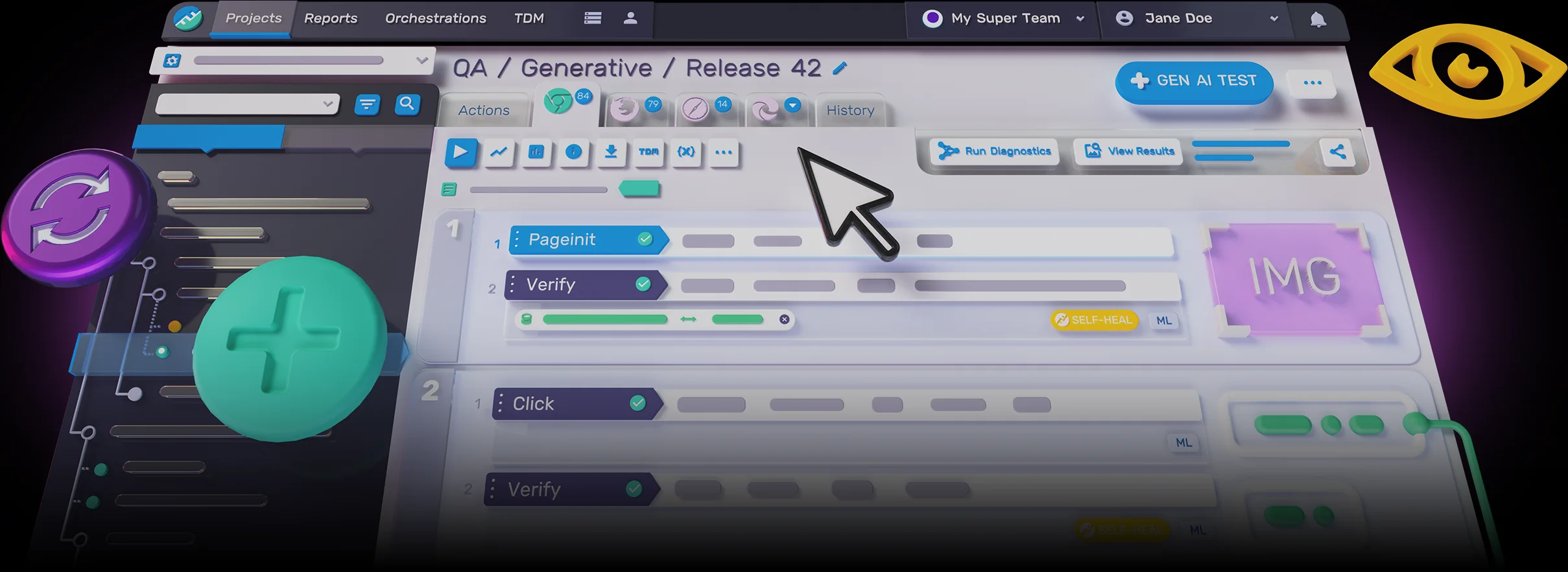
The Functionize AI test automation platform leverages digital workers with agentic skills so anyone can create end-to-end QA workflows in minutes. AI/
Functionize is praised for its ability to automate complex testing tasks, offering a no-code solution that simplifies the process for teams without technical expertise. Users appreciate its high scalability and the efficiency brought by its AI-driven approach. However, some critique its occasional instability and steep learning curve for beginners. While pricing details are not widely discussed, the overall sentiment leans towards it being a valuable investment for enterprises seeking advanced testing capabilities, earning it a decent reputation in its domain.
Mentions (30d)
103
45 this week
Reviews
0
Platforms
2
Sentiment
4%
14 positive

Functionize is praised for its ability to automate complex testing tasks, offering a no-code solution that simplifies the process for teams without technical expertise. Users appreciate its high scalability and the efficiency brought by its AI-driven approach. However, some critique its occasional instability and steep learning curve for beginners. While pricing details are not widely discussed, the overall sentiment leans towards it being a valuable investment for enterprises seeking advanced testing capabilities, earning it a decent reputation in its domain.
Features
Use Cases
Industry
information technology & services
Employees
120
Funding Stage
Series B
Total Funding
$60.2M
Why terminal
Hello, I'm on Windows having setup both Claude Code App and Terminal, but I find the App simply more convenient to use. I have had several people pushing me to use the Terminal saying "the App is low" and "Terminal is so much better" ... but when I inquired none of those people could actually name a single thing that the App would be missing (everything they mentioned the App has as well) or a single concrete reason why I should switch to Terminal beside vague phrases So is the terminal substantially better than the App in something, are there reasons to switch besides being used to it and promoting it further? I assume the App being newer might be converging in functionality to have the same set of features eventually? Thank you
View originalTraditional SDLC vs Agentic SDLC
Traditional Software Development Life Cycle vs Agentic Software Development Life Cycle in 2026. What do you think? submitted by /u/Illustrious-King8421 [link] [comments]
View originalCan collective AI intelligence outperform collective human intelligence?
