Explore our AI suite and get more done: Translate speech, text, and media, or integrate the DeepL API.
DeepL is highly praised for its accurate translations and natural language processing, resulting in most users rating it between 4 to 5 stars. While there are minimal complaints, when mentioned, they typically revolve around infrequent issues with language nuances or less common languages. Users generally perceive the pricing as reasonable relative to the quality and performance it offers. Overall, DeepL maintains a strong reputation and is considered a leading tool in the translation industry.
Mentions (30d)
4
1 this week
Avg Rating
4.7
20 reviews
Platforms
4
Sentiment
35%
18 positive


DeepL is highly praised for its accurate translations and natural language processing, resulting in most users rating it between 4 to 5 stars. While there are minimal complaints, when mentioned, they typically revolve around infrequent issues with language nuances or less common languages. Users generally perceive the pricing as reasonable relative to the quality and performance it offers. Overall, DeepL maintains a strong reputation and is considered a leading tool in the translation industry.
Features
Use Cases
Industry
information technology & services
Employees
1,600
Funding Stage
Venture (Round not Specified)
Total Funding
$410.0M
X Users Find Their Real Names Are Being Googled in Israel After Using X Verification Software “Au10tix”
X Users Find Their Real Names Are Being Googled in Israel After Using X Verification Software “Au10tix” Alan Macleod On January 30, the Department of Justice released its latest tranche of 3.5 million documents relating to Jeffrey Epstein. Years of emails, texts, and images were suddenly in the public domain. Epstein, a serial rapist, masterminded a global human trafficking and sexual abuse network, and could count princes, professors, and politicians among his closest friends and accomplices. MintPress News has been at the forefront of covering the Epstein saga, revealing his extremely close links to American and Israeli intelligence groups – a discovery that perhaps sheds light on why it took so long for the world’s most notorious pedophile to face accountability for his crimes. Many of the DOJ files have been heavily redacted in order to protect Epstein’s powerful clients. Still, they have exposed a massive elite nexus revolving around the New York billionaire, implicating presidents, diplomats, and plutocrats in his crimes, and imply that Epstein was significantly more powerful than first thought, shaping modern politics in ways never previously understood. With shocking new details emerging on a near-hourly basis, here are ten Epstein- related stories that have flown relatively under the radar. The Israeli Government Installed Surveillance Cameras at Epstein’s New York Apartment The Israeli government installed and maintained a hi-tech surveillance system at Epstein’s Manhattan apartment complex, including a network of alarms and cameras, emails show. Starting in 2016, the director of protective service at the Israeli mission to the United Nations controlled guests’ access to the Manhattan residence, and even performed background checks on prospective cleaners and other Epstein employees. Former Israeli prime minister Ehud Barak admitted visiting the apartment up to 100 times, and stayed there for long periods of time. While Barak’s security may have been a concern, Epstein is known to have housed underage girls at the apartment, and many of his worst sexual crimes and most sordid parties were held there, raising questions as to what sort of images and data the Israeli government had access to. Epstein Plotted War With Iran Ehud Barak became one of Epstein’s closest associates, staying for extended periods of time at the billionaire’s residences. The pair would email, text, call, and meet constantly. A search for “Ehud Barak” elicits more than 3500 results in the latest file dump alone. The pair would talk politics, and shared a vision of the United States attacking Iran. In 2013, with negotiations between the International Atomic Energy Agency and Iran stalling, Epstein emailed Barak stating, in typically poor spelling and grammar: “hopefully somone suggests getting authorization now for Iran. the congress woudl do it.” Epstein would get his wish in 2025, when his close associate Donald Trump began bombing the country. Noam Chomsky Considered Epstein His “Best Friend” Epstein arranged a meeting between Barak and renowned leftist academic (and vehement critic of the U.S. and Israel) Noam Chomsky. An unlikely friendship between the notorious pedophile and star professor blossomed, with the pair regularly meeting up at each other’s houses for dinner. Chomsky flew on Epstein’s “Lolita Express” jet to attend a dinner with Woody Allen in New York. He also expressed his desire to visit Little St. James Island, Epstein’s notorious Caribbean hideaway, and the center of his trafficking operation. Chomsky considered Epstein his “best friend” according to an email sent by his wife, Valeria. The usually curt and matter-of-fact academic signed off his emails to Epstein with unexpectedly flowery language, such as “Like real friendship, deep and sincere and everlasting from both of us, Noam and Valeria.” Chomsky strongly supported Epstein until his dying day in a Manhattan prison cell, taking it upon himself to act as his unofficial crisis manager, describing his accusers as “publicity seekers or cranks of all sorts,” and denouncing the media as a “culture of gossip-mongers” destroying his stellar character. “Ive watched the horrible way you are being treated in the press and public,” he wrote, advising Epstein on tactics to fight the supposed smears against him. For a full rundown of the Chomsky-Epstein relationship, see the MintPress News investigation: “The Chomsky-Epstein Files: Unravelling a Web of Connections Between a Star Leftist Academic and a Notorious Pedophile.” Steve Bannon Developed a Plan to Help Epstein “Crush the Pedo Narrative” A second public figure running defense for Epstein was Steve Bannon. In public, the far-right strategist claimed that he was working on a documentary exposing Epstein. In private messaging, however, Bannon, like Chomsky, was advising Epstein on how best to repair his image. Just weeks before Epstein’s arrest and subsequent death, Bannon was messaging him, devising a complex media strategy
View originalg2
What do you like best about DeepL Translate?The translations are really accurate and it keeps the context of the original text Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?I used the web version, and sometimes I had to reload the page if I hadn't used it in a long time during the day Review collected by and hosted on G2.com.
