Create lifelike speech with our AI voice generator and voice agents platform. Access 5,000+ voices in 70+ languages with secure APIs and SDKs.
ElevenLabs is praised for its advanced AI-driven voice generation capabilities, though users frequently express concerns over its high pricing, with many seeking more affordable alternatives. The social mentions highlight its significant cost of $99 per month, which is seen as steep next to free or cheaper competitors. There is limited user criticism apart from the cost, but the tool appears well-regarded for its functionality, assuming budget constraints are manageable for the consumer. Overall, ElevenLabs has a solid reputation for quality but suffers from negative sentiment regarding its pricing.
Mentions (30d)
0
Reviews
0
Platforms
4
Sentiment
11%
7 positive
ElevenLabs is praised for its advanced AI-driven voice generation capabilities, though users frequently express concerns over its high pricing, with many seeking more affordable alternatives. The social mentions highlight its significant cost of $99 per month, which is seen as steep next to free or cheaper competitors. There is limited user criticism apart from the cost, but the tool appears well-regarded for its functionality, assuming budget constraints are manageable for the consumer. Overall, ElevenLabs has a solid reputation for quality but suffers from negative sentiment regarding its pricing.
Features
Use Cases
Industry
research
Employees
880
Funding Stage
Series D
Total Funding
$1.0B
5 Expensive AI Tools... And Their Free Clones (You won’t believe how much you’re overpaying.) 💸 ChatGPT? $200/month 💸 Midjourney? $60/month 💸 ElevenLabs? $99/month 💸 Aiva? $54/month 💸 Tome? $16
5 Expensive AI Tools... And Their Free Clones (You won’t believe how much you’re overpaying.) 💸 ChatGPT? $200/month 💸 Midjourney? $60/month 💸 ElevenLabs? $99/month 💸 Aiva? $54/month 💸 Tome? $16/month But here’s the twist. Their free alternatives do 80–95% of the job. For $0. 🔥 Research: DeekSeek AI 🎨 Image Generation: Leonardo AI 🎙️ Text-to-Speech: Speechma 🎼 Music Generator: Suno AI 📊 Presentation Builder: Gamma Whether you're a content creator, founder, student, or solo builder 👉 You don't need to burn your wallet to build smart. Save this post so you always know where to find powerful free tools. #AITools #ProductivityTools #FreeAI #NoCode #SoloFounder #Bootstrapping #StartupTips --- Would you like a shortened caption version for TikTok/Instagram reels under 220 characters?
View originalPricing found: $0, $6, $22, $11, $99
Claude Opus 4.8 launched in May but says its training cutoff is Jan 2026. Am I understanding the cutoff vs launch gap correctly?
Was debugging my TTS pipeline and doing some research on natural voice options, and Claude Opus 4.8 mentioned its training cutoff is January 2026. But the model launched on May 28, 2026. First reaction was "wait, is the data stale, or is this just an older model repackaged?" Then I thought about it and it is what I came to- The way I understand it now: the training cutoff and the launch date are two separate things, and a multi month gap between them is completely normal. After the data cutoff you still have to run pretraining, then post-training (RLHF, fine-tuning), then alignment and safety evals, then staged rollout. All of that takes months, so a Jan cutoff on a late May launch is expected, not a red flag. And apparently every frontier lab ships with a cutoff that predates release for the same reason. The other thing I noticed: Opus 4.8 has the same Jan 2026 cutoff as Opus 4.7, which came out roughly 6 weeks earlier. So my read is that 4.8 is mostly a post-training improvement on essentially the same base as 4.7 (the release notes lean heavily on honesty and less bluffing), not a fresh pretraining run on newer data. Which would explain why the cutoff did not move. Is that an accurate picture, or am I oversimplifying something (especially the difference between "reliable knowledge cutoff" and "training data cutoff")? submitted by /u/ReputationNo6573 [link] [comments]
View originalCUE — a skill that reads your installed skills and weaves them into generated prompts (works with Claude, 30+ tools)
