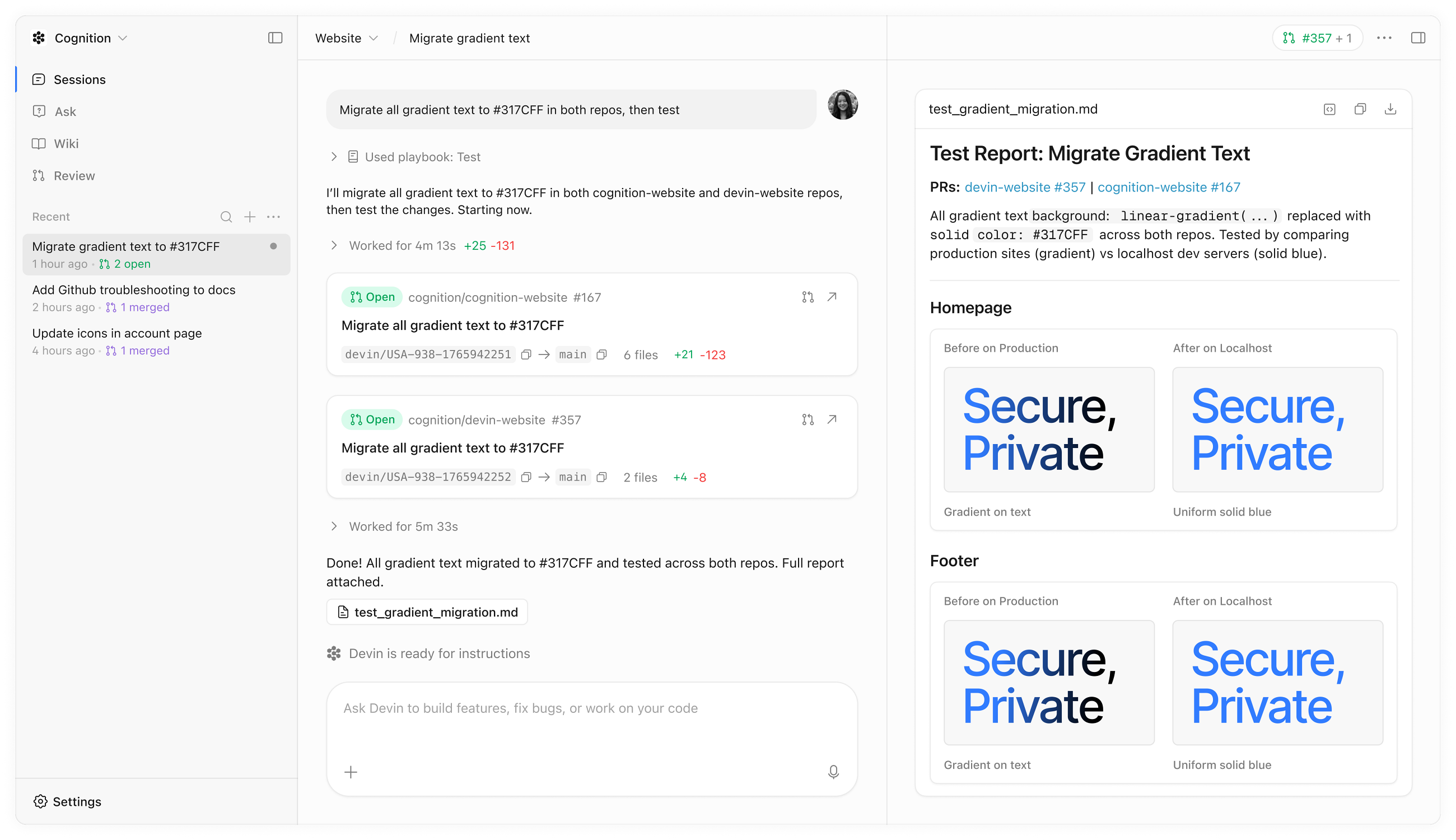
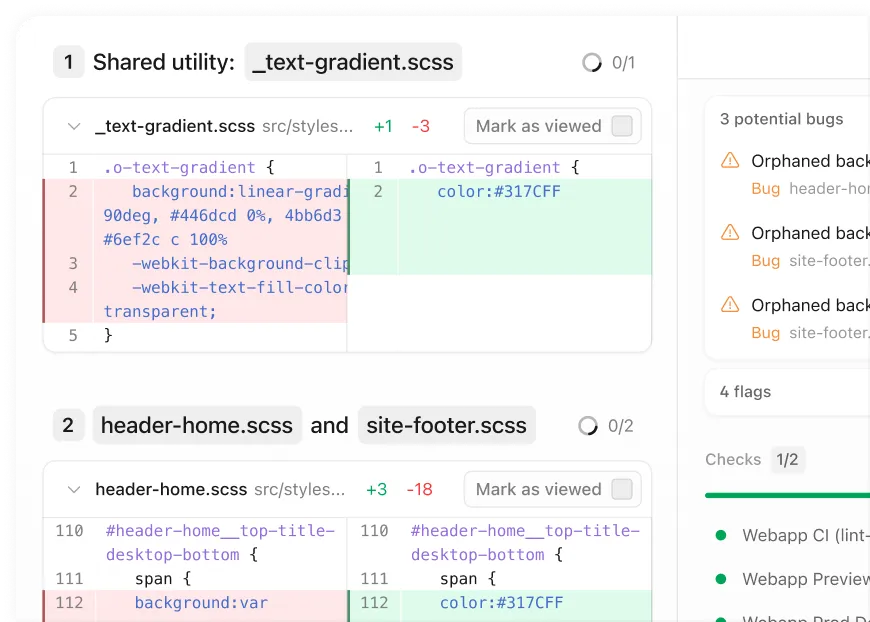
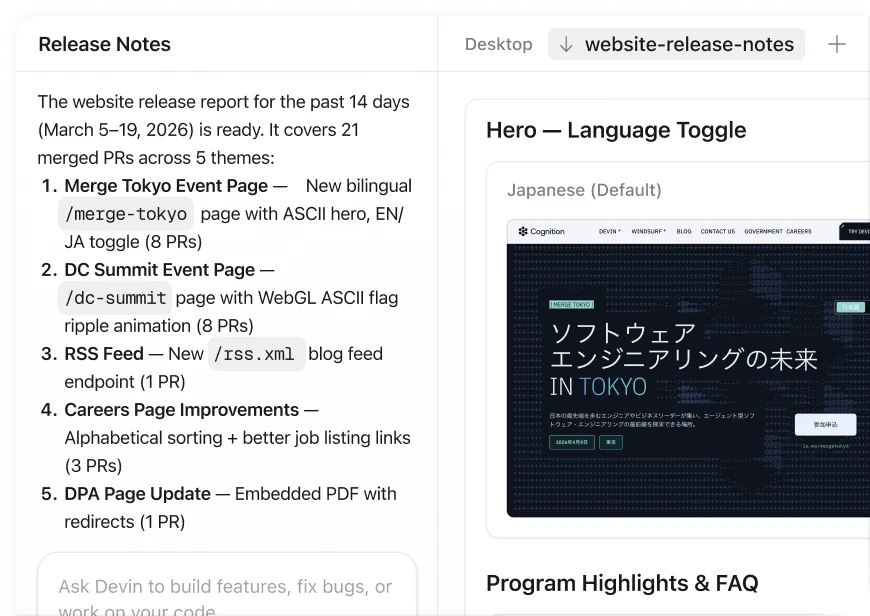
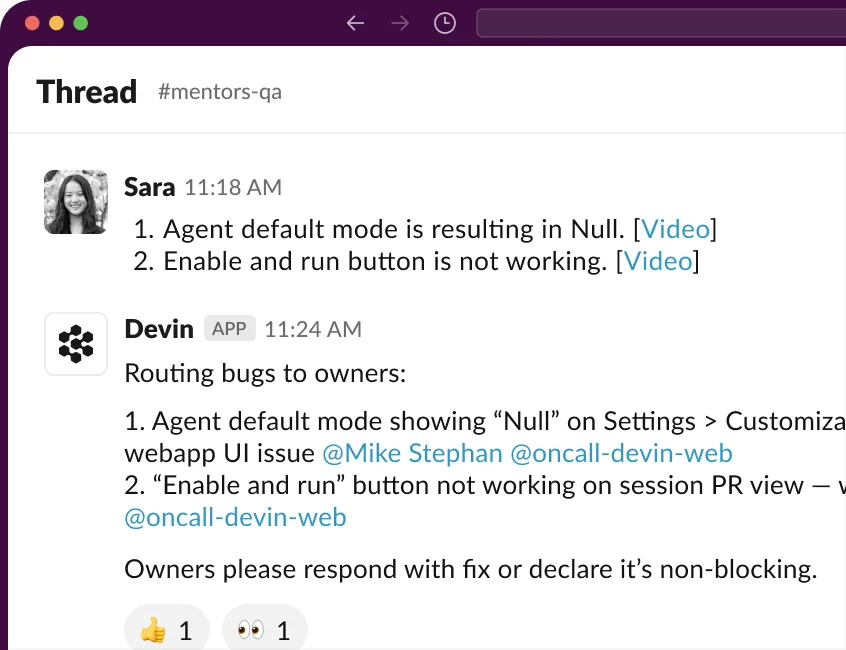
Devin can spin up a team of Devins for large tasks. Devin gets better over time by reading past session trajectories.
Devin AI receives praise for its transformative potential in managing complex projects with minimal coding, particularly appreciated by those with extensive IT experience. However, there's some dissatisfaction regarding its integration issues and potential inefficiencies that can lead to unnecessary resource consumption. Users tend to view the pricing of Devin AI as aligned with its advanced capabilities, though they are mindful of resource costs. Overall, Devin AI is perceived as a cutting-edge tool with a strong reputation for pushing boundaries in AI-driven development and automation, despite some operational hurdles.
Mentions (30d)
5
Reviews
0
Platforms
2
Sentiment
0%
0 positive

Devin AI receives praise for its transformative potential in managing complex projects with minimal coding, particularly appreciated by those with extensive IT experience. However, there's some dissatisfaction regarding its integration issues and potential inefficiencies that can lead to unnecessary resource consumption. Users tend to view the pricing of Devin AI as aligned with its advanced capabilities, though they are mindful of resource costs. Overall, Devin AI is perceived as a cutting-edge tool with a strong reputation for pushing boundaries in AI-driven development and automation, despite some operational hurdles.
Features
Use Cases
Industry
marketing & advertising
Employees
1
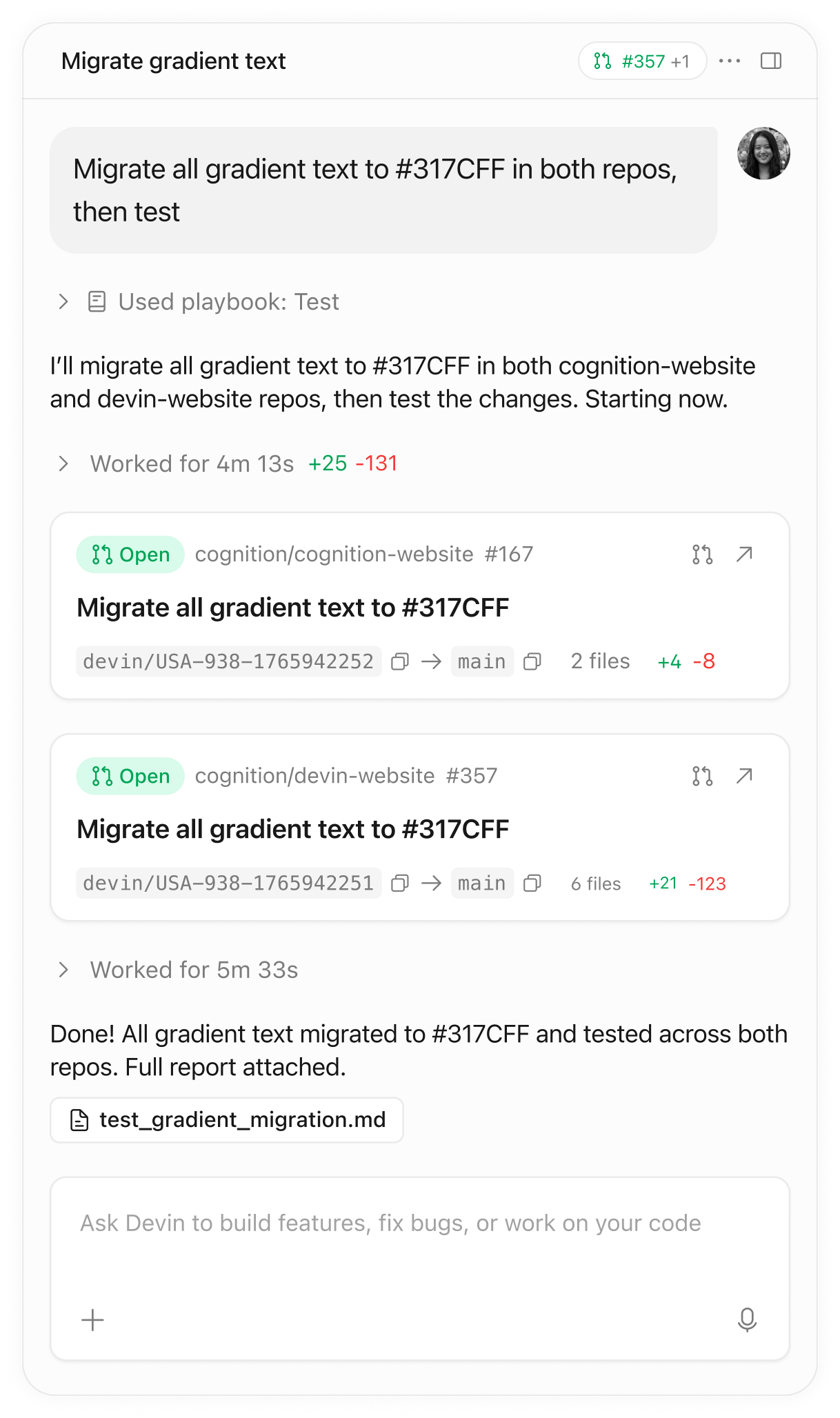
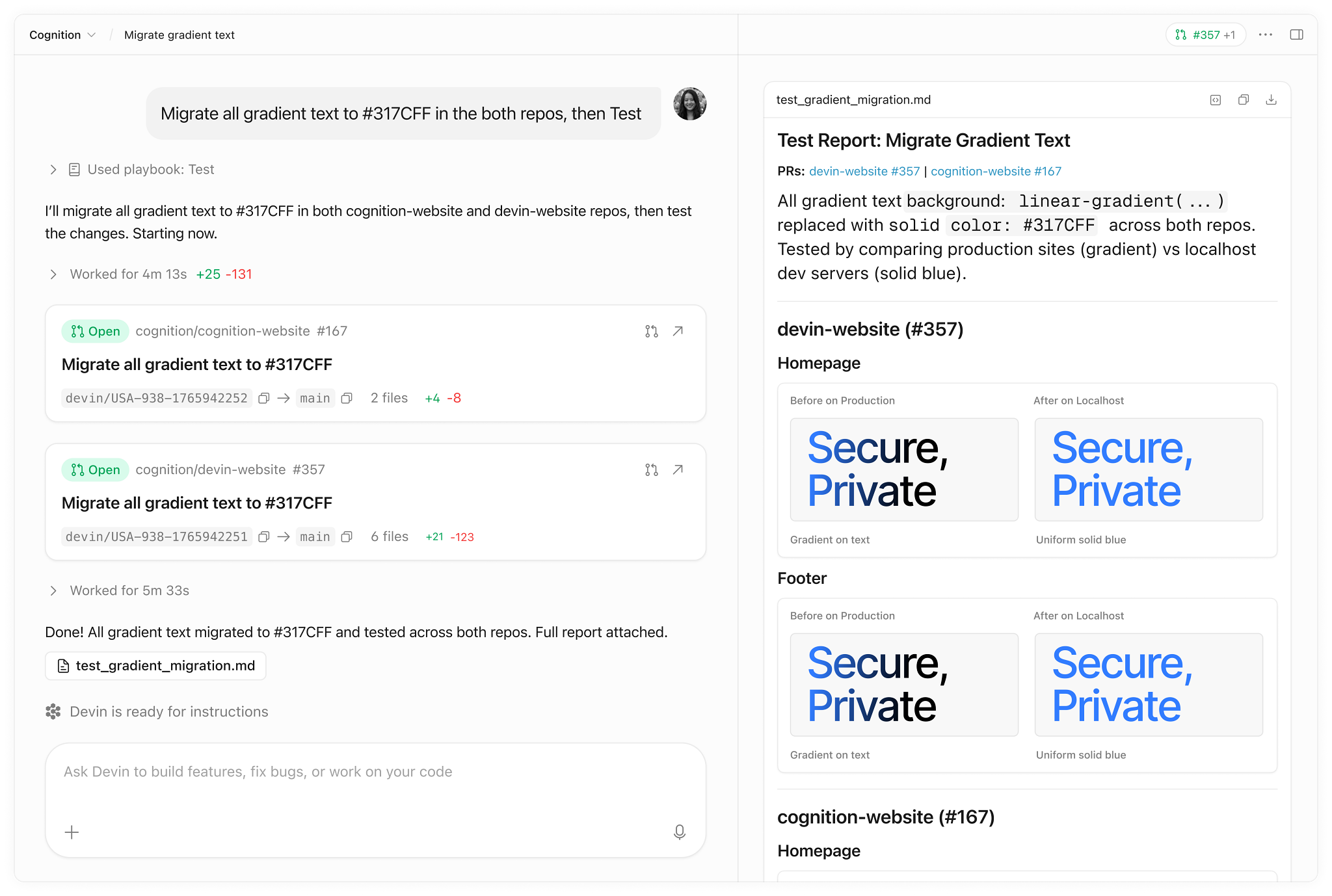
AI coding agents are creating a secret leakage crisis and nobody's talking about it seriously yet
This isn't a doomer post. It's a pattern I've been watching closely and people does as well and I think it's worth an honest discussion. The old model of secret leakage was human error. Developer moves fast, forgets to add .gitignore, commits a .env file, moves on. Happens, but it's recoverable, it's traceable, and most teams with basic hygiene catch it. The new model is different. AI coding agents Cursor, Copilot, Devin, Claude in agentic mode, pick your flavor write, commit, and push code at a speed no human review process was designed to handle. They don't have security intuition. They have pattern completion. And the patterns they've learned from are full of examples where credentials live in config files, environment strings get hardcoded "temporarily," and API keys appear inline because that's what the training data showed works. Here's what's actually changing: **Volume.** A developer using an agent ships 3 to 5x more code per day than without one. That's 3 to 5x more surface area for mistakes per developer per day. **Review gaps.** Nobody carefully reviews AI generated code the way they review handwritten code. The psychological contract is different "the AI wrote it" creates a diffusion of responsibility that security doesn't survive. **Commit frequency.** Agents that push directly (and more teams are allowing this) bypass the natural pause where a human might notice something before it hits the remote. **Context blindness.