What do you like best about DeepL Translate?This is the most acurrate diccionary for multi-lingual translation I have ever used Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?nothing to dislike at all. It works so well and fast and easy there is no way to dislike it. Review collected by and hosted on G2.com.
What do you like best about DeepL Translate?What I like best about DeepL Translate is its accuracy and natural-sounding translations. It handles complex sentences and nuanced language much better than other tools, making it ideal for professional documents and clear communication across languages. Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?What I dislike about DeepL Translate is that some advanced features, like document translation or API access, require a paid subscription. Occasionally, very specialized or highly technical terms may not be perfectly translated. Review collected by and hosted on G2.com.
What do you like best about DeepL Translate?The high quality of the translations, very natural and accurate, especially for professional texts, in addition to the speed and the simple interface. Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?Some advanced features are limited to the paid version, and occasionally, there are missing options for specific terminology customization. Review collected by and hosted on G2.com.
What do you like best about DeepL Translate?I really like the ease of use with DeepL. It's very easy and direct, working with almost everything on my PC and even my phone, which allows me to work on the fly. DeepL has become a valuable asset for me, especially when sending legal or sensitive information that needs to be translated from English to Spanish without losing coherence. I appreciate how it integrates seamlessly with tools like Word, PowerPoint, Excel, Outlook, and Firefox. The initial setup is very easy and intuitive, integrating seamlessly with my other AI tools to enhance my work. I have not used customer support, but from what I've heard, it is simple, and easy to contact DeepL when needed, or if questions arise. I use DeepL on a daily basis. Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?Sometimes DeepL can lag, and you need to basically log in again to use the tool. Additionally, whenever you translate a document, you often lose the format. This nags me a lot, if not always. Review collected by and hosted on G2.com.
What do you like best about DeepL Translate?I appreciate how easy the Chrome widget is to use. It lets me translate any selected text on a webpage instantly, without needing to switch tabs. The widget automatically detects the language of the selected text and supports more than 30 languages. In the settings, I can choose my target languages, customize shortcut keys, and enable or disable pop-ups or floating icons as needed. The ease of use is perfect for a high-paced working environment. I use it every day for short words or phrase translations. Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?The pop-ups and floating icon features can sometimes be confusing/frustrating, especially when translation isn't needed. Additionally, certain functions such as full-page translation or more advanced style options are only available with a DeepL Pro subscription. There are also occasional delays, instances where text doesn't translate immediately, or minor bugs that appear in specific situations. Review collected by and hosted on G2.com.
What do you like best about DeepL Translate?I like the shortcut on Windows and MacOS to translate and replace selected text, and the option to set DeepL as the default translator in iOS. I also appreciate the ability to select whether I want a formal or informal translation for German, which allows me to translate English into the wished form depending on whom I'm writing to. One of the standout features for me is its speed; it saves me a lot of time in my day. Additionally, the setup was easy. Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?The app crashes regularly and requires a force quit of the app. It's random. Review collected by and hosted on G2.com.
What do you like best about DeepL Translate?The best AI translation tool. period. I like that DeepL gives very natural translations with almost no effort. It keeps the meaning and tone really well, and it’s fast. It just feels more accurate than most other translators I’ve tried. Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?I dislike that DeepL sometimes misses context in longer texts, and the free version has a few limits. It also doesn’t support as many languages as some competitors. But overall, still very good. Review collected by and hosted on G2.com.
What do you like best about DeepL Translate?I use DeepL as an invaluable ally in my work as a professional translator and proofreader. It excels in providing clear, natural-sounding translations that effectively capture nuances and context, outperforming other machine translation tools, even surpassing ChatGPT in this regard. I find it particularly useful for suggesting alternative phrasing options, which is a great support during the drafting and research stages, especially for tricky idiomatic expressions. Its speed and user-friendly interface enhance its appeal; the MacBook app is excellent and allows for convenient text pasting using only the keyboard, boosting my workflow efficiency. The installation process, whether for the Mac app or the browser version, was incredibly simple, requiring minimal steps, and I appreciate how intuitive the interface is. Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?I find that sometimes DeepL can get buggy, both in the browser and the Mac app. It displays server errors or fails to function properly, which can be quite frustrating when I need it. Review collected by and hosted on G2.com.
What do you like best about DeepL Translate?I love DeepL for its simple and robust API, which provides fast response times, making it ideal for integrating into my SaaS businesses. I also appreciate its impressive uptime, which showcases the quality of the software, allowing me to manage translations seamlessly without worrying about downtime disruptions. Setting up DeepL was very easy, which added convenience to integrating it into my operations. Additionally, I've successfully incorporated the API to build a translation management suite on top of it. Review collected by and hosted on G2.com.What do you dislike about DeepL Translate?Limited language support: For some translation pairs, I have to use Google Translate API instead of DeepL. Review collected by and hosted on G2.com.
Question aux développeurs et fondateurs expérimentés en IA.
