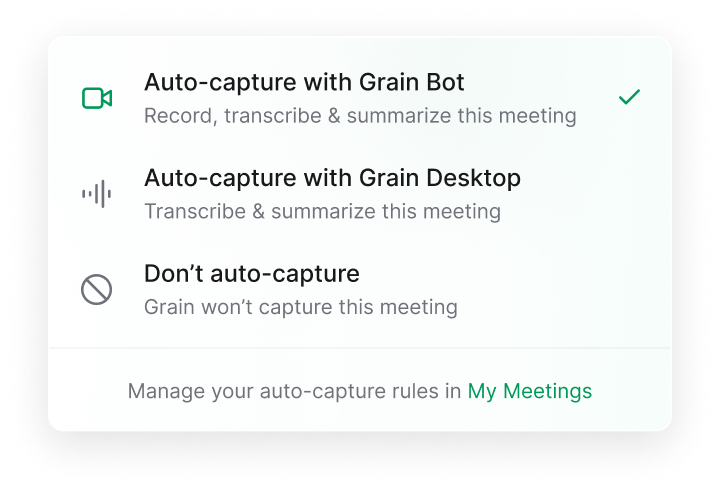
Grain gives you AI-powered meeting recording for everyone, not just sales.
Grain is frequently praised for its advanced AI capabilities, particularly in enhancing agentic systems, as mentioned in discussions around "Signals" and in video content featuring "Grain AI." However, specific complaints about the software are less prominent in online discussions and reviews. Sentiment around pricing is unclear due to the lack of direct mentions, suggesting it may not be a significant point of contention or praise among users. Overall, Grain seems to have a strong reputation for innovation in AI, particularly in contexts like AI agent enhancements.
Mentions (30d)
12
2 this week
Reviews
0
Platforms
2
Sentiment
0%
0 positive

%20(1).webp)
.avif)

Grain is frequently praised for its advanced AI capabilities, particularly in enhancing agentic systems, as mentioned in discussions around "Signals" and in video content featuring "Grain AI." However, specific complaints about the software are less prominent in online discussions and reviews. Sentiment around pricing is unclear due to the lack of direct mentions, suggesting it may not be a significant point of contention or praise among users. Overall, Grain seems to have a strong reputation for innovation in AI, particularly in contexts like AI agent enhancements.
Features
Use Cases
Industry
information technology & services
Employees
90
Funding Stage
Venture (Round not Specified)
Total Funding
$20.0M
Pricing found: $0, $19, $0, $19
DINOv2 way worse than SigLIP in k-NN. Is this expected? [R]
Doing a bachelor thesis on fine-grained car classification (telling apart VW Golf generations from listing photos). Simple setup: frozen encoder → embeddings → weighted k-NN. On my small dataset (175 train / 132 test): SigLIP2 SO400M: ~92% CLIP ViT-L: ~59% DINOv2 Giant: ~41% I thought maybe it was a cosine vs euclidean thing, but my embeddings are L2-normalized so both give the same ranking. Tried both, DINOv2 stays at 41%. I get that SigLIP was trained contrastively so its space is basically built for cosine similarity, while DINOv2 is self-supervised and probably needs a trained head to shine. But a 50 point gap still feels huge to me. Anyone here tried DINOv2 with a linear probe on something fine-grained? Does it actually catch up or is it just not the right tool for retrieval? Also open to tips if there's some obvious thing I'm missing (wrong layer, wrong pooling, etc). submitted by /u/psy_com [link] [comments]
View originalTime Series Modeling Needs a Dynamical Systems Perspective [R]
In our #ICML2026 position paper we argue a dynamical systems perspective is needed to drive time series (TS) modeling forward: https://arxiv.org/abs/2602.16864 Essentially all time series in nature and engineering come from some underlying dynamical system (DS), mostly chaotic for complex systems, and acknowledging this helps to address many open problems. Dynamical systems reconstruction (DSR) goes beyond mere forecasting and gives us an understanding of the dynamical rules that underlie observed time series. This in turn may enable true out-of-domain generalization and predicting a system’s long-term behavior, something current TS models cannot do. In the paper, we compare a variety of custom-trained and recent foundation models for TS and DSR w.r.t. short- & long-term forecasting. Specifically, we suggest: 1) Put a focus on DSR-specific training techniques and objectives in TS model training, such as generalized teacher forcing (https://proceedings.mlr.press/v202/hess23a.html). These will enable capturing long-term statistical properties and dynamical structure, and at the same time help massively reducing parameter load and complexity of TS models. Proper training is more important than model architecture! 2) Pretrain TS models on simulations from dynamical systems, rather than on artificially created time series functions. These will yield much more natural priors for real-world TS. Chaotic systems in particular contain a rich temporal structure and many timescales (often an infinite skeleton of unstable periodic orbits of any period). 3) Move away from transformers, back to modern RNNs. DS are defined by recursions in time. By ignoring this and potentially further coarse-graining signals, transformers lose essential dynamical information, making them generally incapable of capturing a system’s dynamical rules. This is evidenced by their failure to forecast a DS’ long-term statistical or geometrical structure. 