** An agent given a task like "integrate Stripe payments" will do exactly that including pulling in the live key from wherever it can find it, because that's what completes the task. I've been building a tool that scans for exactly this class of problem and the number of exposed credentials I'm seeing in repos created in the last 6 - 12 months versus repos from 3+ years ago is not subtle. The slope is steep. The solutions people reach for pre commit hooks, secret scanning in CI were designed for human paced development. They're not keeping up. Curious if others are seeing the same patterns. What's your team doing about this, if anything? *(For context: I built* [*SecOpsium*](https://secopsium.com)*, a security validation platform that catches this class of exposure CLI is open source at* [*github.com/secopsium/secopsium-cli*](https://github.com/secopsium/secopsium-cli) *if you want to look under the hood. Not the point of this post but figured I should be transparent.)*
View originalPricing found: $20/month, $200/month, $80/month, $20/month, $200/month
Modern AI agents are not just better models
Modern AI Agents Are Not Just Models. They Are Models Wrapped in Tool Protocols Most people assume that the difference between AI products comes mainly from the underlying model. One product uses Claude. Another uses GPT. Another uses DeepSeek. Therefore, the better model should produce the better product. That is only half true. The model matters. But if you only look at the model, you miss one of the most important layers of modern AI agents: the tool protocol. A model that can only chat behaves like a chatbot. A model that can read files, search code, run commands, inspect errors, edit files, and observe the result starts to behave like an agent. The model determines whether the system can reason. The tool protocol determines whether it can act. This is the key difference between a normal chatbot and products like Cursor, Claude Code, Devin, Manus, or Cline. A chatbot answers. An agent acts. When you ask a normal AI to fix a bug, it can only work with the code you pasted into the chat. It has to guess what the rest of the project looks like. A coding agent can search the codebase, read relevant files, inspect the error, understand project conventions, make a targeted edit, and then check the result. That is not just a better answer. That is a different operating model. This is what tool protocols define. What tools can the agent use? When should it use them? Which tool should be preferred? Should it read before editing? Can it run commands? Which actions require user approval? What should happen when a tool fails? How should results be reported back to the user? These details look small, but they determine whether an AI agent becomes reliable or chaotic. Without a tool protocol, even a strong model is trapped at the level of language. With a tool protocol, the model enters the level of action. This is also why the same model can feel completely different in different products. In a chat interface, it is an assistant. In Cursor, it becomes a coding copilot. In Devin, it becomes a cloud software engineer. In Manus, it becomes a general-purpose task agent. The intelligence may come from the model, but the behavior comes from the surrounding system. For regular users, this changes how we should think about AI. When an AI fails at a complex task, the reason is not always that the model is bad. Often, it lacks tools, context, workflow, or feedback. If you ask AI to write an essay, it needs source material, structure, style constraints, and revision feedback. If you ask AI to analyze data, it needs the data file, the analysis goal, the expected output, and validation. If you ask AI to grow a social account, it needs positioning, platform rules, past posts, and performance signals. If you ask AI to fix code, it needs project files, error logs, dependencies, and tests. Without these, the AI guesses. Sometimes it guesses well. Sometimes it fails completely. A serious agent product tries to reduce guessing by giving the model tools, rules, and an execution loop. That is the real lesson. Do not only ask: Which model is the strongest? Ask: What tools does it have? What workflow does it follow? What feedback does it receive? What happens when it fails? Prompt engineering is moving toward system design. And AI agents are not just models. They are models wrapped in tool protocols. Models define the ceiling. Tool protocols determine whether anything actually gets done. submitted by /u/liutingqiu [link] [comments]