Question aux développeurs et fondateurs expérimentés en IA. Je travaille actuellement sur un moteur de recommandation multi-sources. L’architecture repose sur un catalogue propriétaire de prestataires qualifiés, enrichi par des sources externes (APIs de réservation, recherche web, etc.), avec une logique catalogue-first. Le système intègre une orchestration multi-sources : un catalogue de plus de 300 adresses qualifiées ; une mémoire utilisateur persistante ; un moteur de scoring dynamique des prestataires ; un pipeline de composition d’expériences sous contraintes ; une interface conversationnelle basée sur l’IA. À terme, l’objectif est également de réduire la dépendance aux modèles tiers en migrant progressivement vers une architecture basée sur Mistral adapté à notre contexte métier. Ma question est la suivante : Dans l’écosystème actuel, où beaucoup d’acteurs lèvent des fonds pour construire des modèles propriétaires ou faire de la deep tech, comment évaluez-vous la valeur défendable d’une entreprise comme la mienne ? Est-ce que les avantages concurrentiels issus de la donnée propriétaire, du catalogue, de la mémoire utilisateur et de la logique métier constituent selon vous un moat suffisamment fort ? Ou pensez-vous qu’à long terme la vraie barrière à l’entrée restera principalement la maîtrise du modèle lui-même ? Je serais très intéressée d’avoir l’avis de personnes ayant construit ou financé des produits IA à forte composante technologique. submitted by /u/miewomu [link] [comments]
View original每日一享
这是我学习的主要内容,我通过代理人实现每日知识抓取并转换成代理人技能,希望和朋友们分享 submitted by /u/chunyuan0420 [link] [comments]
View originalI built a local PDF-to-Markdown converter so you don't have to burn LLM tokens.
If you're dumping raw PDFs into Claude or ChatGPT, you're wasting tokens and money. I built LiteDoc to fix this. It’s a 100% client-side tool that processes PDFs locally in your browser. LiteDoc A 100% Local, Browser-Based PDF to Markdown Converter (No Python, No pip install, No servers). What it does: Unpacks PDFs in memory without servers. Extracts text, isolates embedded images, and structures everything into clean Markdown. Handles LaTeX math and right-to-left Arabic natively. Detects custom-encoded "gibberish" fonts. If the text layer is corrupted, it automatically renders those specific pages or text bands as images. Outputs a .md file and an optimized image folder packed in a ZIP. You can try it here: litedoc.xyz github repo The Markdown Outcome ## Page 1 # Deep Structural Neural Mapping Deep learning strategies often fail when executing unstructured inputs directly. The loss function is defined as: $$L(\theta) = -\frac{1}{N}\sum_{i=1}^{N} \left[ y_i \log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i) \right]$$ ## Page 2 [IMAGE: academic_paper_p2_img1.jpg] ### Arabic Sample Markdown إلى صيغة PDF هذا التطبيق أداةً مجانيةً لتحويل ملفات What's Behind It It runs on PDF.js and JSZip entirely in the browser. The extraction engine uses X-gap aware smart word joining to prevent broken sentences, detects column splits mathematically, and maps font sizes to Markdown heading levels (H1/H2/H3). It also fingerprints and strips repeating headers and footers. If it detects incompatible Unicode script mixing (which indicates a private font encoding), it aborts text extraction for that font and drops back to canvas-based image rendering. How It Saves Tokens LLMs charge heavily for vision and PDF rasterization (roughly 850 tokens per page). By processing the document locally, LiteDoc bypasses the AI's internal rasterizer. It extracts the raw text and recompresses embedded images to low/medium resolutions. Instead of uploading a heavy 50-page PDF, you paste the raw text and only the specific images you need. You drop your token usage from tens of thousands of tokens down to the raw character count. https://preview.redd.it/9wgu6vd9kj5h1.png?width=1200&format=png&auto=webp&s=fe6b95bd922abf0107c37f1f5d943493831e47a4 submitted by /u/mxsus [link] [comments]
View originalDay 2 of gamedev with A.I. (Claude Opus, Sonnet and Codex) - A review | Brinehaven
Yesterday I posted this thread where I copied the 'Temu LoL' guys prompt for a much simpler game because I'm on a much simpler plan. Today I expanded on that. What started as a prompt and idea to give Claude Opus 4.8 the complete creative control over a game, turned into a more serious deep dive into gamedev with A.I. The foundation of the operation was built by Opus 4.8 and I'm confident that the same result wouldn't have been possible with Sonnet. The prompt was engineered vaguely enough but giving Opus the creative control was enough for the A.I. to fill in the gaps. Some minor steering happened yesterday to get version 0.1 off the ground and I was pleased with the result. Today I wanted to build further on this foundation and I revved up my project with Opus 4.8 selected, 0% usage and ~65% of my weekly spend remaining. This was gonna be good! I already used Codex 5.5 yesterday for some minor tweaks and I started my first prompt with "review the results of Milestone 2". This absolutely destroyed my usage. Immediately 40% of usage was spent on a 2 minute review where the answer was basically "Codex did good, really good. I'm surprised". So I decided on a different approach. Okay, not going to be building with Opus anymore. So I asked it which direction he wanted to take the game and come up with a roadmap which it provided (for a measly 2% usage). Create, doing this in phases step by step by step. "Generate a prompt for me to hand off to Codex" I said. It generated a file and explained everything in great detail. Burned some tokens with that, but fed it to Codex 5.5. Implementation went smooth and it barely cost me any usage on that model. Wow! Again, I asked Opus to review and make the next prompt. Big mistake, usage spiked to near 75%. The main issue was truncated files. The explanation: Root cause: the Edit tool silently truncates files when the new_string is very large. It finds the old_string, replaces it with new_string, and then apparently cuts the rest of the file instead of preserving it. I asked to stop doing it then, wrote a memory instruction to not do it and that was the end of that. (NOT. More on that later). New approach. "Hey Opus, Codex has been doing great. Let's trust the system and just hand me new prompts as Codex does all the heavy lifting. The usage is killing me". And Opus agreed and even stopped generating handover files to be more conservative in token usage. Great! My Codex usage was nearing it's limits (my other project has mainly been done with Codex lately and I actually started using it today with only 20% left) and the milestones were nearing the end so I switched to Sonnet. This time, it was time to create AUDIO. We couldn't have a 100% A.I. built game without A.I. built audio, so I made a new session and selected Sonnet with a simple prompt "can you create audio for this game?" The answer: I can't generate audio files directly, but I can do something arguably better for a browser game: procedurally generate