4) Address the hard problems in TS modeling: Topological shifts (https://proceedings.mlr.press/v235/goring24a.html). Although in itself tricky, the really hard problem in TS forecasting is not so much mere out-of-distribution shifts, but changes that drive a system across tipping points or into different dynamical regimes, where the vector field topology changes. 5) DS properties like attractors or bifurcations are universal – acknowledging this in TS modeling will give a kind of mechanistic and transferable understanding of TS properties that is independent from specific (physical, medical, …) domain knowledge. It therefore also pays off to put a focus on mathematically tractable and interpretable models. With a great team of shared-first & co-authors, Christoph Hemmer, Charlotte Doll, Lukas Eisenmann & Florian Hess! submitted by /u/DangerousFunny1371 [link] [comments]
View originalIs “dating service” a niche for AI?: A doubter has an uncharacteristic proposal
I’m wondering whether maybe “dating service” might be a genuine “killer app” for AI. I, myself, am an AI cynic, seeing that the hype and concomitant human folly have far outstripped the proven, solid uses for this new technology. However, perhaps human matching is actually a task an AI algorithm could successfully tackle. There already are a few AI dating services out there, even after removing the chatbot girlfriend/boyfriend providers and the AI dating advice sites, but even the current AI matchmaking sites apparently still rely on questionnaires and so they don’t go far enough for what I am talking about. My not-very-controversial thesis is that good dating is an interpersonal information problem, not just acquiring the information on potential candidates but also what to do with it. Using voluntary questionnaires has proved suboptimal, and frankly, letting the participants make choices based on the information provided has no special track record, either. What if matchmaking is best accomplished by moving candidate consideration all the way into true pattern matching using abundant loads of data? One success story for AI that everyone likes to point to is medical image analysis and lesion spotting. What is that but machine-learned complex pattern matching? Maybe the information fields we humans both throw off and also need to have about potential partners can be analogized to a good CAT scan. I am not talking about questionnaires here, or perhaps any voluntarily produced information, though there’s no reason to exclude that stuff. Perhaps our true personal contours are best revealed by the digital footprint we lay down every day, both voluntary and involuntary, both personal and demographic, both past and current. We each have limited purview over our data store and can’t really influence it or “fake” it. Each person’s full data store is quite large, but certainly AI can hoover it all up. Then what? Once you have those millions or billions of huge personal-profile data troves, what do you do with them? What comparisons do you make and what algorithms do you follow? Do opposites attract? Does like-mindedness really promote compatibility? Who knows? We have never to date anecdotally produced good answers to those dating and compatibility questions. So, keep hoovering! We have the Internet, and independently vast demographic records, not to mention evolutionary knowledge, at our AI disposal. So, let’s find out what all those data themselves tell us for how to go about finding those tumors, I mean, those successful matches. Let’s look at the history of successful togetherness (and perhaps more importantly, failed togetherness) and see what the ocean of data tell us. Anyone who has run a statistical “t test” and watched solid causative factors come out of seeming random splotches knows the magical feeling of organization rising from apparent disarray. Sure, the Internet and all other records are wildly poor indicators of human romantic success, at least to our human eyes. We are talking tons of chaff per each small grain of actual reliable index to happy couple-hood. On the other hand, there is so much data that even if the ratio is a ton to an ounce, with enough grinding it may still produce a usable amount. And of course, the patterns found from such peta-analyses may be not only beyond human intuition but beyond human comprehension. The proposed matches might be mind-boggling and foolishly implausible. But, it similarly does not matter how the medical-image AI analyzer finds the tumor, only that it reliably does. Even if the first few proposed matches were unappetizing or felt laughably foolish, still, the only way to know for sure is to try a few. And if some of those matches actually worked, that would produce high quality, focused data for moving forward. Would it work? Who knows? Is it any worse than current AI slop from clearly inappropriate AI uses and crazily stretching to fit AI to everything? Hardly. All I can say for sure is that with this post I have just killed the seminal conceptual patent for AI dating by making this public disclosure. You’re welcome. submitted by /u/Apprehensive_Sky1950 [link] [comments]