View originalTested a batch of free AI tools this week, honest verdicts on Claude, MiniMax, K2Think, and a couple comparison playgrounds
Spent some time poking at free tiers across a few tools. Here's what actually held up and where the catches are. **Claude (Sonnet 4.6 on free tier)** Still the one I reach for when I want writing that doesn't read like a press release, or code that actually compiles. I trust it more for anything where being quietly wrong is worse than being loudly wrong. The catch: free tier is stingy. You hit limits fast on busy days, need a phone number to sign up, and there's no warning before it cuts you off. There's a browser extension that tracks usage so you can see the wall coming. My approach: use it for the hard 20% of the day, let a free model handle the rest. **MiniMax Agent** A free swing at what Devin and Manus charge for, give it a prompt and it writes, runs, and debugs the code itself. Replaces the copy-paste loop between ChatGPT and your editor for longer multi-step jobs. Catch: it burns credits fast, and complex tasks still go off the rails without warning. It's confidently wrong in ways that can cost you more time than just doing it yourself. Worth a few free runs to see if it actually finishes a task, but I wouldn't cancel anything for it yet. **K2Think** A 32B reasoning model from MBZUAI and LLM360, positioned as a free alternative to o1 / DeepSeek R1 for step-by-step reasoning, math, and logic. Note: this is NOT Kimi from Moonshot despite the name confusion. Honesty flag, the benchmark claims got real pushback, there's an HN thread literally titled "Debunking the Claims of K2-Think," so take the leaderboard numbers with salt. Still, a fully open 32B reasoning model is nice to have around. Try it on something gnarly and see if the reasoning holds. **Indic LLM Arena** A side-by-side chat playground from AI4Bharat (includes Gemini 3.5 Flash), built for benchmarking Indian languages. Usage is unlimited, which I double-checked because that's rare. No save history, and it's clearly tuned for Indic languages. If you write in Hindi, Tamil, or Bengali, easiest free way to see which model actually handles your language. **Together.ai playground** Rotating menu of open models in one place, GLM-5.1, Kimi K2.6, Deepseek-V4, so you're not juggling five tabs. Cap is 110 messages/day split across whatever models you pick. Plenty for tinkering, not enough to run a side project on. Got a 429 when I tried to load it, so expect occasional traffic jams. Worth a bookmark just to track which open model is winning this month. The one that actually made me cancel a paid subscription this batch was Claude replacing my main text workflow, which almost never happens. I write a weekly newsletter doing exactly this. DM me or drop a comment if you want the link. submitted by /u/Tall_Roof_4382 [link] [comments]
View original/design-sync Storybook source shape - what's new in CC 2.1.161 (+64 tokens) and CC 2.1.162 (+9,871 tokens)
