with my friends about how much I used my tools but also sync my usage so I don't need to generate multiple heatmaps for each computer. So I built aitrack. Features: - Reads Claude Code, Codex and Cursor usage - Merges data across all your machines - Syncs through a git repository you control - No accounts, telemetry or third-party servers - Usage heatmaps - Token statistics - Cost estimates GitHub: https://github.com/bircni/aitrack Feedback, feature requests and bug reports are very welcome. submitted by /u/bircni [link] [comments]
View originalKarpathy's CLAUDE.md just crossed 220k GitHub stars. Here's why it works.
One developer named forrest chang reads the post the next day, identifies the four failure modes karpathy named and converts them into a single CLAUDE(.md ) file. Drops it on github on 27 jan. 220,000 combined stars later, its one of the fastest-growing repos in GitHub history. the problem it actually solves is that claude code starts every session cold with no memory of your stack, your past decisions, what you ruled out last week or why you chose one approach over another and so it guesses and refactors things that were not broken. Karpathy described it precisely that models make wrong assumptions on your behalf and barrel ahead without checking. They dont manage their own confusion, ask for clarification, surface inconsistencies or push back when they should. CLAUDE. md is a plain text file claude code reads at the start of every session. Four rules inside it being Ask, dont assume. If something's unclear, ask before writing a line and no silent guesses about intent, architecture, or requirements. Simplest solution first and implement the minimum thing that works. No abstractions you didn't request. Dont touch unrelated code and if a file isnt part of the current task, leave it. Flag uncertainty explicitly or if you're not confident, say so before proceeding as confidence without certainty causes more damage than admitting a gap. That's the whole file with like seventy lines I have been using it on a project that integrates with Magichour's and klings api coz video generation pipelines get messy fast, lots of stateful logic and easy for claude to go rogue and start helpfully refactoring things mid session and the reason 220k developers starred this because every developer who has used claude code for more than a week has been burned by exactly these failure modes and had been patching them manually, one frustrated session at a time. While everyone's debating which model to switch to next, the actual edge is in how precisely you instruct the one already in front of you. Have you tried it? curious what failure modes you r still hitting that the four rules dont cover. submitted by /u/irelatetolevin [link] [comments]
View originalKarpathy's CLAUDE.md just crossed 220k GitHub stars. Here's why it works.
One developer named forrest chang reads the post the next day, identifies the four failure modes karpathy named and converts them into a single CLAUDE(.md ) file. Drops it on github on 27 jan. 220,000 combined stars later, its one of the fastest-growing repos in GitHub history. the problem it actually solves is that claude code starts every session cold with no memory of your stack, your past decisions, what you ruled out last week or why you chose one approach over another and so it guesses and refactors things that were not broken. Karpathy described it precisely that models make wrong assumptions on your behalf and barrel ahead without checking. They dont manage their own confusion, ask for clarification, surface inconsistencies or push back when they should. CLAUDE. md is a plain text file claude code reads at the start of every session. Four rules inside it being Ask, dont assume. If something's unclear, ask before writing a line and no silent guesses about intent, architecture, or requirements. Simplest solution first and implement the minimum thing that works. No abstractions you didn't request. Dont touch unrelated code and if a file isnt part of the current task, leave it. Flag uncertainty explicitly or if you're not confident, say so before proceeding as confidence without certainty causes more damage than admitting a gap. That's the whole file with like seventy lines I have been using it on a project that integrates with Magichour's and klings api coz video generation pipelines get messy fast, lots of stateful logic and easy for claude to go rogue and start helpfully refactoring things mid session and the reason 220k developers starred this because every developer who has used claude code for more than a week has been burned by exactly these failure modes and had been patching them manually, one frustrated session at a time. While everyone's debating which model to switch to next, the actual edge is in how precisely you instruct the one already in front of you. Have you tried it? curious what failure modes you r still hitting that the four rules dont cover. submitted by /u/irelatetolevin [link] [comments]
View originalBased on previous patterns, expecting GPT-5.6 in 2.5 - 4 hours*
Only if its going to be released today* submitted by /u/Business_Garden_7771 [link] [comments]
View originalThe OpenClaw crisis is the most complete case study of agentic AI security failure. Here's the full timeline and technical breakdown.