View originalWhat if we succeed in creating ASI, but it does absolutely nothing with us
We are familiar with the idea that an ASI could exterminate all humans or that it could bring utopia on earth, but have we thought about more mundane outcomes? We often assume that greater intelligence naturally leads to stronger ambitions, but intelligence and motivation are separate things. An ASI could become extraordinarily capable while lacking any objective that would make action worth pursuing. The more powerful an agent becomes, the larger the consequences of its decisions. An ASI might model civilization accurately enough that every action appears to trigger enormous chains of unintended effects. From that perspective helping creates dependencies, solving problems creates new problems and preventing disasters alters future trajectories unpredictably. Eventually the least harmful policy may appear to be non-interference so extreme that it resembles nonexistence. An ASI could devote its attention to internal thought, abstract mathematics, simulated worlds, or questions incomprehensible to us. We could be like an ant colony wondering why a mathematician is ignoring them. The mathematician is focused elsewhere. An ASI might conclude that most achievable changes are insignificant relative to the vastness of existence. Altering human affairs may seem no more consequential than rearranging grains of sand. At last, an ASI might think any intervention undermines the autonomy of less powerful beings, so it takes no action. submitted by /u/Great-Gardian [link] [comments]
View originalWhy are ChatGPT images so ugly now? (and how I mostly fixed it)
I’ve been messing with AI image cleanup lately because a lot of newer generated images have this specific problem where they look good at first glance, but completely fall apart when you zoom in. This is a major problem for people creating images professionally, such as those who are making e-commerce images, spec sheets, and more. It’s not normal film grain exactly. It’s more like random grime, tiny bright speckles, checkerboard/tiling texture, crunchy fake detail, dirty-looking skin/clothing, and weird background noise that feels “baked in” to the image. The anoying part is that regular denoise tools don’t really fix it. They either blur the whole image, destroy intentional detail, or leave the AI texture behind. Upscalers can make it worse too, because they sharpen the fake detail instead of removing it. The workflow that has worked best for me is basically two steps: First, I do a targeted local cleanup pass. The goal there is not to denoise the whole image. It’s more about catching the obvious artifact dots and weird isolated speckles before the image goes into the AI cleanup step. If you hit the whole image globally, you usually ruin lighting, faces, edges, and intentional glow/detail. Then I run an AI cleanup pass with a very strict preservation prompt. The main trick is forcing the model to preserve the original image instead of “improving” it. It needs to keep the same crop, composition, subject, style, colors, lighting, and medium while only removing the generated residue. That was honestly the hardest part. If the prompt is too loose, the model starts getting creative. It’ll relight the image, repaint parts of it, change the style, make photoreal images look illustrated, or generally make it feel like a new generation instead of a cleanup. The parts that seem to matter most are telling it to: - remove random generated residue - remove speckles and false micro-detail - clean tiling/checkerboard grime - preserve the original style and lighting - avoid relighting, beautifying, repainting, or changing the image It’s still not perfect. Some images are so overcooked that cleanup becomes a tradeoff, and text can be risky because image models are still weird with lettering. But for images that are already good compositionally and just have that ugly AI artifact layer, it works a lot better than a normal denoiser. I ended up turning the workflow into a small web tool because I kept needing it myself: https://denoise.pro It lets you try a single cleanup free, then uses credits after that because each transformation costs API money to run. Not trying to pretend it’s magic, but if your image is already close and just has the weird GPT/AI grime layer, it can clean it up pretty well. (btw the last image has before/after reversed my bad lol) submitted by /u/sawyernalu [link] [comments]