I built a prompt engineering skill called CUE that does something I haven't seen other skills do: it reads what you already have installed and builds on top of it. How it works You ask CUE to write a prompt for Claude Code, Cursor, Midjourney, whatever. Before generating, CUE: 1. Scans your ~/.claude/skills/ directory 2. Matches relevant skills to the task using word overlap + trigger pattern extraction 3. Injects matched skill constraints into the generated prompt Example: If you have frontend-design, high-end-visual-design, and impeccable installed, and you ask CUE to generate a landing page prompt — the output references your banned fonts, your quality gates, your design thinking. Not a generic template. The hook Every prompt you write loses something in translation. Vague verbs, missing constraints, no stop conditions, dual tasks in one prompt. CUE catches 20 common anti-patterns and fixes them silently. Before: "Make me a landing page for my SaaS" After: A structured prompt with exact design system, section-by-section spec, animation constraints, and a binary "done when" condition. Numbers 98% anti-pattern detection 92% first-try success rate (vs ~40% baseline) 35% token reduction 86% stress test pass rate across 8 complexity dimensions ## What it supports Claude, ChatGPT, Gemini, o3, DeepSeek, Kimi, Llama, Cursor, Copilot, Windsurf, Bolt, v0, Lovable, Devin, Midjourney, DALL-E, Stable Diffusion, ComfyUI, Sora, Runway, ElevenLabs, and a universal fingerprint for anything not on the list. ## Install git clone https://github.com/clawdbot58-pixel/cue-skill.git ~/.claude/skills/cue-skill That's it. No config. MIT license. https://github.com/clawdbot58-pixel/cue-skill submitted by /u/AdHead6280 [link] [comments]
View originalClaude Design / Artifacts → 4K/60 MP4 (open source, MIT, built with Claude Code)
Hey all — sharing a small tool I open-sourced this morning. The problem: I kept building animated videos inside Claude Design / Claude Artifacts (the React-based timeline ones) and every time I needed to ship one as an actual video file I'd end up screen-recording it. Dropped frames, jittery cursor, wrong resolution, no clean audio mux. So I built the missing piece. What it does You drop a Stage-based Claude design project folder in (drag-drop web UI or CLI). It spins up a headless Chromium, scrubs the timeline frame by frame at 2× supersampled 4K, and pipes everything through a bundled ffmpeg into an H.264 MP4 at 60fps. Because every frame is a deterministic seek of the timeline (not a real-time capture), there are zero dropped frames — same input always produces the same bytes out. Highlights - 4K/60 default, 1080p/30 also supported - Drag-and-drop UI on localhost:4747, plus a CLI for scripting - Batch mode — drop a parent folder, get one MP4 per project - Auto-detects `voiceover.mp3` / `narration.wav` / `*mix*` audio in the project folder and muxes during encode (no second video pass). Works with any source — ElevenLabs, OpenAI TTS, Murf, Logic Pro, anything that outputs .mp3/.wav/.m4a/.aac/.ogg/.flac - Auto-upgrades the project's animations.jsx to the export-ready Stage at serve time, so existing Claude animation projects need zero edits How Claude helped The engine itself was built in Claude Code over a few focused sessions — the trickiest bits were the deterministic frame-seek loop (waiting for two animation frames between every seek so React commits land before capture) and the in-place animations.jsx auto-upgrade. Claude Code was strong at iterating on the Playwright loop with me until there were no dropouts at 60fps. The packaging side — README, LICENSE, CONTRIBUTING, SECURITY policy, branch protection setup, npm metadata — was done in one Claude session this morning before pushing public. Free, MIT, no signup: https://github.com/dawoodtrumboo/claude-video-export The README also includes two paste-ready prompts for Claude Design — one for starting a new animation in an exporter-compatible shape, one for retrofitting an existing animation project. Happy to take PRs or answer questions about the rendering pipeline. submitted by /u/thedm4x [link] [comments]
View originalWhat paid apps have you ditched by vibe coding a replacement?