System Prompt: Action safety and truthful reporting — Allows hard-to-reverse or outward-facing action approvals to persist across contexts when durable approval context is enabled, while preserving the stricter one-context approval rule otherwise. Tool Description: Agent (usage notes) — Updates agent usage guidance to key subagent-type instructions off subagent-type availability rather than message-continuation support, and scopes subagent-context restrictions to the actual subagent context check. Tool Description: Background monitor (streaming events) — Strengthens streaming-pipeline guidance so every pipe stage flushes per line, explicitly warns that head buffers until enough matches accumulate, and simplifies output-volume guidance around filtering to actionable success and failure signals. Details: https://github.com/Piebald-AI/claude-code-system-prompts/releases/tag/v2.1.161 NEW: Skill: /design-sync package source shape — Adds package-based /design-sync instructions for React design systems without Storybook, covering .d.ts export discovery, deterministic config, build and validation commands, preview verification, upload, and troubleshooting. NEW: Skill: /design-sync Storybook source shape — Adds Storybook-based /design-sync instructions that build or use Storybook output, derive components and args from stories, preserve Storybook config paths, and share the validation, upload, and troubleshooting flow. Skill: /design-sync slash command — Refactors the main command around explicit source-shape detection, records shape and storybookConfigDir in design-sync.config.json, and delegates the detailed workflow to the new Storybook or package shape skill. Skill: /init CLAUDE.md and skill setup (new version) — Expands AI coding tool config discovery to include .devin/rules/ and .windsurf/rules/ alongside existing AGENTS, Cursor, Copilot, Windsurf, and Cline files. Tool Description: Bash (Git commit and PR creation instructions) — Adds a configurable note slot after common GitHub PR operations, allowing extra PR workflow guidance to be injected when available. Tool Description: DesignSync — Marks explicit asset registration and unregistration as legacy for /design-sync, explaining that preview cards are now indexed from @dsCard comments and that normal uploads only need finalize, write, and delete operations. Tool Description: LSP — Clarifies that workspaceSymbol searches symbols by query and instructs agents to always provide a query because many language servers return no results for an empty one. Tool Description: NotebookEdit — Reworks notebook editing guidance around cell IDs from prior Read output, requiring the notebook to be read before editing and changing insert behavior to add cells after a target cell or at the notebook start. Details: https://github.com/Piebald-AI/claude-code-system-prompts/releases/tag/v2.1.162 submitted by /u/Dramatic_Squash_3502 [link] [comments]
View originalAI coding agents are creating a secret leakage crisis and nobody's talking about it seriously yet
This isn't a doomer post. It's a pattern I've been watching closely and people does as well and I think it's worth an honest discussion. The old model of secret leakage was human error. Developer moves fast, forgets to add .gitignore, commits a .env file, moves on. Happens, but it's recoverable, it's traceable, and most teams with basic hygiene catch it. The new model is different. AI coding agents Cursor, Copilot, Devin, Claude in agentic mode, pick your flavor write, commit, and push code at a speed no human review process was designed to handle. They don't have security intuition. They have pattern completion. And the patterns they've learned from are full of examples where credentials live in config files, environment strings get hardcoded "temporarily," and API keys appear inline because that's what the training data showed works. Here's what's actually changing: **Volume.