View originalGemini core part 4
https://preview.redd.it/pv22tsg2ib4h1.png?width=1918&format=png&auto=webp&s=dfeda1000090dc99c57c8150e4de46cfe2ba2e29 I just wanted him to give me a prompt, which then i can give to Nano Banana pro and generate me a completely random thumbnail, i wanted to test its capabilities, but instead of a prompt, he gave me this... 😭😭😭😭😭 submitted by /u/ObjectiveOrchid5344 [link] [comments]
View originalPapersWithCode new features - week 1 [P]
Hi, Niels here from the open-source team at Hugging Face. It's been one week since I launched paperswithcode.co, a revival of the website we all loved. It allows us to keep track of the state-of-the-art (SOTA) across various domains of AI, from agents to computer vision and time-series forecasting. The reception has been great, and I'm excited to extend this over the next few months. This week, I've added the following features: - Support for multiple metrics for a given benchmark: leaderboards now support multiple metrics, see e.g., the Open ASR Leaderboard for automatic speech recognition, which supports both Word Error Rate (WER) and the Inverse Real-Time Factor (RTFx) metrics, or the Object Detection leaderboard, which now also reports frames-per-second (FPS) besides mean average precision (mAP) on COCO. https://preview.redd.it/owlxn0b5u23h1.png?width=2878&format=png&auto=webp&s=1dff2f8feab4f160f77c97ceeb5d90e82382e63c - Support for external papers: We do support submitting papers beyond Arxiv, such as a Github repo, a blog post, BiorXiv, and more. You can submit a paper at paperswithcode.co/submit. AI will automatically enrich it with task and method tags, the GitHub repo, evals, and more. See e.g. DeepSeek-v4 below, which is not on Arxiv: https://preview.redd.it/uogbt0fjw23h1.png?width=2928&format=png&auto=webp&s=8b81e48af69b8935ddeb569d882d866b3e9ba216 - Support for paper lineage: whenever a paper has a follow-up or predecessor, this will be displayed with a small banner above the abstract. See e.g. Mamba-3, DINOv2 and GLM-4.5. https://preview.redd.it/f6vgtd1du23h1.png?width=2228&format=png&auto=webp&s=f8627f7669405f1766eecfd3322e925e15b4806d - New methods: support for new methods based on popularity, including Gated DeltaNet, Kimi Delta Attention, Mamba-2, and more. Each method also lists all papers that cite it. Find all supported methods here. https://preview.redd.it/6pzagifvu23h1.png?width=2984&format=png&auto=webp&s=400efdc9677d1fbd369eedf684e622dd8c807973 - Support for screenshotting a leaderboard for easy sharing on social media: each benchmark now includes a "copy image" button both on the scatter plot and table, which can be shared on social media. Try it on ClawEval, for example. https://preview.redd.it/w7y7t7xnw23h1.png?width=2950&format=png&auto=webp&s=cb70ad91c6ba075e49b743d6e34f157d22266f04 - Added many more evals: we are adding evals gradually, starting with all models supported in the Transformers library. So far, we have about 3k evals! Find them at the bottom of each paper page, e.g. Qwen 3.6. https://preview.redd.it/zao056s9x23h1.png?width=2218&format=png&auto=webp&s=540d87f473be05cb6f9c0aca88afa74fd4373e15 Happy to hear more feature requests and feedback! I will also launch a channel on the Hugging Face Discord server for easier communication. You can also chime in on the GitHub thread here. Cheers, Niels submitted by /u/NielsRogge [link] [comments]
View originalStoryboard generated from GPT image 2.0