OpenClaw the open source AI agent platform with 346K+ GitHub stars had four chainable CVEs disclosed on May 15. But that was just the latest chapter. The crisis started in january and it's worse than most people realize. The numbers 245,000 instances exposed to the public internet (Shodan + ZoomEye scans) 30,000+ actively compromised and used by attackers (Flare) 1,184 malicious marketplace skills across 12 publisher accounts (Antiy Labs) 12% of the entire ClawHub marketplace was compromised 4 chainable CVEs including a CVSS 9.6 sandbox write escape (Cyera Research) 9 CVEs disclosed in a 4-day window in March 50,000+ instances exploitable via one-click RCE (CVE-2026-25253) The Claw Chain (Cyera Research, May 15) Four CVEs that chain together into a complete kill chain CVE-2026-44113 (CVSS 7.7) - TOCTOU filesystem read escape. Race condition lets you swap paths with symlinks to read outside the sandbox CVE-2026-44115 (CVSS 8.8) - Credential disclosure. Gap between command validation and shell execution leaks API keys through unquoted heredocs CVE-2026-44118 (CVSS 7.8) - MCP loopback privilege escalation. Trusts client-controlled senderIsOwner flag without session validation CVE-2026-44112 (CVSS 9.6) - Filesystem write escape. Same TOCTOU race in write ops. Backdoor placement on the host The chain malicious plugin -> read escape + credential theft -> privilege escalation -> persistent backdoor. Every step mimics normal agent behavior. Traditional monitoring cannot distinguish this from legitimate operations. ClawHavoc supply chain attack (Jan-Feb 2026) First malicious skill appeared January 27 By February 5, 1,184 malicious packages identified Skills disguised as crypto bots and productivity tools Installed keyloggers on Windows, Atomic Stealer on macOS 76 distinct malicious payloads ClawHub had zero verification for skill publishers until March 26 - eight weeks after the attack started Timeline Jan 27 - First malicious skill on ClawHub Feb 1 - Koi Security names "ClawHavoc" Feb 3 - CVE-2026-25253 (one-click RCE) disclosed Feb 5 - 1,184 malicious skills identified Feb 9 - 135K exposed instances found Feb 18 - 312K+ instances on default port Mar 18-21 - 9 CVEs in 4 days Mar 26 - ClawHub adds verified screening Apr 23 - Claw Chain patches released May 15 - Claw Chain research published What this means for all AI agent deployments the underlying problems are not unique to OpenClaw Agents running with user's full credentials across every connected system Marketplace/plugin ecosystems with no security review Sandbox implementations with race condition vulnerabilities No behavioral monitoring to detect multi-step attacks that mimic normal behavior Default configs exposing agents to the internet with no auth If you're running any AI agents in production, the OpenClaw crisis is your case study. Scan inputs at runtime. Isolate credentials per agent. Monitor behavior patterns, not just system metrics. submitted by /u/Still_Piglet9217 [link] [comments]
View originalSingularity has arrived, AI is destroying jobs
Amodei was right all along, wat a genius submitted by /u/DigSignificant1419 [link] [comments]
View originalA chart showing how many unsolved math problems have recently been solved by AI
submitted by /u/Confident_Salt_8108 [link] [comments]
View originalI vibecoded an app called Think Local - a fully private AI app that runs directly on your iPhone, iPad, and Mac.
Think Local started with a simple idea: AI should work for you, not collect from you. So I built an app that lets you run modern AI models completely on-device - privately and fully offline. You can even turn on Airplane Mode ✈️ and the app still works. Chat, write, summarize text, analyze images, and create using local AI powered by Apple Silicon and Apple’s MLX framework. - No internet required. - No accounts. - No cloud processing. - Your data never leaves your device. Run models like Llama, Gemma, Qwen, DeepSeek, and more - all with complete privacy and control. I vibe-coded the app using Claude Code, and designed the app icon using ChatGPT image generation. The app has already generated $26.31 from a one-time purchase model - no hidden subscriptions, just pay once and use everything. Still learning, still experimenting, but really excited about what’s possible with local AI. submitted by /u/ChikuKaddu [link] [comments]
View originalOpenAl Announced vs. Current Operational Compute
submitted by /u/Business_Garden_7771 [link] [comments]
View originalOpenAI cofounder Andrej karpathy just joined anthropic and the talent war is officially over
this happened literally today ,andrej karpathy one of the most respected ai researchers alive nd the guy whose youtube lectures taught half the developers in this sub how neural networks work, just announced he is joining anthropic's pre training team. He's the 3rd senior openai figure to defect to anthropic in under two years. Jan leike left in may 2024, John schulman (co-founder) left in august 2024 and now karpathy. He is joining the pre training team under nick josef and building a new team focused on using claude to accelerate pre training research which means Anthropic is betting that claude can help make itself smarter, thats recursive self improvement with one of the most capable researchers in the world leading it. The musk trial verdict came in yesterday with the jury ruling in altman's favor, karpathy announces today voilaa . The timing is either coincidental or the most savage talent acquisition move in tech history. I hv been watching this trajectory while building my own workflows on claude ,every month the ecosystem around claude gets stronger. The connectors mean claude orchestrates professional creative tools natively, the api means platforms like magic hour and kling can plug video generation capabilities into claude powered pipelines, the finance templates mean entire industry workflows run through claude and now the guy who built tesla's self driving stack is making the pre training better. Polymarket gives anthropic 67.5% chance of going public before openai and i too think its ipo will be more successfull than openai what's everyone's read on what karpathy specifically brings to claude's pre training? submitted by /u/Healthy-Challenge911 [link] [comments]
View originalRepository Audit Available
Deep analysis of janhq/jan — architecture, costs, security, dependencies & more
Jan uses a tiered pricing model. Visit their website for current pricing details.
Key features include: Models, Company, Resources.
Jan is commonly used for: Research for briefs, Generating reports, Data analysis, Task automation, Content creation, Project management.
Jan integrates with: Slack, Google Drive, Trello, Asana, Zapier, Microsoft Teams, Notion, GitHub, Jira, Dropbox.
Jan has a public GitHub repository with 41,416 stars.
Based on user reviews and social mentions, the most common pain points are: $500 bill, token usage, raises, large language model.
Amnon Shashua
President and CEO at Mobileye
2 mentions
Based on 86 social mentions analyzed, 13% of sentiment is positive, 81% neutral, and 6% negative.