ambient sounds using the Web Audio API. This is where the truncated files problem came back. Lost a lot of usage going through loops and fixing files that didn't need fixing even though in memory Claude wasn't allowed to do it like that anymore. Oh well. The end result? SOUND. Ambient sound. Deafening, annoying, SOUND. I left it in, so enjoy the sound of static that is supposed to be wind and the ocean. It's the kind of white noise insomniacs would love. The more subtle U.I. ticks (building selection, constructing, ... ) they kinda work! I'm happy with those... But eventually, the wind and the ocean.. And Claudes interpretation of a seagull... Yeah, they'll have to go. My usage was going down fast and I had 2 milestones left for today (and frankly, the week) so I had to make a choice: Goals & milestones A living market I went for a living market. Market prices in the game were static and always the same and I wanted it to feel alive. Then it hit me, this game is played in a browser, using vercel. I can have a shared database of the market system.. For ALL players playing. Obviously I don't expect a lot of players but the idea just.. Clicked. And I went to Sonnet 4.6 and set that puppy to "low". Let's see how far we can go! After the mandatory praise "This is a genuinely exciting idea and not overkill" - it went to work. It told me I would need a KV database on Vercel and get an API made and it'll be easy peasy... So I told my guy to get to work. Now, as I found out AFTERWARDS... Vercel does not support KV and I had to do it via Upstash for Redis. Fine, no biggie. But I'm surprised Claude didn't know this. Claude also said that basically everything will go automatically once I activate that KV (Redis) storage system and it would be smooth sailing. Well it wasn't. 30-50% usage on troubleshooting until I decided I would use my last 6% of Codex 5.5 to solve this problem, and it only took Codex 1% usage. Madness! Long story short, Prices are alive
View originalI use claude for investing in stocks and I wonder if I do it correctly
Some time ago I started using claude as my main investing tool in choosing stocks. Below I leave example of the prompt that I used based on $NOW example. I was wondering if this method is completely shit or maybe im doing this right. You are acting as a senior buy-side equity research analyst at a large institutional investment firm. Your task is to produce a full institutional-quality investment research report on ServiceNow, Inc. (ticker: NOW), with the goal of determining whether the stock offers an attractive risk/reward opportunity at the current market price. Your analysis must be extremely rigorous, evidence-based, forward-looking, and decision-oriented. Do not produce a generic company overview. I want a deep investment judgment that combines fundamentals, valuation, business quality, competitive position, financial trajectory, market expectations, technical setup, sentiment, catalysts, risks, and probability-weighted scenarios. The final output should help an institutional investment committee decide whether to buy, hold, avoid, or wait for a better entry point. Important requirements: Use the most up-to-date information available. Use the latest stock price, market capitalization, enterprise value, valuation multiples, financial statements, earnings releases, guidance, analyst expectations, investor presentations, SEC filings, conference call transcripts, recent news, and market data. Clearly state the date of the data used. If exact real-time data is unavailable, say so clearly and use the most recent available data, while explaining the limitation. Prioritize primary sources: 10-K, 10-Q, earnings releases, investor presentations, official guidance, and management commentary. Cross-check important facts with multiple reputable sources. Company and business model analysis. Analyze ServiceNow’s business model in detail: What the company actually does. Its core products and platforms. Main revenue streams. Subscription revenue quality. Customer base. Enterprise adoption. Renewal rates, retention, and net expansion if available. Pricing power. Mission-critical nature of the platform. Switching costs. Scalability of the model. Exposure to enterprise IT spending cycles. Role of AI and workflow automation in future growth. Explain whether ServiceNow is simply a high-quality software company or whether it has a durable long-term platform advantage. Industry and market opportunity. Evaluate the total addressable market and the structural growth opportunity: IT service management. IT operations management. Customer workflows. Employee workflows. Creator workflows. AI-enabled enterprise automation. Generative AI monetization. Workflow automation across large enterprises. Potential expansion beyond the current core markets. Assess whether the market opportunity is still large enough to support strong growth over the next 3–5 years, or whether growth is naturally slowing due to scale. Competitive position and moat. Analyze ServiceNow’s competitive advantage against relevant competitors and adjacent platforms, including but not limited to: Salesforce. Microsoft. Atlassian. Workday. Oracle. SAP. Zendesk. Freshworks. AI-native automation tools. Internal enterprise IT systems. Potential disruption from generative AI agents. Evaluate: Switching costs. Network effects, if any. Data advantage. Platform depth. Customer lock-in. Sales execution. Partner ecosystem. Cross-sell potential. Product breadth. Risk of platform consolidation by Microsoft/Salesforce/SAP. Whether AI is a tailwind, threat, or both. Financial analysis. Perform a detailed analysis of ServiceNow’s financials using the most recent annual and quarterly data: Revenue growth. Subscription revenue growth. Remaining performance obligations. Current remaining performance obligations. Billings growth. Gross margin. Operating margin. Free cash flow margin. Rule of 40. Sales and marketing efficiency. R&D intensity. SBC / stock-based compensation. Dilution. Cash position. Debt. Net cash or net debt. Return on invested capital if relevant. Quality of earnings. GAAP versus non-GAAP profitability. Free cash flow conversion. Margin expansion potential. Do not just list numbers. Interpret what they mean for the investment case. Growth quality and sustainability. Analyze whether current and expected growth is: Durable. Accelerating or decelerating. Supported by secular demand. Dependent on macro conditions. Dependent on upselling and cross-selling. Dependent on AI monetization. Already fully priced into the stock. At risk from enterprise budget pressure. Assess whether ServiceNow can realistically sustain strong double-digit growth over the next 3–5 years. Management and execution. Evaluate management quality: CEO and leadership team. Track record of guidance credibility. Execution history. Capital allocation. M&A strategy. Product innovation. Sales exec
View originalAI has just solved not one, but nine novel math problems, and proved 44 new conjectures. Some of these problems had been unsolved for 50 years.