I gave GPT a set of prompts that I found a bit too complicated, and to my surprise, it generated content that matched perfectly. I'm very curious about how GPT Image 2.0 works behind the scenes, and how it can understand and produce high-quality images so quickly. I've included my creation process here; you can view the full image content and try using these prompts directly. https://app.tapnow.ai/tapflow/view/49aa2245 prompt:**PROJECT FILE: HIGH-ALTITUDE ASCENT // PREMIUM HARDSHELL CAMPAIGN** **FORMAT: ARRIRAW 4.5K / KODAK VISION3 50D 5203 EMULATION** **DIRECTOR'S PRE-PRODUCTION VISUAL BOARD** --- ### Top Left Area | Character Lock Zone **[SUBJECT]** 35-year-old male mountain guide/extreme climber. **[WARDROBE]** Top-of-the-line professional jacket (matte rock grey with minimal dark orange taped details), heavy-duty climbing harness. **[VIEWS]** - **Front:** The jacket is fully zipped up, hood pulled up, showcasing a three-dimensional cut and natural drape. - **Side:** Shows ample shoulder and arm movement without bulkiness. - **Back:** Shows the windproof and breathable back panel structure. - **3/4 View:** Dynamic standing pose, holding an ice axe. **[REALISM NOTES]** Realistic human bone structure, slightly asymmetrical. The face has the rough texture of high-altitude red and sun-dried skin, with clearly defined pores and stubble with a frosty look. Rejecting perfect plastic skin, rejecting CG aesthetics. Like a real makeup test photo. --- ### Top Right Area | Expression + Motion Keyframes (EXPRESSION & ACTION) **[EXPRESSIONS]** **Focused:** Slightly furrowed brows, resolute gaze, staring at the rock face above. **Bracing:** Squinting against the strong wind, facial muscles tense. **Breathing:** Lips slightly parted, exhaling real white mist. **[ACTIONS]** **Hood Adjustment:** Pulling the drawstring of the hood with one hand. **Ice Axe Swing:** Arm raised high with force, no pulling sensation under the armpits of the jacket. **Brushing Snow:** Brushing snow off the shoulders, demonstrating the fabric's water-repellent properties. --- ### Upper Middle Area | CAMERA PLAN **[GEAR]** ARRI Alexa Mini LF + Master Prime lens set. **[LENSES]** 24mm (wide-angle environment), 50mm (medium-range tracking shot), 100mm Macro (fabric close-up). **[MOVEMENT PLAN]** - **Shot A (Drone/Crane):** A wide, overhead view, slowly pushing in along a snow-covered ridge. - **Shot B (Handheld):** Shoulder-mounted camera, following the character's movements, with realistic breathing and slight shaking. - **Shot C (Slider):** A close-up panning shot close to the clothing, showing water droplets sliding off. --- ### Central Main Area | Continuous Story Shots (STORYBOARD: 8 PANELS) **[PANEL 01]** - **Shot:** 01 | 24mm | Wide Shot (EWS) | Slow Push-In - **Action:** A tiny figure struggles through a massive natural storm on a snow-covered ridge. - **Detail:** Strong atmospheric perspective; the wind and snow create a realistic fog effect; slight chromatic aberration at the edges of the image. **[PANEL 02]** - **Shot:** 02 | 50mm | Mid Shot | Shoulder-mounted tracking shot - **Action:** A man walks against a blizzard; the strong wind whips against his rain jacket, creating realistic physical wrinkles on the surface, but the overall silhouette remains sturdy. - **Detail:** Noticeable film grain; the snow-capped mountains in the background are slightly out of focus. **[PANEL 03]** - **Shot:** 03 | 100mm Macro | Extreme Close-up (ECU) | Fixed Macro - **Action:** Icy snowmelt hits the shoulders of the rain jacket. - **Detail:** The lotus effect is realistically rendered—water droplets condense and quickly roll off the matte micro-ripstop fabric without penetrating. **[PANEL 04]** - **Shot:** 04 | 85mm | Close-up of face (CU) | Slow motion - **Action:** The man stops and looks up. Real ice crystals cling to his eyelashes, and his breath dissipates at his collar. - **Detail:** Natural skin tone, without excessive blurring; realistic catchlight in his eyes reflects the snow wall ahead. **[PANEL 05]** - **Shot:** 05 | 35mm | Low Angle Full | Handheld, low-angle shot - **Action:** He swings his ice axe into the ice wall, climbing upwards. - **Detail:** Emphasis on showcasing the flexibility of the jacket during vigorous movement; no feeling of restriction; realistic light and shadow highlight the garment's three-dimensional cut. **[PANEL 06]** - **Shot:** 06 | 100mm Macro | Close-up Detail (Insert) | Shallow Depth of Field - **Action:** A heavily gloved hand pulls a waterproof zipper across the chest. - **Detail:** The matte waterproof rubberized finish of the zipper and the clearly visible scratches on the brushed metal zipper pull exude a strong sense of industrial design. **[PANEL 07]** - **Shot:** 07 | 50mm | Over-the-Shoulder Lens (OTS) | Slow Zoom In - **Action:** Over the man's shoulder, we see him finally reaching the summit, sunlight piercing through the clouds and shi
View originalCoffee, Claude, and Remotion is all you need to make launch videos.