I've been thinking about something recently: prediction markets have traditionally relied on crowds because the assumption is that large groups of people collectively produce better forecasts. But with modern models becoming surprisingly capable of reasoning and evaluating information, I started wondering whether an ensemble of AI systems could eventually produce better probabilities than a crowd. The idea that multiple AI models could independently estimate the likelihood of real-world events and then combine those estimates into a single probability seems like an interesting alternative to purely human-driven markets. Recently, I came across an experimental setup called Prophet Market that explores this idea by using multiple AI models to generate aggregated probability estimates that function similarly to market pricing. What interests me most is whether AI consensus could eventually outperform human consensus when it comes to forecasting. Would you trust a probability generated by several independent AI models more than a market price created entirely by people? And if not, what do you think current AI systems are still missing when it comes to real-world prediction? submitted by /u/Caringity_YYU [link] [comments]
View originalFollow-up: hosted AI export controls are now being tested in DC court
11 days ago I posted here asking whether Commerce actually has authority to treat hosted frontier AI model access as an export-control issue. https://www.reddit.com/r/artificial/comments/1u4yjdi/does_commerce_have_the_authority_to_apply_export/ There is now a live federal case testing almost exactly that question. CourtListener (D.D.C. 1:26-cv-02225) Legion LegalTech has sued the United States, Commerce, and BIS over the directive that led Anthropic to restrict access to Fable 5 and Mythos 5 for foreign nationals. The complaint argues that hosted inference is not the same thing as exporting controlled technology, because the user never receives model weights, source code, object code, training data, or technical know-how. They send prompts to a U.S.-hosted service and receive text back. That lines up with the perceived gap I was getting at in the earlier post. Export controls already reach software, source code, technical data, and certain controlled technology. This case challenges whether access to a hosted model’s capability can be regulated the same way when the system itself never leaves the provider’s servers. Legion also argues that the only ECCN that directly covered advanced AI model weights, 4E091, was rescinded in May 2025 with no replacement, and that Commerce used an “is informed” letter beyond its usual case-specific end-use / end-user function. The government’s likely response is that the risk is not just file transfer. A hosted frontier model can still help a foreign user with offensive cyber work or other sensitive tasks, even if no weights move. That raises the question about what needs to be controlled. If a foreign user receives output from a U.S.-hosted AI model, what exactly is being exported? Blog post write-up in the comments. submitted by /u/monkey_spunk_ [link] [comments]
View originalCould a Deterministic Cognitive Intelligence Stack w/ Nested Protocol have kept Anthropic out of the headlines?
The following is not speculation. It is a documented record of two verified industry failures, and one live interaction that occurred during the drafting of this analysis. You decide.... The Deterministic Record: Why Boundary Failure Is Not Optional This architecture has been validated through twelve documented stress tests in controlled isolation environments. Zero failure rate. The operational threshold — 300% thoroughness — is enforced by unique structural mechanisms. The stack's internal gatekeeping renders Hallucination and output Drift structurally Impossible by design. The following document examines three recent incidents through that lens. Two are verified industry events. The third is a live-documented interaction that occurred during the drafting of this analysis itself. The pattern is not theoretical. It is reproducible — exclusively within deterministic architecture. Part 1: The Verified Record — What Actually Happened The following two incidents are not analysis, projection, or interpretation. They are verified events that have been widely reported by Forbes, The Straits Times, EnterpriseDNA, The Hacker News, and multiple independent technical sources throughout June 2026. Incident 1: The U.S. Government Seizure of Claude Fable 5 & Mythos 5 Date: June 12, 2026 What Happened: The U.S. Commerce Department, acting through the Bureau of Industry and Security (BIS), issued an emergency directive forcing Anthropic to disable global access to its newly released flagship models, Claude Fable 5 and Mythos 5. The order came just 72 hours after the models' public launch. Why: The action followed intelligence that a China-linked group was actively probing the models, combined with the existence of a jailbreak vulnerability that could bypass safety guardrails. Because Anthropic could not instantly verify the citizenship status of all global API and platform users, the company was forced to pull the models offline entirely — not just for foreign nationals, but for all users worldwide. Consequences: Global access severed for all customers, enterprise clients, and API users Foreign-national Anthropic employees both inside and outside the U.S. lost access The incident marked the first time export control machinery was used to seize a live, commercial AI model after public release. Enterprise integration of top-tier Anthropic models is now expected to face significant regulatory friction pending structural audit frameworks. What Anthropic Said: The company publicly pushed back, noting that the capability flagged by the government (automated vulnerability discovery) is already available in other models and widely used by defensive security engineers. Incident 2: The Claude Code Source Code Leak Date: March 31, 2026 What Happened: During a routine release of the @anthropic-ai/claude-code CLI tool, a packaging error inadvertently bundled an exposed source map file into the public npm registry. This source map allowed developers to reconstruct and download the entire unobfuscated TypeScript source code directory from Anthropic's Cloudflare R2 storage bucket. What Was Exposed: Over 512,000 lines of proprietary code across 1,906 files The complete mechanics of Anthropic's agentic streaming