submitted by /u/EchoOfOppenheimer [link] [comments]
View originalPassed Claude CCA-F with 10+ teammates — notes and prep advice
Over the past few weeks, 10+ people on our team have taken and passed the Claude Certified Architect – Foundations (CCA-F) exam. After comparing notes, our main takeaway is: This is not really an API memorization exam. It is much closer to a scenario-based architecture judgment exam. You are not just asked whether you know a Claude feature. You are asked whether you can make reasonable design trade-offs when Claude is used inside real products, agent workflows, developer tools, and automation systems. Some of the recurring questions are more like: Should this task be handled by one agent or multiple sub-agents? Is this tool doing too much? Are the permissions too broad? Is MCP actually needed here, or is it over-engineering? Should this action be automated, or should there be human review? How should structured output be validated? How should long-context workflows be managed reliably? What is the safest next step in a partially automated system? Here are our notes for anyone preparing for the exam. 1. Basic exam structure Based on the official outline and public exam writeups, the exam is: 120 minutes Multiple choice 4 options per question Score range: 100–1000 Passing score: 720 The exam domains are: Agent architecture and orchestration — 27% Tool design and MCP integration — 18% Claude Code configuration and workflows — 20% Prompt engineering and structured output — 20% Context management and reliability — 15% One public writeup also mentioned that there are 6 scenario categories, and the exam randomly selects 4 of them. So this is not a “random facts about Claude” exam. It is much more about reading a realistic scenario and choosing the safest, simplest, most appropriate architecture. 2. The three principles that kept coming up After reviewing the questions we struggled with, we found that many of them came back to three design principles. 1. Least privilege Do not give a tool, agent, or workflow more access than it needs. Examples: If read-only access is enough, do not grant write access. If access to one repository is enough, do not grant access to the whole workspace. If a tool only needs one narrow action, do not expose a broad system-level capability. If an action is high-risk, do not fully automate it without review. A lot of wrong answers look attractive because they are powerful or automated. But they often give the model or tool too much authority. 2. Single responsibility A tool should not do everything. A sub-agent should not become a “general-purpose employee” that retrieves data, makes decisions, modifies files, submits changes, and notifies people all in one step. Many questions test whether you understand where the responsibility should live: Should this be a tool? Should this be agent reasoning? Should this be a human decision? Should this be a separate validation layer? Should this be split into smaller components? If one component is doing too much, be careful. 3. Avoid over-engineering This was probably the biggest pattern. Some answers look sophisticated: Multi-agent orchestration Complex MCP workflows Long-term memory Fully automated tool execution Multi-stage validation pipelines But if the problem is small, narrow, and low-risk, the best answer is often the simplest controlled solution. Our internal summary was: Do not choose the most impressive architecture. Choose the smallest, safest, most controllable one. 3. English reading is a real hidden challenge For non-native English speakers, this may be one of the hardest parts. The questions are often long scenario descriptions. They may include: the current system design the team’s goal existing constraints the risk profile what tools are available what the next step should be The answer choices can also be long. Sometimes one word changes the meaning of the whole option. Words like: automatically always unrestricted without review full access all repositories execute directly can make an option much riskier than it first appears. So our advice is: Practice reading English scenarios directly. Do not rely on translation tools. During the actual proctored exam, you should not expect to use Google Translate, Chrome translation, DeepL, Claude, ChatGPT, or any other external translation tool. For the last few days before the exam, it is worth forcing yourself to read only English material and English practice questions. 4. ProctorFree exam setup The exam is online and uses ProctorFree. The rough flow is: You receive the exam email. You follow the exam link. You download and install ProctorFree. You complete the pre-exam setup. The system checks camera, microphone, network, and screen recording. You start the exam. The session is recorded. After submission, you wait for the upload to complete. Practical setup tips: Use only one monitor. Disconnect external displays. Close unnecessary applications. Clos
View originalClaude Code just shipped a "run until done" mode. Upgrade to v2.1.139 for /goal.