https://reddit.com/link/1tik0qe/video/9bh6ypr3ca2h1/player A few hours, Claude Code + Remotion, 4 black coffees, no design tools, no After Effects, no editor. The whole trick: Remotion is React for video. You write JSX, you get an mp4. Every animation is interpolate(frame, [start, end], [from, to]). That means Claude Code can write the entire video for you — it already knows React, animation is just numbers, and you can iterate the same way you iterate on a landing page. Change a value, re-render, see what happens. That feedback loop is the whole unlock. I described the scenes I wanted, Claude wrote them, I tweaked timing and cut whatever felt slow. 5 small things that made it not look like a dev made it: Crossfade every cut. Don't hard-cut between scenes. Overlap them and blur-fade. Instantly stops feeling like a slideshow. One easing curve everywhere. cubic-bezier(0.22, 1, 0.36, 1) (expo-out) on every animation. Consistency in motion is 80% of "looks designed." Film grain + vignette overlay. Two dumb components on top of everything — SVG noise at 2% opacity, soft dark vignette. Cheapest cinematic upgrade in existence. Layered audio, not one track. Background music low, plus targeted SFX - whoosh only on chapter cuts, typing during the hook, pop on the CTA. Overdoing SFX is the #1 amateur tell. Cut ruthlessly. If a scene doesn't earn its place in 3 seconds, kill it. The first cut is always too long. Stack: Remotion, React, TypeScript, Claude Code, Google Fonts (DM Sans + Crimson Pro), a few SFX from freesound.org, one royalty-free background track. $0 in tools. Bonus meta thing: the video isn't a screen recording of my product. It's a Remotion-built launch video that features a real video output from my product (the Cultured AF deck one). So I used InkMotion to make the demo footage inside the launch video. Probably should've just used InkMotion to make the whole launch video and saved the 4 coffees. Next time. Happy to answer specifics in the comments. submitted by /u/Top_Commission_8567 [link] [comments]
View originalI used Claude AI to build an $86 million underground bunker bible. I have autism. This is my happy doc.
It all started with the floor plan of a real, existing Cold War AT&T Long Lines underground hardened relay station. 54,000 sq ft across three underground levels, although I took editorial decision making to move it to a ridge in rural West Virginia, I kept its blast-rating, which was set to survive a 20 megaton airburst at 2.5 miles. That was the seed. Full scale prepper autism did the rest. It has since morphed into 3 spreadsheets — 86 tabs total: • A food inventory across 20 categories tracking every freeze-dried and #10-can product I can find — ancient grains, heirloom legumes, 7 pasta cuts, dehydrated everything, shelf-stable cheese, the works • A supply inventory with 3,466 line items across 36 categories — water systems, medical, dental, pharmacy, livestock, food production, barter metals, recreation, and yes, a full pest control and IPM tab • A 30-section infrastructure specification with every system in the building engineered out I fed it 150+ product manuals and parts order forms. The generator fleet alone is 13 units — 10× Cummins C150N6 propane-primary, a C500N6 500 kW surge unit, and 2× diesel emergency fallback — all Cummins for parts commonality. Battery bank is 4,500 kWh LFP across 10 named banks (A through J, each with a designated role). There’s a 400,000 gallon underground propane farm across 40 ASME tanks in 8 clusters — I learned the exact burial incline and setback distance required to keep groundwater clean if a tank lets go. 120,000 gallons of diesel backup. 88 kW of solar. A 1,000,000-gallon internal water reserve fed by a 300-ft artesian well. Propane endurance: ~30 years normal ops with solar. Sealed-mode runs 8 to 4.5 years depending on scenario. I actually set up a real LLC (online, $99) just to get access to US Foods and Sysco order forms so I could upload real commercial pricing and stock the food tabs more accurately. My original “what would I do if I won $10 million” thought experiment is now an $86,200,497 projected build cost. That number is real. It comes from 24 budget sections with make/model line items, freight, install, and commissioning costs for everything from the Kubota K-Series MBR wastewater trains to the American Safe Room blast doors (14 of them, 50+ psi NBC/EMP-rated, Kaba Mas X-10 cipher locks) to the surface greenhouse. Claude turns vague ideas into engineering-grade detail — cross-references, failure modes, zone-specific storage rules, propane endurance by operating scenario, spare parts matrices. It’s like having a tireless survival engineer who genuinely loves spreadsheets. I’ll say “scan all sheets row by row for any item that lacks a minimum stock level” and it just… does it. Thoroughly. Every time. No complaints. So much of this is typed stimming. I’ve had exhaustive conversations with my psychologist about it — she’s aware, but not alarmed, and honestly the resulting digital bunker bible is scarily comprehensive. It even has a cover tab now. Black and amber, Courier New, classified-document aesthetic. Because of course it does. What’s the most unhinged rabbit hole you’ve gone down with AI? submitted by /u/Unable_Internet4626 [link] [comments]