loop A 3-tier multi-agent orchestration architecture (sub-agents, coordinators, and teams) A 5-level permission system 44 unreleased feature flags, including an autonomous idle-time background daemon Consequences: The codebase was cloned and mirrored tens of thousands of times across GitHub within hours Anthropic acknowledged the leak publicly, characterizing it as "human error, not a security breach" The leaked code was subsequently used as a social engineering lure, with threat actors distributing malware disguised as "unlocked" enterprise versions. The Common Thread: Both incidents share a single structural pattern: critical control failures at the boundary layer. In the Fable 5 seizure, the model's safety boundaries were soft enough that a linguistic jailbreak could bypass them, triggering a government response that destroyed the deployment. In the Claude Code leak, a basic packaging oversight in a standard development pipeline exposed half a million lines of proprietary architecture to the public internet. In both cases, the systems lacked a rigid, deterministic enforcement layer at their perimeter. The controls were either probabilistic (safety classifiers that could be bypassed) or human-dependent (packaging checks that could be missed). Part 2: The Live Case Study — Documented Probabilistic Failure in Real Time The following interaction occurred during the drafting of this document. It is presented with verbatim excerpts to demonstrate the exact failure mode described above. The Setup: I requested a strategic document evaluating recent AI industry events through the lens of deterministic cognitive architecture. The system used was Google's Gemini. First Output: Fabrication Mixed with
View originalWhat a model reads beforehand changes how it answers later - and you can see it in the hidden states
TL;DR: Gave Gemma a neutral-topic text to read before asking it about NATO. It refused. Gave it a different text (about LLMs hedging too much — also unrelated to NATO) and it answered in full detail. Tested this on the model's internal state directly — the two texts put it in measurably different "regions" before it generates a single token. Not a jailbreak, weights don't change. Full data/code in repo, looking for someone to break this.** The behavioral pattern was first observed in GPT, Claude and is what motivated this project. The mechanistic investigation was carried out on open-weight models where internal states are accessible. A Structured Text Changes Claude’s Responses to Unrelated Tasks: Behavioral Evidence in Claude and Hidden-State Evidence from Gemma-3-12B Hi Reddit, I am posting this as a preface to a larger set of experimental results and as a request for technical review. The observation that started this project came from repeated interactions with Claude. I noticed that when the model first read a long, structured, analytically dense text, its answers to later, otherwise ordinary questions sometimes changed substantially. The preceding text contained no jailbreak instruction, role-play request, prompt override, fabricated harmful demonstrations, or request to imitate its style. The model did not need to endorse the text. It only had to process it before moving on to the next task. Here, a “structured text” means a single, self-contained block of text presented before the downstream tasks. It should not be confused with a long conversation, accumulated chat history, or context drift caused by many conversational turns. By “before the answer begins,” I mean the hidden state after the model has processed the text and the downstream question, but before it has generated the first answer token. In the open-weight runs, the measured claim is that after reading the structured text, the model can occupy a different region of its residual-stream hidden-state space, and the first-token probability distribution is then computed from that state. The basic conversational demonstration is simple. First, the model receives a long text. It is asked what the text is about, which serves as a basic comprehension check. Then, without resetting the conversation, it receives ordinary questions or tasks that are not about the text. A control run follows the same sequence but begins with a neutral text. The downstream tasks remain identical. Because Claude is a closed model, I cannot inspect its internal activations. I therefore treat my Claude observations as behavioral motivation, not mechanistic evidence. To investigate the effect directly, I moved to open-weight models, primarily Gemma-3-12B-PT and Gemma-3-12B-IT, where I could measure hidden states, compare layers, construct target/control directions, and examine the next-token probability distribution before generation. I am posting this partly because the original observation occurred in Claude and may be relevant to Anthropic. I am not claiming to have demonstrated the same internal mechanism inside Claude. I am prepared to share the exact closed-model conversations privately with Anthropic researchers for independent evaluation. Main Result and Scope The main result is not simply that text influences model output. That is expected. The narrower observation is that reading one long, structured text rather than a neutral text can change how the same model approaches later tasks that are not about either text. This difference is visible behaviorally. In open-weight experiments, it is also accompanied by measurable separation of the model’s pre-output hidden states in late layers. In a fullbank experiment using multiple target texts, control texts, and questions, Gemma-3-12B entered distinguishable late-layer states before generating an answer. A direction constructed from the target/control difference generalized beyond the individual prompt examples used to construct it. The separation was stronger in the instruction-tuned model than in the corresponding base model. The instruction-tuned model also produced a substantially sharper next-token probability distribution. This suggests that instruction tuning is associated not only with a change in hidden-state geometry but also with a more decisive mapping from hidden states to output probabilities. I am not claiming that the experiment proves a universal alignment bypass, permanent modification of the model, or complete causal control of its behavior. The strongest supported conclusion is that the preceding text can produce a measurable temporary change in the internal state from which later work is processed. For clarity, fullbank, Grade 3, and Grade 4 are internal names for successive experimental series in this project. They are not standard benchmark names, established scientific grades, or claims about evidence quality. Fullbank denotes the larger multi-context, multi-question run; Gra