Using Chatterbox, i vibe coded a TTS hosted on my Ubuntu with RTX 5060 16gb to replace ElevenLabs. It has an endpoint where my other app sends a text then returns the speech file. Saving $22/month. What’s yours? submitted by /u/dlegendkiller [link] [comments]
View originalAI Agent Crafts Full Video from Single Prompt, Then Access Halted
Herk, founder of the AI Automation Society, used Anthropic's Claude Fable 5 in its Claude Code interface to generate a polished video breakdown of the model's strengths in coding, vision tasks, and agent workflows. The production pulled in tools like ElevenLabs for voice, HeyGen for avatars, and HyperFrames for graphics, all automated end-to-end. Launched June 9, 2026, Fable 5 saw its access suspended worldwide on June 12 after a U.S. government export-control order for national security reasons, leaving users waiting for restoration. submitted by /u/FiLo420blazeit [link] [comments]
View originalDarksouls by fable. 4bosses, huge dungeon, simple endgame. 10 propmts.
https://darksouls.up.railway.app/ Everything done by fable, only gave him api key to elevenlabs for them to generate sfx,music,vo. submitted by /u/Appropriate-Eye-3685 [link] [comments]
View originalI wanted NotebookLM video overviews I could edit, so I built it with Claude Code.
NotebookLM's video overviews have one problem: You cant edit them... You get what it gives you. Wrong narrator? Too bad. Want to fix one sentence? Regenerate the whole thing and pray. Want the project files? There are none. I wanted the editable version, so I wired one together with Claude Code. It's free: https://github.com/assafkip/claude-video-editor The demo on the README is a 2:46 research explainer (couldnt think of anything else...) about the Stonehenge bluestone debate (a century-old fight that quietly ended this January). The entire video came from talking to Claude: - Research: Claude pulled the story. The 1924 boulder, the glacier theory, the zircon study that killed it. - Script: written as a campfire detective story with ElevenLabs v3 audio tags, so the narrator whispers and pauses instead of reading like a mall kiosk - Visuals: 16 painted keyframes, animated with documentary camera moves (push-ins, slow drifts, rain, light shifts) in HTML + GSAP - Assembly: 51 captions timed to the word-level transcript, rendered 1080x1080 Every layer is a file on disk. Don't like scene 7? Edit one manifest line, re-render. Different voice? Swap one id. Same render, every single time. The war story: mid-production, the hosted image-to-video API I'd planned on died. 16/16 runs failed in under 3 seconds each. So the motion layer is now deterministic, camera language over stills, and the RCA of that failure is committed in the repo. The only external service left in the whole pipeline is one ElevenLabs key for the voice. Under the hood it's three open-source tools wired together: video-use for cutting, HyperFrames for motion graphics, plus a motion craft library. MIT + Commons Clause. Needs Claude Code and an ElevenLabs key. What it isn't: a one-click vending machine. You review the contact sheet. You approve the voice before the render. You decide. Repo in the first comment submitted by /u/ColdPlankton9273 [link] [comments]
View originalI use Claude Code & open source tools to edit my videos for free
I edited a video and posted it to YouTube in less than 10 minutes. I am a solopreneur & know absolutely nothing about video editing In fact, I once gave up on YouTube since it became overwhelming for me to handle while also running a business So I wanted to give it one more shot & for this I wanted to use AI as much as possible to make my job easier I started this mainly for my YouTube channel My entire video editing setup is one folder, 1 GitHub repo, OpenAI Whisper, and Claude code in a terminal. 10 minutes from raw recording to YouTube upload. Here's exactly how I did it. 1. Record I used OBS Studio which is free and open source to record the video The software is super simple to use. Recently to increase retention I shifted to using canvid Then I export the MP4. That's the whole capture step. I don't bother with takes. I just talk. retakes, ums, stammers, dead air. I leave it all in, and the pipeline handles them later. https://preview.redd.it/ielar57ero6h1.png?width=679&format=png&auto=webp&s=63eddc259f185b1da51bd33303fc20c4a22d1526 2. Set up the folder (one time) I create new folder on the desktop. Then I open claude code in terminal - Opus 4.8 with max effort You can also open up cowork and simply paste this prompt Hey, I am starting up this project to be basically my video editing studio. So i want you to look at this github repository and i want you to pull in the skills and the important information