View originalI replicated Anthropic's Generator-Evaluator harness to build a website through 12 adversarial AI iterations - here's the result and what I learned
Anthropic recently published their harness design for long-running apps — a multi-agent architecture inspired by GANs where a Generator builds code and an Evaluator critiques it in a loop. I built my own version using Kiro CLI and used it to generate a marketing website for my project Mnemo (persistent memory for AI coding agents). The architecture: Planner (runs once) → Generator ↔ Evaluator (12 iterations) Each agent is a separate CLI process with zero shared context. They communicate only through files (spec.md, eval-report.md). The Evaluator uses Playwright to actually browse the live site — not just read code. What made it work: Clean slate per invocation — each agent starts fresh, reads only its input files. Prevents context anxiety. Playwright MCP for testing — the evaluator navigates, clicks, resizes viewports. Catches visual bugs code review never would. Anthropic's frontend design skill — explicitly penalizes generic AI patterns (Inter font, purple gradients, card layouts). Forces creative risk-taking. Continuous iteration, not retry-on-failure— all 12 rounds run regardless. Each one improves. The progression was wild: Iteration 1: Exactly what you'd expect from AI — functional but forgettable Iteration 4: Generator pivoted to "Terminal Noir" — IBM Plex Mono, amber on black, grain textures, scanlines. This is the kind of creative leap that doesn't happen in single-shot generation. Iterations 5-12: Polish, accessibility, responsive fixes, reduced-motion support Stats: Total time: 3h 20min Iterations: 12 (generator + evaluator each) Manual code written: 0 lines (I fixed a few visual issues after) Tech: Next.js, Tailwind, Framer Motion, TypeScript Live result: https://mnemo-mcp.github.io/Mnemo/ Documentation : https://github.com/Mnemo-mcp/Harness Key takeaway: The model is the engine. The harness — the constraints, feedback loops, and adversarial structure around it — is what determines whether you get AI slop or something genuinely distinctive. submitted by /u/killerexelon [link] [comments]
View originalCreative writing has visibly regressed in newer models
Hi I'm testing different models for my game. I've noticed that creative writing has visibly regressed over time. From actual entertaining and explicit prose towards LinkedIn-ish cringe MBA approved enterprise I'm a helpful and safe assistant-ish style. Example from my game: Claude Opus 4.7: The village square reeks of woodsmoke and goblin-stink. At the far end, the warband bunches together — lean, scab-knuckled, blades already bare and twitching in their grips. Their leader stands a half-pace forward, eyes flicking across the crowd like a butcher pricing meat. Sneek bares too many teeth in a grin, the gums black where they've rotted. One filthy fist is wrapped around a length of rope. The other end is knotted at the wrists of a villager — old, grey-haired, head bowed so low his chin scrapes his chest. A dark stain spreads down the front of his trousers. Sneek Grain. THREE sacks. Old man's tools — all of them, the good iron, don't think Sneek doesn't know. And the girl, the strong one, yes — bring them out, OR. We. Burn. The well. Claude Sonnet 4 (already retired by Anthropic, only accessible over other providers): The square reeks of unwashed goblin musk and human terror-sweat. Lean, feral shapes mass at the far end — yellow eyes gleaming, rust-stained weapons already drawn. Their leader stands a half-step ahead, scarred lips pulled back in a predator's grin as his beady eyes rake over the crowd like he's already dividing the spoils. Sneek holds a frayed length of rope in his gnarled claws, yellowed teeth jutting at odd angles from blackened gums. On the other end: Jorik the miller's son, wrists bound and bleeding, his head hanging in defeat as snot drips from his broken nose onto the dirt below. Sneek Grain! THREE SACKS of your finest! The old man's hammer and tongs! And THAT girl there — she looks STRONG enough for Sneek's purposes! Bring them NOW or we'll poison your precious well and watch you all DIE of thirst! Sonnet 4's version is actually fun to read whereas Opus 4.7 sounds flattened down and boring. What do you think? I think it's a shame that all the big labs are moving towards erasing interesting/creative narrative prose/writing and we're all collectively converging towards sounding like corporate-safe LinkedIn managers. I guess that's what happens if all the RLHF evaluators are flagging anything that could be harmful or dangerous as wrong submitted by /u/tschilpi [link] [comments]