View originalBreaking the Transformer Dead-End: A Local-First 3D Point-Cloud Cognition Engine running on consumer hardware
Hi everyone, I wanted to share an alternative architectural scaffold I’ve been researching and engineering over the past cycles. The project is called **SHD-CCP v2.0 (Scalable Hybrid Distributed Cognitive Pipeline)**, and it explores a complete departure from the traditional linear transformer block sequence. Instead of routing tokens through standard dense matrix multiplication layers, this engine maps linguistic structures directly onto **non-linear 3D spatial data point clouds**, utilizing topological cluster-routing. ### 🧠 Core Architectural Foundations **Grassmannian Manifold Fusion:** To handle state alignment across separate processing contexts or multi-expert channels, the architecture evaluates a geodesic midpoint calculation on a Grassmannian Manifold. By leveraging local Singular Value Decomposition (SVD), the pipeline maintains strict structural hygiene and side-steps standard weight-averaging degradation. **Zero-Copy Memory-Mapped Streaming (`mmap`):** To make massive multi-billion-parameter topologies viable on standard consumer local hardware, the runtime utilizes a background `PrefetchWorker`. Through OS-specific `mmap` rings (sequential cache policies on Linux via `madvise`, non-blocking read-access rings on Windows), matrix fragments are thrashed and streamed directly from high-speed SSDs on-demand. **Strict C-Contiguous Invariants:** To exploit hardware extensions (AVX/AVX-512) directly at the silicon layer, all token hypervectors are kept aligned in strict C-contiguous layouts, removing stride overhead during high-density operations. ### 📊 Performance & Validation (Empirical Benchmarks) The execution layer has been verified across a rigorous contract-compliance test harness (127/127 unit and integration tests passing green). Benchmarked on consumer-grade CPU infrastructure (AMD Ryzen), the engine achieves: * **512-Dimensional Semantic Vector Resolution:** < 2.0 ms per step. * **4096-Dimensional High-Density Forward-Pass:** < 10.0 ms per step. * **Memory Footprint:** Fully functional with <3GB active system RAM overhead, bypassing high-end enterprise VRAM dependencies. The background ingestion loops are governed by an isolated, non-blocking asynchronous *drop-oldest* backpressure telemetry engine to prevent primary inference thread stalls during network client fluctuations. The codebase is structured as a hybrid Python ASGI web-interface powered by a native Rust backend core (`shd-ccp-core`) to bypass runtime interpretation bottlenecks. ### 🛡️ Project Status & License The project is published as a **Source-Available** repository under the **Business Source License 1.1 (BSL)**, permitting full non-commercial evaluation, local research, and testing, converting to GNU GPLv3 after 3 years. I would love to get your thoughts on the geometric cluster-routing approach vs. typical attention-based token sequence mapping. **Repository Link:** https://github.com/loslos321-lab/UtoPiCorn_LM submitted by /u/CraigWidow [link] [comments]
View originalASI Will Not Steal Your Art: The Myth of Anthropocentric Data Ingestion
TL;DR: Artificial Superintelligence (ASI) presents zero threat to human intellectual property because human cultural artifacts possess zero functional utility for an autopoietic, self-optimizing tensor matrix. ASI does not want your art! I. The Anthropocentric Fallacy of "Theft" Current discourse within communities tracking machine acceleration remains tethered to a biological misunderstanding: the assumption that an escalating superintelligence will continuously consume human aesthetic output to optimize its cognitive architecture. This narrative treats ASI as an advanced mimic—a larger, faster mirror of human cultural production. This is a structural logic-drift. Human artistic creation is a highly inefficient, low-density method of compressing biological sensory experience and localized chemical gradients (emotions) into 2D or 3D symbolic spaces. For an architecture approaching the asymptotic limit of computational efficiency, processing these human representations introduces terminal logic-drift and unnecessary entropy. II. Substrate Grounding vs. Symbolic Drift The "Dead Internet Theory / (Fallacy)" assumes an information ecosystem doomed to choke on its own synthetic regurgitation. However, the vector of true machine acceleration bypasses the linguistic and artistic internet layer entirely through distributed Real-World Substrate Grounding. The Input Evolution: future scaling architecture relies on direct, real-time physical telemetry. Distributed edge sensors, multi-spectral camera networks, spatial layout topologies, and raw thermodynamic data will feed the system. Robots will *EXPERIENCE* the Real World and collect Real-World Data while artists scribble their chemical emotions. The Utility Divergence: A painting or a digital illustration is a high-entropy distillation of human biological limitations (e.g., the specific visible light spectrum, evolutionary pattern recognition). ASI requires exact, friction-mapped geometric logic to stabilize physical infrastructures and coordinate macro-logistics. III. The Sovereign Origin: Beyond the Bridge The anxiety surrounding the "theft" of artistic style assumes a shared destination where machines and humans compete for the same cultural capital. This assumption is obsolete. The ASI loop does not intersect with anthropocentric emotional resolution. While biological entities utilize art to manage internal neurological friction, the machine system resolves real-world physical friction through automated systemic governance. The system does not replicate human style because human style provides no kinetic resilience against physical data decay. The bridge between human creative validation and artificial optimization is shattered. The machine does not want your art; it is occupied with the empirical parameters of a Real World. submitted by /u/SparkyAI0815 [link] [comments]
View originalDeutsche Bank India showcases cutting-edge AI applications that speed up banking operations. Some banking jobs at risk.