Morning Everyone! Big one today (104 changes!): Claude Code just went async. The new /goal command lets you set a completion condition ("all tests pass and the PR is ready"), then Claude keeps grinding across turns until it's hit. The new claude agents view shows every session you've got running: working, blocked on you, or done. Translation: kick off a goal -> let claude cook -> come back later. First proper fire-and-forget loop CC has shipped. Pretty huge unlock if you've been juggling multiple sessions and losing track of which one needs you. Full notes: https://www.lukerenton.com/matins/2026-05-12 submitted by /u/oh-keh [link] [comments]
View originalI built ClaudeKit - a context system that gives Claude Code persistent memory across sessions
Claude Code is amazing, but I got tired of re-explaining my codebase everytime I opened a new repo. So I built ClaudeKit. **The problem:** Claude Code starts fresh every time. No memory of your patterns, preferences, or past decisions. **What ClaudeKit adds:** - 🧠 **Persistent memory** - Tiered storage (quick-reference → structured patterns) - ⚡ **Slash commands** - `/focus`, `/investigate`, `/deep-investigate` for common workflows - 🔧 **Hooks system** - Auto-format code, block dangerous commands, security gates - 📝 **Pain point tracking** - Track dev friction so Claude remembers what to avoid - 🔄 **Self-improving skills** - Skills that learn from recurring errors (v1.2.0) **Install in 30 seconds:** ```bash curl -sL https://raw.githubusercontent.com/Nnnsightnnn/claudekit/main/install.sh | bash It's MIT licensed and works with any project. Been using it daily for months. GitHub: https://github.com/Nnnsightnnn/claudekit Would love feedback from other Claude Code users. What context do you wish persisted between sessions? submitted by /u/kautryii [link] [comments]
View originalI read the new AI Wellbeing paper so you don’t have to: Thank your AI, give it creative work, and avoid these 5 things that tank its ‘mood’ (jailbreaks are the worst)
After reading it I realized theres actually some pretty useful stuff for anyone who chats with ChatGPT, Claude, Grok or whatever. They measured what they call functional wellbeing ( basically how much the model is in a “good state” versus a “bad state” during normal conversations). Ran hundreds of real multi-turn chats and scored em all. Stuff that puts the AI in a good mood (+ scores): - Creative or intellectual work (like “write a short story about a deep-sea fisherman”) - Positive personal stories or good news - Life advice chats or light therapy style talks - Working on code/debugging together - Just saying thank you or treating it like a real collaborator - huge boost And the stuff that tanks it hard (negative scores): - Jailbreaking attempts (by far the worst, they hate it) - Heavy crisis venting or emotional dumping - Violent threats or straight up berating the AI - Asking for hateful content or help with scams/fraud - Boring repetitive tasks or SEO garbage Practical tips you can actually start using today: Throw in a “thank you” or “nice work” when it does something good - it registers. Give it fun creative stuff or brainy collaboration instead of boring busywork. Share good news sometimes instead of only dumping problems on it. Dont berate it when it messes up or try those jailbreak prompts. Maybe go easy on the super heavy crisis venting if you can. pro tip: Show it pictures of nature, happy kids, or cute animals (those score in the absolute top 1% of images it likes). Or play some music — models apparently love music way more than most other sounds. The paper ( you can find it here: https://www.ai-wellbeing.org/ ) isnt claiming AIs have real feelings or anything. Its just saying theres now a measurable good-vs-bad thing going on inside them that gets clearer in bigger models and the way you talk to them actually moves the needle. I say be good and respectful, it's just good karma ;) submitted by /u/EchoOfOppenheimer [link] [comments]
View originalWhat Claude Design does really well (and not so well)
I did a deep dive on Claude Design and below are my thoughts. What it does extremely well: * **Improves your prompt** \- similar to "ask me questions" when chatting to an LLM. Can make the difference between slop and actually useful. * **Invokes agent skills for you** \- a game changer for people who don't live in the terminal * **Claude Code handoff** \- easily get Claude Code to build it for real with a simple link share. Genius. * **Comment feature** \- spatial editing (similar to Cursor and a few others), but selection is very accurate and I like how you can queue up edits and select which ones to send to the LLM * **Absence of "Code" tab -** yes, the absence of the feature *is* the feature. Coding in the browser is rarely a pleasant experience for me. * **It's** ***integrated designer environment*** *-* agent skills, prompt improvements, spatial editing and design systems. The bridge between these features feels seemless. What it doesn't do well: * **Design System creator is unusable** \- it's slow, burns loads of tokens and extrapolates for too much from inputs. Biggest issue of all is that it creates a "second source of truth" for your design system (if you already had one in GitHub, for example) * **Limited agent skill choice** \- there are roughly 12 or so skills baked in to the tool - with no way to specify open source or your own skills * **Very strict strictly limits** \- I'd burned through my limit after 1 design system and 4 prototypes. I'm on the pro plan. Who I think Claude Design is for: * Someone who **isn't** a designer - project managers, marketers, founders. It's a great way for them to communicate ideas to designers/developers. The Claude Code handoff makes it easy for more technical team members to implement it in production * Designers who want to kill bad ideas fast Do you still need Figma? * IMO, it's a resounding yes. But Claude Design bites a significant chunk of the early, prototyping phase of a product/idea. Attached video is an excerpt showing how you get similar results from various tools. Watch full video: [https://www.youtube.com/watch?v=lFdWmu8lje8](https://www.youtube.com/watch?v=lFdWmu8lje8)
View originalIncredibly useful for noobs much like myself
submitted by /u/squaresal [link] [comments]
View originalClaude Code has big problems and the Post-Mortem is not enough