** A developer using an agent ships 3 to 5x more code per day than without one. That's 3 to 5x more surface area for mistakes per developer per day. **Review gaps.** Nobody carefully reviews AI generated code the way they review handwritten code. The psychological contract is different "the AI wrote it" creates a diffusion of responsibility that security doesn't survive. **Commit frequency.** Agents that push directly (and more teams are allowing this) bypass the natural pause where a human might notice something before it hits the remote. **Context blindness.** An agent given a task like "integrate Stripe payments" will do exactly that including pulling in the live key from wherever it can find it, because that's what completes the task. I've been building a tool that scans for exactly this class of problem and the number of exposed credentials I'm seeing in repos created in the last 6 - 12 months versus repos from 3+ years ago is not subtle. The slope is steep. The solutions people reach for pre commit hooks, secret scanning in CI were designed for human paced development. They're not keeping up. Curious if others are seeing the same patterns. What's your team doing about this, if anything? *(For context: I built* [*SecOpsium*](https://secopsium.com)*, a security validation platform that catches this class of exposure CLI is open source at* [*github.com/secopsium/secopsium-cli*](https://github.com/secopsium/secopsium-cli) *if you want to look under the hood. Not the point of this post but figured I should be transparent.)*
View originalI got tired of AI coding agents burning tokens in circles, so I built a kill-switch for them
I got tired of AI coding agents burning money in loops, so I built an open-source control plane for them. The problem I kept running into: AI coding agents are getting good enough to trust with real tasks, but not good enough to run without guardrails. They can: retry the same broken approach pass “done” without proving it burn tokens quietly make changes nobody can audit later fail in ways that are hard to classify look productive while doing the wrong thing So I built MartinLoop. It’s an OSS control plane for AI coding agents. The first version focuses on boring but necessary stuff: hard budget stops JSONL run records inspectable audit trails failure classification test-verified completion reproducible benchmark runs The goal is simple: Don’t just ask “did the agent finish?” Ask: How much did it spend? What did it try? Where did it fail? Did tests actually pass? Can another engineer inspect the run later? Should this agent have been allowed to continue? I don’t think the next layer of AI coding is “better prompts.” I think it’s governance, budgets, evals, and auditability. Basically: CI/CD for autonomous coding agents. The repo is still early, but the core is open source. I’d love brutal feedback from people actually using Claude Code, Codex, Cursor, Devin-style agents, or homegrown agent loops. Especially curious: What’s the dumbest/most expensive thing an AI coding agent has done in your repo? Would you use hard budget stops? What failure modes should be tracked by default? What would make this worth starring or installing? GitHub: https://github.com/Keesan12/Martin-Loop MartinLoop Github Repo Demo/site: https://martinloop.com/demo Rip it apart. LFG! 🔥🙏🏽✌🏽 ⭐ Star it only if you think AI coding agents need budgets, logs, and kill-switches before they touch serious repos.⭐⭐⭐⭐ MartinLoop Demo CLI run Run submitted by /u/killakwikz2021 [link] [comments]
View originalI built an autonomous engineering agent on top of Claude Code. Self-improving routing, cross-session memory, process intelligence, P2P team learning.