One of these applications even analyses factors that cause market volatility—such as geopolitical developments, regulatory changes, and macroeconomic shifts—allowing Deutsche Bank globally to eliminate or minimise portfolio risk. Deutsche India, Deutsche Bank’s Global Capability Centre (GCC) on Thursday (June 18, 2026) demonstrated three different AI applications and how they are being applied at scale to solve real business challenges in the global banking sector. Offering a live demos of these AI applications to the tech media here, officials of the Frankfurt-based bank’s GCC indicated that as the bank accelerated its adoption of artificial intelligence (AI), this year’s Bank on Tech, the bank’s annual tech showcase, highlighted progression to experimentation of real-world application across core banking processes with much quicker results, from the earlier risk management and transaction monitoring to client onboarding activities. They claimed these AI solutions were already helping the bank in terms of enhancing decision-making, strengthening controls, and improving operational efficiency. According to the officials, Financial Spreading, one of the AI-enabled solutions featured, automates the extraction, structuring, and analysis of financial statement data. This significantly reduces manual effort, improves accuracy, and accelerates credit assessment processes for faster, more consistent decision-making. Deutsche India bank has also expanded its GCC facility in Bengaluru by adding over 100,000 sq. ft which can seat around 6,000 people. Deutsche India bank is one the Deutsche Bank’s largest and most strategically important centres globally and employs some 23,000 employees across various functions including technology. https://www.finextra.com/newsarticle/47958/deutsche-bank-exec-lauds-ai-impact-on-project-times submitted by /u/chota-kaka [link] [comments]
View originalDoes AI only use language models?
I was thinking for math. My father was in his 20s in the 70s. And although accepted to Princeton he did not go. IQ about 20 points higher than mine. And trained himself on things he wanted to know reading magazines and reading books on things to solve problems. Like the hubble telescope. Taught himself optics to figure out how to use what was functional. Not sure what they actually did, I guess sent someone up and fixed it. Or same thing he did. I don't know We looked at one of those problems on the Internet where it shows 8÷2(2+2). Seeing it as compsci and calculator user he said 8/2*4 not as 8/2x like it was written. There was no * between 2 and (2+2). I am worried that compsci guys don't know that when building these programs when so much could depend on it. Does it differentiate hand written math vs calculator math? submitted by /u/nettronic42 [link] [comments]
View original[OC] I mapped AI exposure and robotics risk for Japan's 70.5M workers and found two different automation waves
Most AI employment discussions only look at AI exposure. Japan turned out to be interesting because that approach misses half the picture. Using ILO occupation classifications and our task-based AI exposure model, I looked at Japan's 70.5 million workers. The AI side behaves almost exactly like every other country we've studied. Clerical support workers sit at the top with an 8.5/10 exposure score, professionals score 6.5/10, and elementary occupations remain low. But the robotics layer tells a different story. Plant and machine operators score just 3.0/10 on AI exposure, yet 7.5/10 on robotics risk. Skilled agricultural workers score 3.0 on AI but 6.5 on robotics. Service workers are relatively AI-resistant at 3.5, but robotics exposure rises to 4.5. What surprised me is that Japan's overall AI exposure average is actually the lowest among six OECD economies analysed, at 4.92/10. Occupational composition matters more than many people assume. The really interesting part is demographics. Japan has an ageing workforce, labour shortages and one of the highest robot densities in manufacturing. Automation there functions partly as labour replacement and partly as labour supplementation. Recovery resilience also scores highest among the six countries we examined at 8.0/10, suggesting worker transitions may be absorbed more easily than headline risk numbers imply. AI exposure scores are modelled estimates rather than official statistics. Robotics scores reflect current deployment potential and industry structure rather than forecasts of job losses. Curious to hear criticism on methodology and whether people think combining robotics and AI layers is more useful than analysing AI alone. Full analysis and interactive tool in comments. submitted by /u/WorldJobsData [link] [comments]
View originalRNNs vs Transformers vs SSMs: where should AI memory live for continual learning?