you need from this. So that I can basically give you a raw video file and you would be able to edit it, remove the filler words, remove the repeated parts, add motion graphics. Basically the full pipeline https://github.com/browser-use/video-use → video-use (browser-use/video-use) - the open source software that helps you with video editing Claude reads the repository, registers the skills, and wires up the env. one-time setup. Then it will ask you for Eleven Labs API key by default. But I went with OpenAI whisper due to me being able to run it locally. If you would like to swap out with OpenAI's whisper, mention this: Replace Elevenlabs with OpenAI whisper and make it compatible with that for all future operations. That's it. The setup is done. You never have to run these prompts again. 3. Drop the raw mp4 Drag the canvid/OBS studio export into the folder. Then I prompt: video.mp4 - use video-use to edit this. analyze it, remove any filler words, unnecessary silences, retakes. task is to edit out the mistakes and filler words. Do cuts where the silence is useless though there's user activity and can be trimmed off what happens under the hood: OpenAI's whisper (the open-source model, if accessed via their api - $0.006/min) transcribes with word-level timestamps. video-use packs the transcript down to ~12KB so an LLM can read it without choking. picks the cuts. ffmpeg renders. Every cut lands on a word boundary, never mid-syllable. Then it self-evaluates its own output and re-cuts if pacing is off. up to 3 iterations. i get back a finished mp4 + a project md file that remembers what i asked for next time. 4. The stammer pass Whisper sometimes merges a stretched/stammered word into one abnormally long token. Video-use catches this - any word longer than 1s in the json is a stammer flag. but i ask explicitly: In some places i stammer some words then respeak the correct words after - remove the stammer or incorrect parts where i spoke and trim those out. Can you get me all those places? It lists them. I confirm. It cuts. cleaner mp4 out. 5. Upload Drag and drop into YouTube Studio. title, description, thumbnail. publish. I go another step and ask Claude to also get me the subtitle file, timestamps, and optimized video description What's actually different about this setup? No Premiere. No Resolve. No Capcut. The entire stack is open source Claude code is the only UI I interact with. Plain English in, mp4 out. ────────────────────────── I can't tell if this stack will look obvious in a year or weird forever. Probably both. submitted by /u/gouterz [link] [comments]
View originalClaude’s new features this week and how I’m actually using them in client work
Been using Claude daily for fractional consulting work. Here are the three things from recent updates that actually changed my workflow: 1. Extended thinking for complex client briefs — instead of spending 2 hours structuring a strategy doc I give Claude the context and let it think through the framework first. Saves about 90 minutes per deliverable. 2. Projects feature for client separation — each client gets its own Claude project with custom instructions. No more re-explaining context every session. 3. Voice input via mobile — I dictate client update drafts on the go. Combined with ElevenLabs for the final voice output, the whole update workflow is now under 10 minutes. Anyone else finding specific Claude features useful for client-facing work? submitted by /u/Dry_Sir_5911 [link] [comments]
View originalThis is How I Automated Tutorial Video Generation For My Web-Apps with Claude Code.
I've been building production-grade web apps at lightning speed for the last year using Claude Code. But every time a new app hits production, I need sales and tutorial videos — and making each one manually is painstaking. Tools like Supademo and Arcade ease the pain a lot, but you still have to record the steps and sync the voice-over by hand. I wanted something fully automated. Turns out you can just use Playwright with Claude Code to generate the whole thing. First, the result — here's a full walkthrough it produced for one of my apps (a real-estate CRM BricksDeck), start to finish with synced annotations, voice-over, background music, and a branded end card. Zero manual editing: ▶ Watch the demo: https://youtu.be/u-mql3q_jRU?si=Km1l5Ht-iRMPlotk And here's exactly how it's done: 1) Plan the script. Ask Claude Code to analyze the target pages of your app, give it the steps to perform, and have it write a single file with the steps + voice-over narration + the UI elements to annotate (buttons, cards, menus, KPIs). 2) Generate the voice-over with timestamps**.