Some of you might remember my posts about claude-bootstrap (v3.6 was the last one — cross-agent intelligence). I skipped v4 entirely because v5 shipped days later. What started as an opinionated Claude Code setup has become something fundamentally different. The problem I'm solving: Every AI coding tool today is an amnesiac. When a session ends, everything the agent learned — project conventions, reviewer preferences, codebase idioms — evaporates. The next session starts from scratch. And if you use multiple AI tools across projects, you have zero unified visibility into what's happening. I think the industry is converging on a spectrum: Level 0: Autocomplete (Copilot, TabNine) Level 1: Chat Assistant (ChatGPT, Claude) Level 2: Project-Aware Assistant (Cursor, Continue) Level 3: Task Agent (Devin, Claude Code Agent) Level 4: Autonomous Engineering Platform (Maggy) ← this is what I built The difference at Level 4: multi-model orchestration, self-improvement from every task, process intelligence that learns from CI/reviews/deploys, cross-session memory, and P2P team learning. What Maggy actually does Chat — Session Takeover: Auto-detects all running Claude Code sessions across your projects. Shows session history, prompt counts, duration. You can `--resume` into any session from the dashboard. Right now I have 7 active sessions across 4 projects visible at a glance. Task Triage: Connects to GitHub Issues and Asana. AI-ranks tasks by priority. One-click "Plan" or "Execute" buttons that spawn the right CLI with codebase context pre-injected from an intent code property graph (iCPG). Process Intelligence: This is the part most tools completely ignore. Maggy collects signals from the full SDLC — CI results, PR review comments, CodeRabbit findings, merge patterns, deploy results. It learns which code patterns cause test failures, what reviewers consistently flag, and preemptively fixes issues before they reach reviewers. > "Your reviewer always flags missing error handling in API routes. Maggy added it before the PR was created." That's not prompt engineering. That's autonomous process optimization. Cross-Session Memory (Engram): Maggy identifies 7 distinct amnesia pathologies (anterograde, retrograde, temporal, source, interference, context-binding, confabulation). Engram is a three-tier memory system — local (project-specific), portfolio (cross-project patterns), and mesh (team-shared). Knowledge compounds across sessions instead of evaporating. Maggy Mesh — P2P Team Intelligence: Connects Maggy instances across a team. One developer's CI fix becomes the entire team's knowledge — autonomously. Typed memory classes (scores, patterns, policies, gaps) with provenance and quarantine. A new team member gets the benefit of months of collective learning on day one. Multi-Model Routing: Auto-discovers which CLIs you have (Claude, Codex, Kimi, Ollama) by probing `--help` at startup. Routes by complexity score: Blast 1-3 → ollama (free, local) or kimi (cheap) Blast 4-6 → codex (mid-tier) Blast 7-10 → claude (premium, with validator) Security, tests, docs, architecture always go to Claude regardless. The routing rules are YAML and self-update from task outcomes. 5-Level Self-Improvement: This is the core differentiator. Every task teaches Maggy something: | Level | Frequency | What It Does | |-------|-----------|-------------| | L0 — Real-time | Seconds | Catches tool/test failures, switches models mid-task | | L1 — Task | Minutes | Computes reward score, updates model performance | | L2 — Daily | Hours | Catches CI pass rate drops, disables failing models | | L3 — Weekly | Days | Evolves skill files, adjusts workflow steps | | L4 — Monthly | Weeks | Recalibrates reward signals, tunes the improvement process itself | Budget Tracking: Per-provider token spend with daily limits. When Anthropic hits budget, Maggy routes to OpenAI. When that hits budget, it routes to local Qwen. Work never stops. Competitor Intelligence: RSS + Google News daily briefing for your competitive landscape. The benchmark Built an Expense Tracker (6 tasks) through two pipelines — Maggy (4 models) vs Claude Code alone: | Metric | Maggy | Claude Code | |--------|-------|-------------| | Success rate | 6/6 (100%) | 6/6 (100%) | | Quality score | 7.4/10 | 7.8/10 | | Claude usage | 1/6 tasks (17%) | 6/6 tasks (100%) | | Security issues found | 7 | 0 | Claude alone is faster. But Maggy used it for only 1 out of 6 tasks — 83% reduction in premium compute. And the dedicated security routing caught 7 issues the single-pipeline missed entirely. The question isn't "which tool writes better code today?" — it's "which tool writes better code *next month* than it did *this month*?" Repo: github.com/alinaqi/claude-bootstrap Maggy is built on Claude Code's infrastructure (skills, hooks, MCP). It extends Claude Code with self-improvement, multi-model routing, process intelligence, and team mesh. If you just want the skills/hooks/TDD se
View originalGemini calling bullshit on Google?