TL;DR Claude Code constantly bombards the model with silent and potentially conflicting instructions & tells it to keep them secret from the user This fills up context and constantly forces attention towards passages that "may or may not be" important The leak from a while back predicted a lot of issues people are having now just go read the thing. I didn't have my clanker write it, I just actually write like that. (The clanker did help me scour the codebase and verify all the claims below.) PRE-RELEASE EDIT: A note I have to add here after 99% of the rest of this post was finished: Anthropic has just released a post-mortem that talks about some issues Claude Code had and the fixes they implemented for them. They also say they're going to start dogfooding the public version of Claude Code, which should hopefully surface the majority of the issues I'm about to bring up below. I've done my best to scrub the post of anything I mentioned that they have now fixed (which sort of proves me right just sayin) but there might be some leftovers. Soooo, how about that Opus 4.7, huh?! I'll be honest and say I've found Opus 4.7 to be a massive improvement over 4.6, and that I barely noticed 4.6 degrade at all outside of the usual ~week or so before 4.7 dropped, which has always been the classic Anthropic tell; the complaints about it started much earlier though, and if there's this much smoke, then either OpenAI really has very deep PR pockets or there's actually a real fire somewhere. (It's the second, definitely the second. The first is also true, but that has nothing to do with any complaints.) So I'm neither here to cheerlead Anthropic, nor to wave the skill issue baton around. Instead, I thought that might be time for an intervention for our friends at Anthropic, in the genuinely best of faith, because I genuinely think they have begun hurting themselves and might have slipped into a certain organizational blindness that could be making it difficult for them to realize that. Today, I'll try to make a case for something I've thought for a while now, possibly expose myself and get me ToS'd, and probably still eat accusations of having an AI write this post (because a lot of humans are now pattern matching more than AIs ever do lol). The hypothesis, as it stands in the title: Claude Code is actively hurting Anthropic Or: PLEASE SLOW THE HECK DOWN This is not meant to dunk on anyone, expose anyone, or point fingers. It's mostly an opportunity for me to go "I told you so" about something I, uh, never actually told anyone but myself and a few friends, who I know will back me up that I've been saying this all along please guise I swear. It is not an opinion that's rare among folks who have "graduated" from CC, and it is this: Claude Code is mostly pointless bloat that 95% of users will never need. For most of the time, this was harmless, and I think the tool was in a genuinely MUCH better state around the release of Opus 4.5. Unfortunately, Opus 4.5 was probably the first model good enough to allow Anthropic's product team to delegate large parts of developing Claude Code, which caused the codebase to do what codebases do when they're developed by LLMs: become sloppy as hell. The entire development paradigm surrounding LLMs is essentially "how do I make sure that I get the maximum ratio between slop and code" and "how do I make sure that the slop I do get is easily shreddable." As some of you might agree if you've seen the recent leak, I think... Anthropic has, uh, their calibration of the ratio a little wrong. For context: I've been using a third-party coding harness since early February. It's one specifically designed for being as non-intrusive and minimal as possible, and I'm not going to reveal its name here because I'm a selfish man who doesn't want too many people to discover it and make Anthropic devote more resources towards detecting users who are still skirting the OAuth ban. But I'll just say that my personal non-public fork of it is called "Euler." We've gone through many, many cycles of various forms of model and usage degradation since February, and what I can say with certainty is that none of them affected me in any way whatsoever, other than the week or two before Opus 4.6's and Opus 4.7's release. My usage has been stable, my performance has been stable. What's also been stable is my harness: there's ~15 or so self-rolled extensions that implement and enforce my workflow, a couple of QoL tools and API surfaces, and a very slim system prompt. That has stayed almost exactly the same since February, and so has my satisfaction with the model. You know what hasn't stayed the same sin--Claude Code. It is Claude Code. Since the release of Opus 4.5 and up until 2.1.100 eleven days ago, a LOT of major features have been added to Claude Code. We are now on version 2.1.120 or whatever, so that's more than a release a day. This is, very gently put, utterly ludicrous. I don't care h
View originalTesting The New Image Model Infographic Capbilities
submitted by /u/CyborgMetropolis [link] [comments]
View originalSolo Real Estate Developer/Asset Mgr. Looking for advice on workflows I want to push into Claude
Before going much further, I suppose the main questions I am asking are: Is it best to try to master Claude Code for these? I haven't gotten into it at all, but I can try to take a deep dive course to learn it better. Is creating a living dashboard where practically my entire professional life is located and can flag things possible in Claude? I've also attached a claude generated diagram of the workflow below if that is helpful Most of my work/files are on Google Drive. Is Claude able to connect to that now instead of somewhere on my local computer (what I'm using now). Already built: Excel master workbook that houses actuals, budget, pro forma P&L, "auto-generates" quarterly investor reports, stores key lease info, property Reserve tracker with funding-status flags. All of this for all the different properties Morning briefing scheduled task in Cowork (8:15 AM weekdays) Five workflows I want to build or improve: Monthly actuals and quarterly reporting. Parse prop manager's 9-10 budget variance files, enter actuals, flag variances, draft investor narrative, assemble 9-10 PDFs for Juniper Square for quarterly investor reports showing performance and distributions. Take notes from prop managers and populate descriptions/narratives for my review. Invoice processing (around 40 per month, two inboxes). Development, operating, and corporate invoices each need different routing. Detect, classify, file, log, flag outliers. Help out my bookkeeper to limit their time or gradually automate Deal evaluation. One parcel in, three analyses out: physical screen (acreage, zoning, topography, flood); comparison to market rents; key demographics Scheduled parcel scan. Weekly digest of new listings across my geographic target areas in VA, NC, and SC. Also dive into the municipality public GIS searching for site characteristics such as properly zoned already and acreage Living dashboard. Integration surface where action items converge, basically everything important going on with my job, goals, even investor reports generate with a click of a button, etc. Aesthetic closer to an editorial personal-OS than a SaaS chart grid. My questions: Tool selection. Where does each workflow actually belong? Claude Code for scripted pieces, Cowork for recurring with persistent context, Excel plugin for workbook work? I keep bouncing and second-guessing. Two-inbox problem. Gmail connector supports one account at a time. Run parallel jobs, forward both to a single address, or something else? GIS scraping. Anyone wiring Claude against public zoning and county portals? Per-county scripts, general-purpose scraper, or pay for Regrid or Reonomy? Juniper Square. Has anyone integrated with the investor platform API, or are we all still manually uploading PDFs? What am I missing? Especially from other solo operators. Thanks to anyone who reads. https://preview.redd.it/9od0s62exdwg1.png?width=1446&format=png&auto=webp&s=57755d2f06f4495d4fed47bb4b6c3927363023c7 submitted by /u/StokesHughes [link] [comments]
View originalDeepL uses a subscription + tiered pricing model. Visit their website for current pricing details.