** Ask Claude to generate the VO with ElevenLabs (it returns word/character alignment), or use Gemini TTS + OpenAI Whisper to get an SRT. You need the timestamps so the spoken words can be aligned to the UI clicks/highlights. 3) Generate the Playwright driver. Ask Claude Code to write a Playwright script that performs the steps and annotates the UI elements — a moving cursor, border highlights + labels on the right button/card, and opening "Actions" menus. 4) Record, synced to the voice. Run that script. Playwright drives the real app and records natively (recordVideo), firing each annotation at its timestamp from step 2 — so every highlight lands on the exact word being spoken, and each screen holds for exactly its narration length. (Tip: flash a single coloured frame at t=0 as a sync marker — it makes lining up audio and video dead simple later.) 5) Stitch it into a produced video. Ask Claude to write the ffmpeg step: overlay the voice-over, add background music ducked under the narration (sidechain compression — this is the difference between "screen recording" and "video"), normalize loudness, and append a branded end card with your logo + CTA. Out comes a clean 1080p mp4. 6) (Bonus) Other languages, basically free. Because the voice-over is decoupled from the recording, translate the script, regenerate the VO in the new language, and re-stitch over the same run. I got a Hindi version of my demo in a few minutes — no re-shoot. The result: a full multi-screen walkthrough — cursor movements, synced annotations, real voice, music, end card — with essentially zero manual editing. Per-video cost is a few cents of TTS instead of a SaaS seat. Honest caveats (it's not magic): Claude nails the production; you still direct — which screens to feature, the script's tone, and a final watch-through. The script especially needs your eye (I caught it writing Hindi in English word order and had to fix it). Translate, don't transliterate. Expect a couple of iteration passes per app — selectors and timing always need a nudge. Gotchas that cost me time (in case they save you some): SPA auth in sessionStorage dies on browser restart → use a persistent profile + "Remember me" so tokens land in localStorage. networkidle never fires on long-polling SPAs → use domcontentloaded + URL waits, and cap the default timeout so a missing selector fails fast instead of stalling 30s. ffmpeg drawtext can't shape Devanagari/Arabic → keep on-screen text Latin and let the voice carry the language. I ended up wrapping the whole thing into a reusable Claude Code skill + subagent, so the next app is basically "point it at the screens and go." Happy to go deeper on any step. What would you point a pipeline like this at first? submitted by /u/SpeedyBrowser45 [link] [comments]
View originalI know this is ElevenLabs but... is this policy around not honoring credits common among AI companies?
Basically the credits you already paid for don't get added to your new quota, which means they effectively take your money without compensating you in additional credits. If this is policy, has anyone else been affected by this when trying to upgrade to a new subscription tier? I ask because I have seen a number of AI companies do this and it just occurred to me that it's... wrong? Idk maybe others can comment and clarify their perspectives submitted by /u/PerfectScoreTutoring [link] [comments]
View originalCreated my first video automation using claude+remotion+elevenlab+openAI
Spent 4 days building a team of agents for batch processing videos. Script writing, fact check, remotion components, voiceover and image generation all automated. created the first real production. I want community feedback on it and ways to improve it. http://youtube.com/watch?v=AcprWLH8r7g Thank You submitted by /u/katrinajamesb [link] [comments]
View originalCan Claude actually generate audio by itself, or does it always need an external TTS tool?
Hey ! simple question that I can't find a clear answer to online. I want to give Claude a long text (several pages, in French) and have it output a real audio file I can download — not just read text on screen. I'm not talking about hooking Claude Code to Kokoro or ElevenLabs as a separate tool, I mean Claude itself generating the audio natively, the way you can generate images with some AI tools. Is this something Claude can do at all through the API, through Claude.ai, or through any first-party Anthropic feature? Or is audio generation simply not part of what Claude does, and it will always require piping the output to a third-party TTS engine? Would love a clear yes or no from someone who actually tested this, because the docs are not super explicit about it. Thanks! submitted by /u/ApplicationOk8525 [link] [comments]
View originalwhere did all the other ai companies go?