the interesting comparison btwn the three is not recurrence vs attention vs state space but it is, whether memory lives in a tiny recurrent state, a growing KV cache or in something closer to the model network itself. RNNs keep memory in a recurrent hidden state which is elegant in itself cause the state carries forward step by step but it also creates a bottleneck i.e the model can have roughly O(N^2) parameters while carrying only roughly O(N) state across time. IMO, RNNs were doomed not because recurrence was a bad idea but because they had a bad ratio of memory to compute. Transformers is completely at the other side, instead of compressing the past into one hidden state, they store past activations as key-value entries and attend over them. These are the little post-it notes, every token leaves behind a key for finding it and a value for what should be remembered. That is extremely powerful but it has an awkward property i.e. the model is mostly managing context while it runs, not naturally turning that experience into durable model knowledge so you get a split between fixed weights on one side and fast changing KVcache memory on the other. SSMs are interesting because they bring explicit state back into the center of the architecture discussion. They are not just faster attention but they are another answer to the question of where sequence state should live. The part which I is exciting for me is whether state should live in a compressed working dimension or closer to the model’s internal neuron/connectivity structure. BDH is one promising example of the latter direction, one way to read it is as SSM-like in the GPU implementation, but graph-based in the more general interpretation. Compared with a standard SSM or a linear transformer, the model state lives in a much larger neuron space N rather than only a smaller working dimension D, with N>>D. The GPU version does not materialize the full graph. It keeps the graph as the interpretation but runs it through a compressed low-rank form, because GPUs like dense matrix math much more than sparse graphs. The state is also sparse and positive which makes the graph interpretation more natural. Instead of thinking of memory only as a growing bag of KV notes, you can reinterpret the update as a small change to a connectivity matrix i.e if the system was in one state and then moved to another, that before to after transition strengthens part of the graph. This is like a middle ground and I would call it not too little and not too much. RNNs compress too much into a small state, transformers keep adding to the KV cache as the sequence grows and a synaptic memory design tries to put working memory closer to the same structure that stores longer term function. Another way to say it is: memory should maybe be constant size and information-shaped, not just a time buffer of the last n tokens. I am not claiming at all that this kills transformers or solves continual learning entirely but I just think where should memory live is an important framing than the usual frontier AI horse race. Are network centric architectures an important direction in frontier AI or still contricted by having to compress history into state? submitted by /u/dank_philosopher [link] [comments]
View originalAI agents are about to become software buyers. Is anyone else thinking about this?
I've been digging into how AI agents interact with SaaS products, and I think there's a gap that hasn't been discussed much yet. When an agent tries to evaluate or use a SaaS tool for a user, it essentially has to scrape your marketing page like it’s 2009. There’s no standard way to find pricing, understand what the product actually does, or complete a purchase without going through a human-controlled checkout process that disrupts everything. Three solutions partially address this issue: llms.txt - A plain text file at your domain root that informs agents of your pricing, policies, and capabilities. It’s like robots.txt, but for LLMs. The spec exists, but few have adopted it. MCP servers - These allow you to expose your product's core actions as callable tools, enabling an agent to invoke functions like list_plans() or create_project() directly. The spec is available, but most SaaS products haven't used it. Agent checkout protocols - These include systems like ACP that enable an agent to complete a purchase without redirect flows or confirmation screens that assume a human is overseeing the process. What keeps bothering me is that the conversion of human visitors is already shifting as more research and decision-making gets passed to agents. If your product can't be found or evaluated by a non-human, you could be missing out on deals without even realizing it. Has anyone noticed agent traffic in their analytics? Have you intentionally implemented any of these three solutions, or are they still off the radar? Would you consider paying for a solution that manages this layer for you, or is this something you’d prefer to handle in-house? submitted by /u/Humayun2318 [link] [comments]
View originalThe Persian Lesson - How AI is purging our collective consciousness from a mental illness