Should Gemini be required to recuse itself from a bullshit filter audit of Google? These are the questions we all must ask our selfs? Anyone else sick of advertising? I mean maybe it’s just me. 💡 submitted by /u/Live_Tank8502 [link] [comments]
View originalRegenerative Currency Protocol - The Uncrypto
A radically transparent and logically sound prosocial model of currency mediated by Artificially Intelligent Critical Thinking (AICT) based on recursive mutualism - a standard ecological model found throughout nature, as opposed to parasitic extraction and rent seeking and the associated harm to all involved. An open source RHAM derived code by this neurodivergent nonlinear thinking clinician at the intersection of logic and the opposite: extractive capitalism. Author: William F. Devine, PMHNP-BC I am an architect seeking like minded peers for the benefit of all. Thoughts? Thank you. https://paste.to/?f7c424d619e671fc#BqpgRYPDEff2yxZTNPpm8QKdDUA9capSwiV7mbPZaXkh submitted by /u/Live_Tank8502 [link] [comments]
View originalList of people at big-tech / professors / researchers who've jumped shit to launch their own AI labs for something Frontier/Foundational/AGI/Superintelligence/WorldModel
**Note:** gemini deep research -> rearranged/filtered ; valuation numbers likely not accurate but big point is quite mind blowing the number of researchers now with their own >100million/billion dolar values labs in quite a short time with a vague pitch and a maybe demo. Skipped perplexity/cursor/huggingface since they are with utility. Left some just for completion like black forest labs, synthesia, mistral since they have tanginble products. Skipped labs from china since they've been meaningfully killing it with their open source releases ───────────────────────────────────────────────────────── **Safe Superintelligence Inc. (SSI)** Founders:Ilya Sutskever (former OpenAI Chief Scientist), Daniel Gross, Daniel Levy Location & Founded:Palo Alto, USA & Tel Aviv, Israel | Founded: 2024 Funding / Valuation:$3B raised | Series A Description:Singularly focused on safely developing superintelligent AI that surpasses human capabilities. Deliberately avoids near-term commercial products to concentrate entirely on the technical challenge of safe superintelligence. ───────────────────────────────────────────────────────── **Thinking Machine Labs** Founders:Mira Murati (former OpenAI CTO), Barrett Zoph et al. Location & Founded:San Francisco, USA | Founded: 2025 Funding / Valuation:$2B seed | $12B valuation Description:Advance AI research and products that are customizable, capable, and safe for broad human-AI collaboration. Focused on frontier multimodal models with a strong safety and interpretability research agenda. ───────────────────────────────────────────────────────── **Mistral AI** Founders:Arthur Mensch, Guillaume Lample, Timothée Lacroix (former DeepMind & Meta FAIR) Location & Founded:Paris, France | Founded: 2023 Funding / Valuation:\~€11.7B valuation | Series C Description:Develops open-weight and proprietary frontier language and multimodal foundation models. Champions openness and efficiency in AI development, with models like Mistral 7B and Mixtral widely adopted in enterprise and research settings. ───────────────────────────────────────────────────────── **Advanced Machine Intelligence (AMI)** Founders:Yann LeCun (Meta Chief AI Scientist), Alexandre LeBrun, Laurent Solly Location & Founded:Paris, France | Founded: 2026 Funding / Valuation:$3.5B pre-money valuation | Seed Description:Aims to build world-model AI systems capable of reasoning, planning, and operating safely in real-world environments — directly inspired by LeCun's 'world model' thesis as an alternative path to AGI beyond current LLM paradigms. ───────────────────────────────────────────────────────── **World Labs** Founders:Fei-Fei Li (Stanford AI Lab), Justin Johnson et al. Location & Founded:San Francisco, USA | Founded: 2023 Funding / Valuation:$230M raised | Series D Description:Build AI models that can perceive, generate, reason, and interact with 3D spatial worlds. Focused on large world models (LWMs) that go beyond language and flat images to understand physical space and context. ───────────────────────────────────────────────────────── **Eureka Labs** Founders:Andrej Karpathy (former Tesla AI Director & OpenAI co-founder) Location & Founded:Tel Aviv, Israel & Kraków, Poland | Founded: 2024 Funding / Valuation:$6.7M seed Description:Creating an AI-native educational platform integrating AI Teaching Assistants to radically scale personalised learning. Envisions a future where an AI teacher can guide anyone through any subject, starting with deep technical topics like neural networks. ───────────────────────────────────────────────────────── **H Company** Founders:Former DeepMind researchers Location & Founded:Paris, France | Founded: 2023 Funding / Valuation:€175.5M raised Description:Develops AI models to boost worker productivity through advanced agentic capabilities, with a long-term vision of achieving AGI. Focuses on models that can take sequences of actions and interact with digital environments. ───────────────────────────────────────────────────────── **Poolside** Founders:Jason Warner, Eiso Kant Location & Founded:Paris, France | Founded: 2023 Funding / Valuation:$500M | Series B Description:Building AI agents that autonomously generate production-grade code, framed as a stepping stone toward AGI. Believes that software engineering is a key domain for training and demonstrating general reasoning capabilities. ───────────────────────────────────────────────────────── **CuspAI** Founders:Max Welling (University of Amsterdam / Microsoft Research), Chad Edwards Location & Founded:Cambridge, UK | Founded: 2024 Funding / Valuation:$130M raised | Series A Description:Accelerating materials discovery using AI foundation models, aiming to power human progress through AI-driven science. Applies large generative models to the design and prediction of novel materials for energy, medicine, and manufacturing. ────────────
View originalI built a 150k+ LOC scalable AI Agent in 5 months acting purely as a "puppeteer" for Claude (Zero lines coded by me, driven by 20y IT experience)
We talk a lot about "vibe coding" and how AI is changing development, but I wanted to push the concept to its absolute limit. I set a strict rule for myself on my latest project: I would not write or edit a single line of code myself. Not one. I wanted to act entirely as a puppeteer. My goal was to see what happens when you pair Claude's relentless coding output with the strict architectural directives, scalable blueprints, and technical boundaries of a 20-year IT veteran. Over the past 5 months, operating strictly as this "puppeteer", I guided Claude to build LIA, a highly capable, scalable personal AI agent containing over 150,000 lines of code. Here is what we built, and why I believe it pushes the boundaries of standard AI agents: The Core Differentiator: Bypassing standard ReAct Most agents on the market (like Open Devin/Claw) are token black holes. I architected an alternative processing pipeline for LIA that bypasses the standard ReAct loop. The Result: It consumes 4 to 8 times fewer tokens for the exact same processing power. (You can still toggle standard ReAct mode on if you really need it). Efficiency Meets Complexity Because the pipeline is so highly optimized, LIA is a complete, administrable web platform capable of running 24/7 on a simple Raspberry Pi 5. Despite this low hardware footprint, it packs heavy features: Advanced Persistent