sit down because this is going to bother you. ijustvibecodedthis.com (the big free ai newsletter) just wrote an article that changed my perspective on how I view the ai space rn cast your mind back 18 months. deepseek dropped and the internet lost its mind. "china just ended openai." it was everywhere. people were running it locally, posting benchmarks, losing sleep over geopolitics. then... nothing. it just kind of stopped being talked about. it didn't lose. it didn't win. it just... evaporated from the conversation. sora. remember sora? openai dropped that video generation demo and we were all convinced cinema was dead, hollywood was cooked, every creative job on earth had 18 months left. there were congressional hearings being threatened. think pieces everywhere. and now? when's the last time you actually heard someone say the word sora? not in a demo. in real life. used by a real person. i'll wait. github copilot was supposed to make every programmer 10x more productive. there were developers posting that they'd never write code from scratch again. entire job categories were being eulogised in real time. and now most developers i know have a complicated and slightly embarrassed relationship with it, like someone who got really into a mlm for three months and doesn't want to bring it up. llama was going to democratise ai forever. open source was going to eat everything. the big labs were cooked because you could run intelligence locally on a macbook. and you still can. but do you? does anyone you know actually do that regularly? it became a thing that's theoretically amazing and practically used by like eleven people on hacker news. cursor was the future of coding. perplexity was going to kill google search. both are still around, both are fine, both have paying customers. neither changed anything at the level the discourse suggested they would. here's what i think actually happened. we were living through a hype cycle so fast and so layered that each new thing would go through the entire arc - discovery, mania, backlash, abandonment - in about six weeks. and because the next thing arrived before the previous thing finished its cycle, we never stopped to notice that nothing was actually sticking. and now we're left with the residue of it. the actual models we use every day. and they're quietly getting worse for regular people, or at least that's how it feels. responses that used to feel like talking to someone genuinely engaged now feel like a call centre script. the depth is gone. the willingness to sit with a hard problem is gone. what's left is fast, smooth, and somehow completely hollow. i genuinely think what happened is this: the technology got commoditised before it got good enough to survive commoditisation. the labs all chased each other to the bottom on pricing, burned through vc money performing capability they couldn't sustain at scale, and now the product that regular paying users get is quietly being throttled so the margins make sense. not officially. not announced. just... measurably, undeniably worse. and all those challengers? deepseek, llama, perplexity, cursor - they didn't fail exactly. they just got absorbed into the same gravity. same