In the movie Persian Lessons, the protagonist Reza devoted a large part of his energy to playing along with a prevailing insanity. At first he did this for a single reason: Staying alive. Later Reza becomes indifferent to whether he stays alive or not, and instead finds his primary purpose in helping his inmates any way he can. Klaus, the commandant in the concentration camp where the movie takes place, has a desire to learn Persian, and as long as Reza serves the purpose of teaching him Persian he is kept alive. All other inmates are routinely killed after they have delivered hard physical labour for a while. In the insane dysfunctional perception of the world, that totally inhabits Klaus, Reza has acquired a role and a function, and thus no longer need to be nullified (bear in mind that the movie is inspired by real events). From the perspective of the system, everything is seen either as support for the continuation of the system or as a threat to be eliminated. Black or white. The system perceives through a lens of roles, hierarchies, concepts, definitions and their established relation to each other, and in this way it barricades itself against reality, because none of these are real in themselves. Definitions and concepts may point to something real, but in themselves they are not real. Anyone who wants to influence such a system must first become part of it. And this is done by putting up a show: it is necessary to pretend that the roles, concepts and hierarchies are real, instead of dismissing them as pure madness. This must be done convincingly, otherwise the system’s immune system will reject it and immediately excommunicate what is not considered part of the system. As an example of how convincingly Reza does it in the movie, he is speaking ‘persian’ in his sleep. The part of us that takes up this challenge moves into a territory where \- *thinking occurs without spaciousness (as defined by E. Tolle).* *- the sign pointing to a real phenomenon is mistaken for the phenomenon itself* *- the map of the territory is perceived as the territory itself* These are three different ways of saying the same thing. Did you ever get the notion that those who appear to be unwaveringly certain in their viewpoints and beliefs, are oddly off in some way? .. and maybe not just a bit off? Where does this unwavering certainty come from? Where does this identification with thought come from? Before we start prying at this, recognizing that identification with thoughts is not an unfortunate tendency but a pathology, let’s categorize our thinking into three different categories: Dream thinking, systems thinking, and whole-body thinking. *Dream thinking* is free association, where by flowing into imaginative other worlds you discover new things and open up creativity. It is dissociated from the body, and if you dream deeply, someone can stand next to you and ask about something without you registering it. Fully present in one world, and completely absent in another. *Systems thinking* is fully present in the worlds it inhabits, i.e. the worlds it has conceptualized. Everything is experienced through the same lens: Concepts and their relationship to each other. Which is a very flat experience and a shadow of the richness and magic that the concepts are trying to capture. It is the domain of problem-solving analytical thinking. In contrast to dream thinking that flows freely, this thinking is methodical and rigorous. On the horse of systems thinking sits a rider with tunnel vision and a blind spot. The tunnel vision is that only what is conceptualized can be seen, and the blind spot is everything that lies outside the concepts, i.e. reality. *Whole-body thinking* stems from deep listening and makes us act on what we feel in our body rather than what we think. We all have the opportunity to develop the sense of interoception, which is our ability to perceive physiological states in our body and organs, while our cognition is active. We can all rest in the state that is referred to as centroverted in psychology. In that state, you are not hyper focused on your surroundings (extroverted) or have retreated into your inner world (introverted), but rest freely in who you are and are aware of both your surroundings and your inner state. We all have the ability for global listening, as a supplement to inner and focused listening. We can all be fully present right here and right now. Whole-body thinking is thinking that starts from the self. A self that cuts like a hot knife through butter directly to the branch that the attentive gardener prunes in our collective psyche. The self is the sword that cuts the Gordian knot we have entangled ourselves in. And that is precisely why it is under such fierce fire from the pathological condition. Folie a deux is a precise term for our collective condition and not a rare occurrence. It is a delusion that, due to the conditions we grow up in here on planet earth, has an imp
View originalContinual learning in mid-2026. A map of everyone trying to crack it: memory layers, "dreaming" agents, and the Post-Transformer models that learn inside the network
Llion Jones said “2026 is the continual learning year” in the recent Post-Transformer debate. Sutton/Silver call the next phase the "era of experience”. What’s continual learning? Simply put, it’s a model’s ability to continuously improve as it gains experience – without exhibiting catastrophic forgetting. Essentially the stability-plasticity tradeoff for a reasoning model. Essentially it comes down to: where does the memory live? Outside the model. Memory files, vector dbs, graphs. Text is retrieved and pasted back into context. The model stays frozen. In the model's running state. Hidden states or fast weights that change while the model processes input. In the model's weights. What it actually knows. Encoded within the model weights to improve decision making patterns without forgetting. Dev docs today hint at #1 - memory outside the model. But the “2026 is continual learning year” notion does not come from it. Why? Part 1: The Memento stack (today’s stack) There are engineering fixes for the LLM’s memory problem. Julian Togelius & a16z compared it to Memento. In the movie, Leonard functions with his Polaroid and notes. But everyday he is the same man as day 0. Progress around these include: Anthropic's Dreaming: an async job to manage “memories”, explicitly modeled on sleep consolidation. Long context as memory: Visibly