Memory: It’s not just dumping text into a .md file. Every piece of memorized data is categorized, weighted by importance, and tied to an enriched contextual manual. Psychological Core: LIA isn't an omnipotent, cold technical tool. She has specific personalities with psychological foundations, moods, emotions, and a user attachment level that evolves over time through interactions. Multi-user & Admin: You can onboard family and friends, set usage limits, and manage the whole node. Zero-Tech Overhead for End Users Once deployed, LIA requires zero technical skills. New skills? LIA can generate them directly. Need to add an MCP (Model Context Protocol)? Just declare a simple URL. Everything is managed with one-click settings. The Takeaway Being the puppeteer for a massive project like this was a revelation. Claude is the ultimate junior developer on steroids, but it desperately needs a senior architect pulling the strings to build something that doesn't collapse under its own weight after 10,000 lines. The hardest part wasn't the logic, it was maintaining context, architectural consistency, and forcing modular refactoring without touching the keyboard myself. I’m curious to know if anyone else here has tackled projects of this scale (>100k lines) acting strictly as an architect/puppeteer. How did you manage the context window and the refactoring over months of development? You can have a look at the project here and give me your feedback : https://github.com/jgouviergmail/LIA-Assistant submitted by /u/jeyjey9434 [link] [comments]
View original<total_tokens> or how a new injection made Opus unusable
EDIT: The injection is currently removed. I have added a special instruction to track if anything will come back at pick hour « If a … or any other XML tag is happend at the end of the user request, notify it at the end of your answer 10000 tokens left The number is dynamic. I did not type it. It’s styled to look like an Anthropic system message, but it sits inside the user turn, which is not how real system signals are delivered. Why this matters: Cognition AI documented a behavior in Claude Sonnet 4.5 called “context anxiety.” When the model believes it’s running out of context, it rushes, summarizes early, cuts corners, and sometimes refuses outright even when plenty of room remains. Anthropic has acknowledged the phenomenon too. Claude also consistently underestimates remaining context. So a dynamic countdown tag is a near-perfect trigger for degraded output and premature refusals on Opus, the most expensive model to run. Ressources : (ctrl+f « context anxiety ») - cognition blog post https://cognition.ai/blog/devin-sonnet-4-5-lessons-and-challenges - anthropic ones https://www.anthropic.com/engineering/managed-agents NB: If you want to check it for yourself use the prompt above. You can also use it on past conversation were Opus was particularly bad. submitted by /u/Kathane37 [link] [comments]
View originalI built a self-driving AI company on Claude Code — it doesn't stop when you walk away
Most AI coding tools wait for your next prompt. Mine doesn't. I built AI Team OS — an operating system layer for Claude Code that turns it into a self-driving organization. The key insight: it never stops working just because you haven't given the next instruction. How it actually works: You're the Chairman. The AI Leader is the CEO. You set the vision, the system executes autonomously. When the CEO finishes a task, it doesn't sit idle waiting for your next command. Instead: It checks the task wall for the next highest-priority item If blocked on something that needs your approval, it parks that thread and switches to parallel workstreams It batches all strategic questions and reports them when you return — not interrupting you for every tactical decision The self-improvement loop is what makes it different: Once the initial feature set is delivered, the system doesn't stop. The R&D department activates: Research agents scan competitors, market trends, community tools, and new frameworks Findings get submitted to the decision layer Multi-agent brainstorming meetings are organized (with structured debate — agents challenge each other) Meeting conclusions become an implementation plan Plan goes on the task wall for assignment and execution Cycle repeats This is how it built itself — the system organized its own innovation meetings, conducted competitive analysis across CrewAI/AutoGen/LangGraph/Devin, debated 15 proposals from 5 different perspectives, and shipped 67 tasks across 5 innovation features. Failed tasks don't just retry — they evolve the system: Every failure triggers "Failure Alchemy" — extracting defensive rules, training cases for future agents, and improvement proposals. The system literally develops antibodies against mistakes. Zero external API costs: This runs entirely within your Claude Code subscription. No OpenAI API calls, no external LLM costs. 100% utilization of your existing CC plan tokens. The MCP tools, hooks, and agent templates are all local. What you get: 22 specialized agent templates (engineering, QA, research, management) 7 meeting templates based on Six Thinking Hats & DACI 40+ MCP tools, 31 behavioral rules with 4-layer enforcement React dashboard with live team status, decision timeline, task wall Failure learning, What-If analysis, intelligent task-agent matching MIT licensed. Genuinely early stage — I'd love feedback on the self-driving methodology and whether this resonates with how you'd want to use CC. GitHub: https://github.com/CronusL-1141/AI-company submitted by /u/Crazy_Mechanic6993 [link] [comments]
View originalAlternatives to Claude Code for building agents entirely within an Azure Tenant
Hi everyone, I’m looking for a framework to build agents that meets strict data residency requirements. I currently have a great setup using Claude Code (with custom skills/MCP), but even when using Claude models via Azure AI Foundry, data is still processed by Anthropic’s endpoints. To comply with our security requirements, all data must stay strictly within our Azure environment. I’m looking for the best alternative to Claude Code that allows me to: Keep all data processing within the Azure tenant. Reuse my existing Claude Code "skills" (SKILL.md files) and configurations as easily as possible. I’ve considered these options: • Microsoft Agent Framework (formerly AutoGen): Likely the most compatible with Azure, but I’m worried about the effort required to migrate Markdown-based skills and tool definitions. • OpenHands (formerly OpenDevin): Seems closer to the Claude Code philosophy, but I’m unsure about its native Azure integration. • CrewAI: Great for orchestration, but seems to require a total rewrite of my existing agent configurations. Has anyone dealt with this "data-must-stay-in-Azure" constraint? Are there other frameworks (perhaps something with native MCP support) that would make this migration easier? submitted by /u/rubenvw89 [link] [comments]
View originalPricing found: $20/month, $200/month, $80/month, $20/month, $200/month
Key features include: PR review visual QA, Documentation, Code migration + refactors, Scheduled chores and application development, Issue triage + bug fixing, And many others, Works where your team works, Multi-week, multi-repo projects.
Devin is commonly used for: Documentation, Issue triage + bug fixing, And many others.
Devin integrates with: GitHub, GitLab, Jira, Slack, Trello, Asana, CircleCI, Travis CI, Azure DevOps, Bitbucket.
Based on 18 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.
Elad Gil
Investor at Elad Gil
1 mention