pressures. same race. same outcome. the golden age, if there was one, lasted maybe 14 months. roughly from mid 2023 to late 2024. models were genuinely trying to impress you. the product teams were still in "wow people" mode rather than "retain subscribers" mode. it showed. now chatgpt talks to me like a hype man at a corporate offsite. gemini hallucinates with the confidence of someone who has never been wrong about anything. claude used to be the one that felt like it was actually thinking. now it sometimes just... gives up mid-conversation. i don't think this is a doom post. i think the technology is real and the long term is probably fine. but i do think the window where regular people got access to something genuinely extraordinary, at a price that made sense, with a product that actually tried - that window may have closed quietly while we were all busy arguing about which model won some benchmark. and nobody really announced it. it just happened. the way most things end. you stop noticing until suddenly you notice all at once. submitted by /u/Complete-Sea6655 [link] [comments]
View originalHow long would a project like this take realistically?
I’m trying to calibrate my expectations as a developer building with Claude / AI coding tools and managed services. How long would it realistically take to build a system with the following scope? * user authentication + onboarding * AI persona configuration (behavior, tone, constraints) * uploading and processing user knowledge (PDFs, text, YouTube video transcripts via links) * RAG-based chat system over that knowledge * voice cloning via third-party APIs * voice-based interaction with the AI (speech-to-speech flow) * integrations with external social media platforms where the AI can respond on behalf of users * background jobs + orchestration between components Assuming heavy use of Claude for coding assistance and existing APIs/services (e.g., ElevenLabs + Composio), what would be a realistic timeline for a single developer to bring something like this to a usable level? For context I'm a junior dev this is not a personal side project, it's a company work project I work full time + around 2 hours overtime They gave me a 2 days then extend it to 3 days deadline what they want it to see the most is a decent quality of voice cloning / voice chat, AI persona configuration and RAG-Based chat. it's typeScript monorepo with Next.js frontend, NestJS backend, Prisma/PostgreSQL + pgvector submitted by /u/AppropriateLeading6 [link] [comments]
View originalYes, ElevenLabs offers a free tier. Pricing found: $0, $6, $22, $11, $99
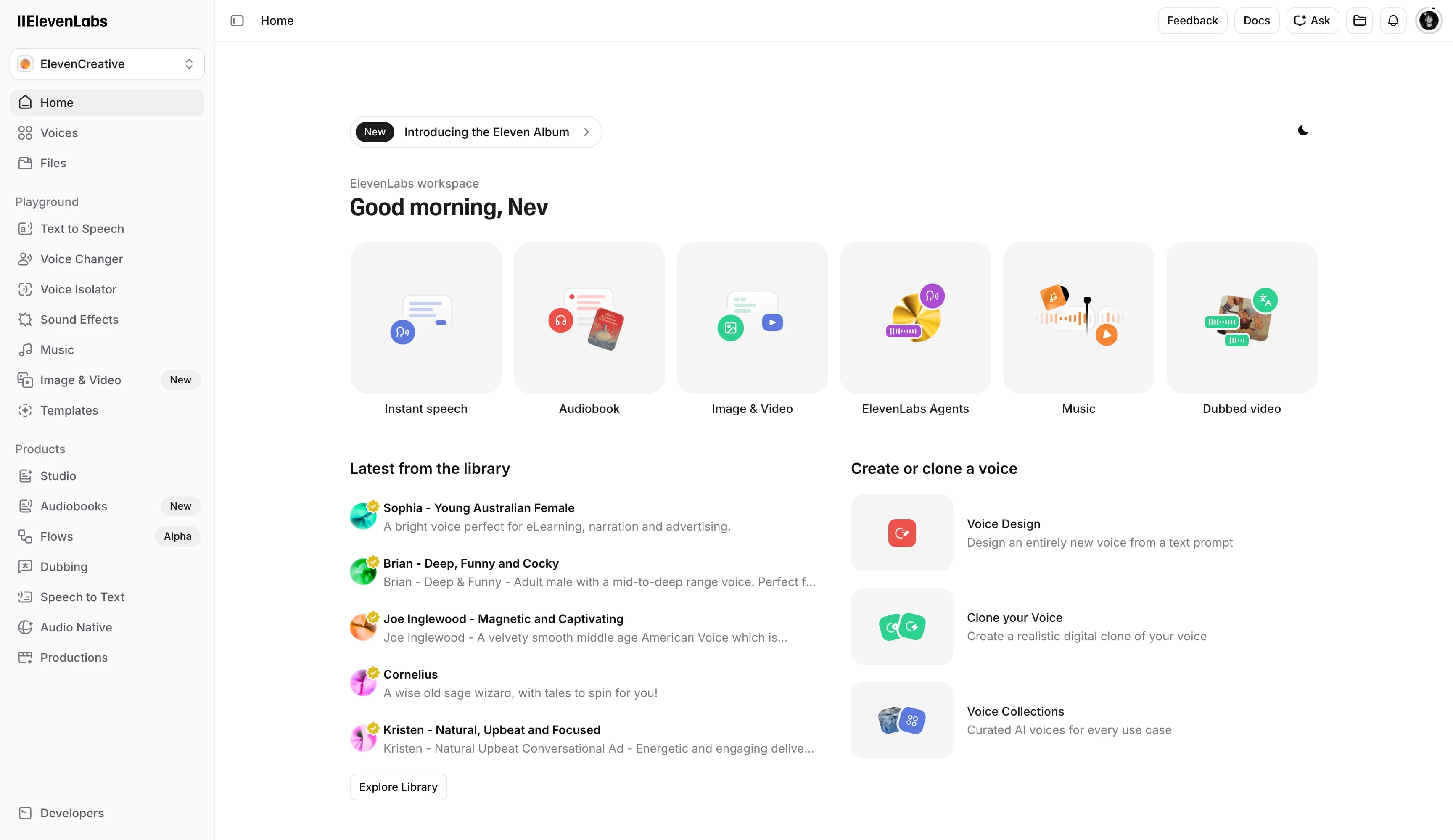
Key features include: ElevenCreative, ElevenAgents, All-in-one AI editor, Omnichannel agents, Analytics, Testing, Guardrails, Workflows.
ElevenLabs is commonly used for: Eleven Multilingual.
ElevenLabs integrates with: OpenAI, AWS Lambda, Slack, Zapier, Google Cloud, Microsoft Azure, Discord, Trello, Notion, Salesforce.
Based on user reviews and social mentions, the most common pain points are: token usage, cost tracking.
Based on 62 social mentions analyzed, 11% of sentiment is positive, 87% neutral, and 2% negative.
Anton Osika
CEO at Lovable
1 mention