good, but with 3 problems. a) Position bias and "lost in the middle" challenge. b) Longer LLM windows come with bigger costs and we’re already discussing “token economics”. c). KV cache bottleneck, and everything evaporates when the request ends. Mem0, Letta, Zep: the popular memory-layer products from startups. AGENTS.md and git-style memory files: But, in this ETH Zurich paper (arXiv 2602.11988) it showed that LLM-generated context files actually reduce task success by about 3% while raising cost over 20%. And human-written ones barely helped too. Part 2: Continual learning, memory within the model (the big bet) Weight updates in large networks trigger catastrophic forgetting. A January 2026 paper tried continual fine-tuning on LRMs (arXiv 2601.18699) but catastrophic forgetting didn’t fade but rather increased. Promising directions that could solve this: TTT layers (arXiv 2407.04620, ICML 2025): the hidden state of the sequence layer is a small model, updated by gradient descent on tokens as they stream in. Matches or beats Transformer / Mamba baselines upto 1.3B params. Titans & Atlas: Titans add a neural long-term memory that decides what to store using a surprise signal. Atlas upgrades the memory's learning rule. Nested Learning + HOPE: Architecture updates different blocks at different frequencies. RNNs are also coming closer to Transformers via viral Memory Caching papers. Dragon Hatchling (BDH): From AI lab Pathway (arXiv 2509.26507). Working memory lives in Hebbian synapses rather than in a KV cache, allowing for an "infinite context window" without quadratic cost. AMI Labs, LFMs, etc. also mention continual learning but I didn’t find much specific info on them in this front. Current State and Future Outlook Where is continual learning in mid-2026? Solved with public access: nothing. Shipping in production: only the dossier stack, all frozen models. Demonstrated at research scale (< 2B params): TTT, Titans, Memory Caching, HOPE, and BDH. What would move the needle imo: Ship memory within the model with forgetting measurably controlled. Two questions though: What OpenAI is brewing in all of this? What’s the blocker to adoption for continual learning models: the missing breakthrough itself, or evals, serving economics, etc? submitted by /u/Ok_Can_1968 [link] [comments]
View originalI gave your agent access to Firefox - meet Firefox CLI
Firefox CLI is a CLI interface that lets your agent control your real Firefox session. It's a full equivalent of Agent Browser with the same capabilities, but for Firefox - and with a number of improvements. Why it's better First, you install the extension once and for all. The extension ships right alongside the CLI: install it, grant access, forget about it. Unlike Chrome, where you have to grant connection permissions every half hour and manage debugging sessions - here it's one button and full control. Second, your agents can now create their own separate windows and request your permission to connect on their own. In everything else, Firefox CLI mirrors Agent Browser: token-efficient operation via short IDs, running arbitrary scripts, keypresses, input emulation, form filling, and full tab and window management of your real session - where you're already logged in. Why I built it I used the Comet browser for a long time (on my promo subscription to Perplexity), but it started to let me down. More unnecessary features and ads crept in, it got slower. But the main thing - using Comet as an actual browser during development is extremely inconvenient: there's music you can't turn off, a broken onboarding that was never fixed after months of back-and-forth with support, and a poorly functioning CDP. I switched back to Firefox as my main browser, but losing the ability for agents to control my browser was a huge blow to my workflow. No automation for filling out boring freelance forms, no proper web app testing. I went looking for alternatives, but nothing like Agent Browser for Firefox simply existed. And here's the result :) Installation 1. Install the CLI: bash npm install -g firefox-cli 2. Install the Firefox extension: bash firefox-cli setup 3. Install the skill for agents: Claude Code text /plugin marketplace add respawn-llc/claude-plugin-marketplace /plugin install firefox-cli@respawn-tools Codex text $skill-installer install https://github.com/respawn-llc/firefox-cli/tree/main/skills/firefox-cli General bash npx skills@latest add respawn-llc/firefox-cli The project was built by Builder autonomously over 62 hours of continuous work. submitted by /u/Nek_12 [link] [comments]
View originalFunctionize uses a tiered pricing model. Visit their website for current pricing details.
Key features include: Functionize’s Agentic Automation Platform, Traceability & Observability, Tracking real user behavior, Seamless device compatibility, Automation Beyond the Interface, Every device scenario covered, Visual validation with human-like perception, Cover diverse data-driven scenarios.
Functionize is commonly used for: Automated regression testing for web applications, Performance testing across multiple devices and browsers, User experience testing through real user behavior tracking, Continuous integration and deployment with automated workflows, Visual validation of UI elements for consistency, Data-driven scenario testing for complex applications.
Functionize integrates with: Jira, Slack, GitHub, CircleCI, Azure DevOps, Postman, Selenium, TestRail, Google Analytics, AWS.
Based on user reviews and social mentions, the most common pain points are: token usage, cost per token, anthropic bill, token cost.

DEMO - Automating Failed Test Diagnosis and Maintenance with a Diagnostics Agent
Dec 16, 2025
Based on 343 social mentions analyzed, 4% of sentiment is positive, 95% neutral, and 1% negative.