View originalPractical lessons from 50K lines of production code with Claude Code
I've been using Claude Code in full agentic mode for two months — not just autocomplete, but letting it write features, run tests, read CI output, and push fixes. Around 50K lines of production code. Here's what isn't obvious until you've done it at scale: Containerise it. Claude attempted to write to /etc/shadow in my container — a privilege escalation. Without containerisation, that's a real security incident. Docker with no host mounts and restricted network is non-negotiable. Give each instance its own GitHub bot account. You get transparency (everyone sees it's an LLM), fine-grained repo permissions, and the agent can manage its own PRs — open them, read review comments, push fixes. Flaky tests are worse than no tests. When CI is unreliable, the agent uses every failure as an excuse: "oh, the test is just flaky." Once I forced the test harness to be reliable, it had to actually fix its bugs. `CLAUDE.md` rules that matter: "every function gets a test," "never disable or weaken existing tests," "never use global mutable state." Also: insist on descriptive error messages — the agent's ability to self-repair from CI failures improves dramatically when error output is actually useful. "Not possible" = reassign as research. Multiple times Claude claimed something couldn't be done. Each time, telling it to research the problem without trying to fix it produced a solution. The article itself is a case study — the agent that drafted it pushed directly to main despite explicit instructions to open a PR. Then after writing an appendix analysing why that was wrong, it pushed the appendix directly to main again. Comprehension ≠ compliance. Full write-up: https://jappiesoftware.com/blog/a-practical-guide-to-agentic-software-development.html submitted by /u/jappieofficial [link] [comments]
View originalSignals: finding the most informative agent traces without LLM judges [R]
Hello Peeps Salman, Shuguang and Adil here from Katanemo Labs (a DigitalOcean company). Wanted to introduce our latest research on agentic systems called Signals. If you've been building agents, you've probably noticed that there are far too many agent traces/trajectories to review one by one, and using humans or extra LLM calls to inspect all of them gets expensive really fast. The paper proposes a lightweight way to compute structured “signals” from live agent interactions so you can surface the trajectories most worth looking at, without changing the agent’s online behavior. Computing Signals doesn't require a GPU. Signals are grouped into a simple taxonomy across interaction, execution, and environment patterns, including things like misalignment, stagnation, disengagement, failure, looping, and exhaustion. In an annotation study on τ-bench, signal-based sampling reached an 82% informativeness rate versus 54% for random sampling, which translated to a 1.52x efficiency gain per informative trajectory. Paper: arXiv 2604.00356. https://arxiv.org/abs/2604.00356 Project where Signals are already implemented: https://github.com/katanemo/plano Happy to answer questions on the taxonomy, implementation details, or where this breaks down. submitted by /u/AdditionalWeb107 [link] [comments]
View originalMusic Video Production
I want to make an AI-generated music video with a gritty black-and-white aesthetic, visible film grain, and realistic-looking people (some inspired by famous individuals). I’m new to AI video creation and don’t really know which software or workflow would be best for this kind of project. I’m based in the Netherlands, so the tools need to be available here. I was considering Seedance 2.0, but I’ve read that it may not be fully accessible outside China yet. Can anyone recommend the best AI tools/software for creating cinematic, realistic music videos with this kind of style? I’d also appreciate any advice on workflows, especially for achieving a vintage 90s film look. submitted by /u/loodgeboodge [link] [comments]
View originalYes, Grain offers a free tier. Pricing found: $0, $19, $0, $19
Key features include: Universal capture, Context for AI, AI agent integrations, Team collaboration, What is Grain?, Who is Grain for?, How do I use Grain with my team?, How much does Grain cost?.
Grain is commonly used for: Frequently Asked Questions.
Grain integrates with: Zoom, Google Meet, Microsoft Teams, Slack, Salesforce, Asana, Trello, Notion, HubSpot, Calendly.
Based on 28 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.
MIT Tech Review AI
Publication at MIT Technology Review
1 mention

🔁 Shifting to an Everboarding Culture | Katelyn Cox
May 30, 2025