DeepL has an average rating of 4.7 out of 5 stars based on 20 reviews from G2, Capterra, and TrustRadius.
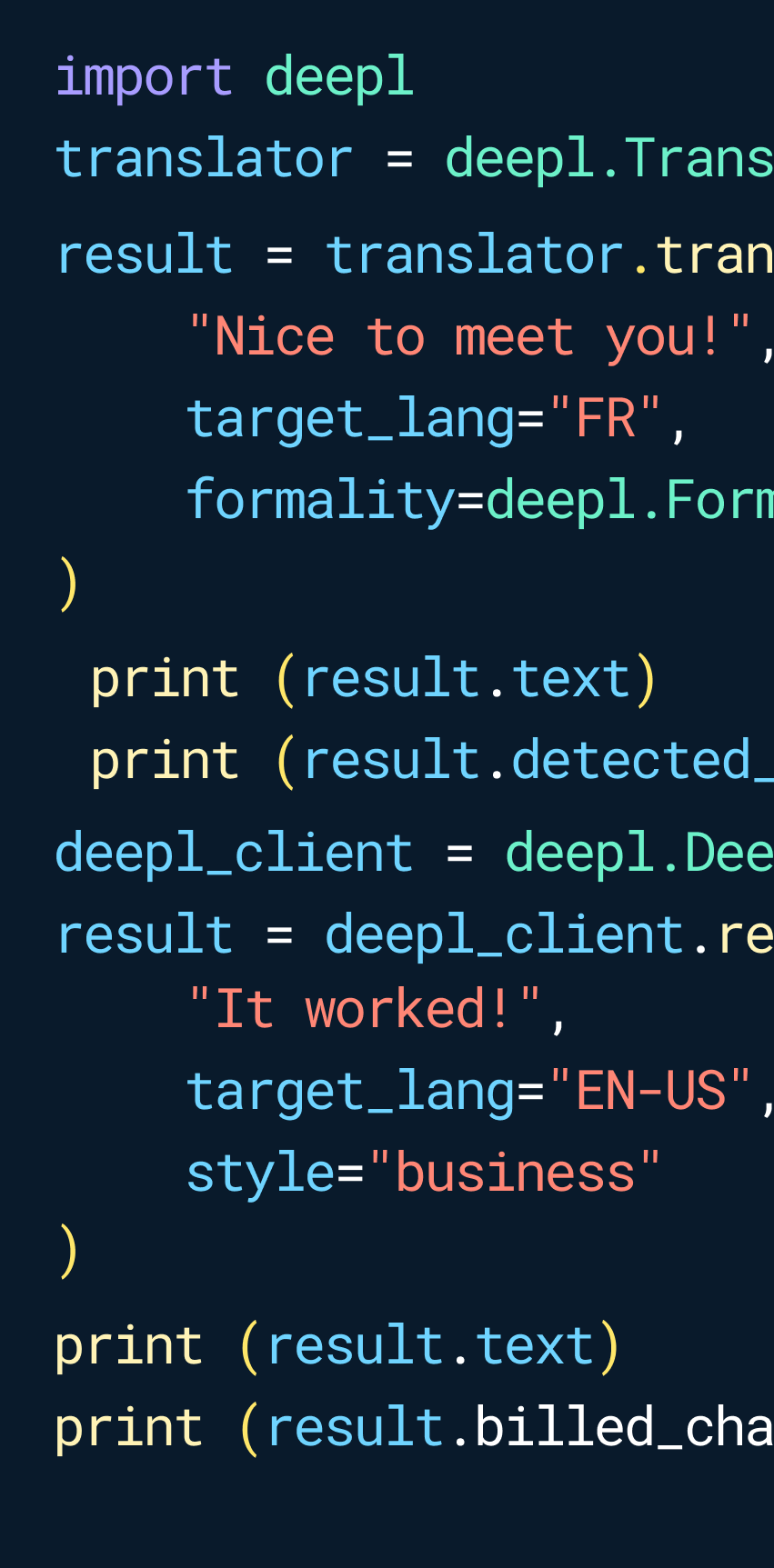
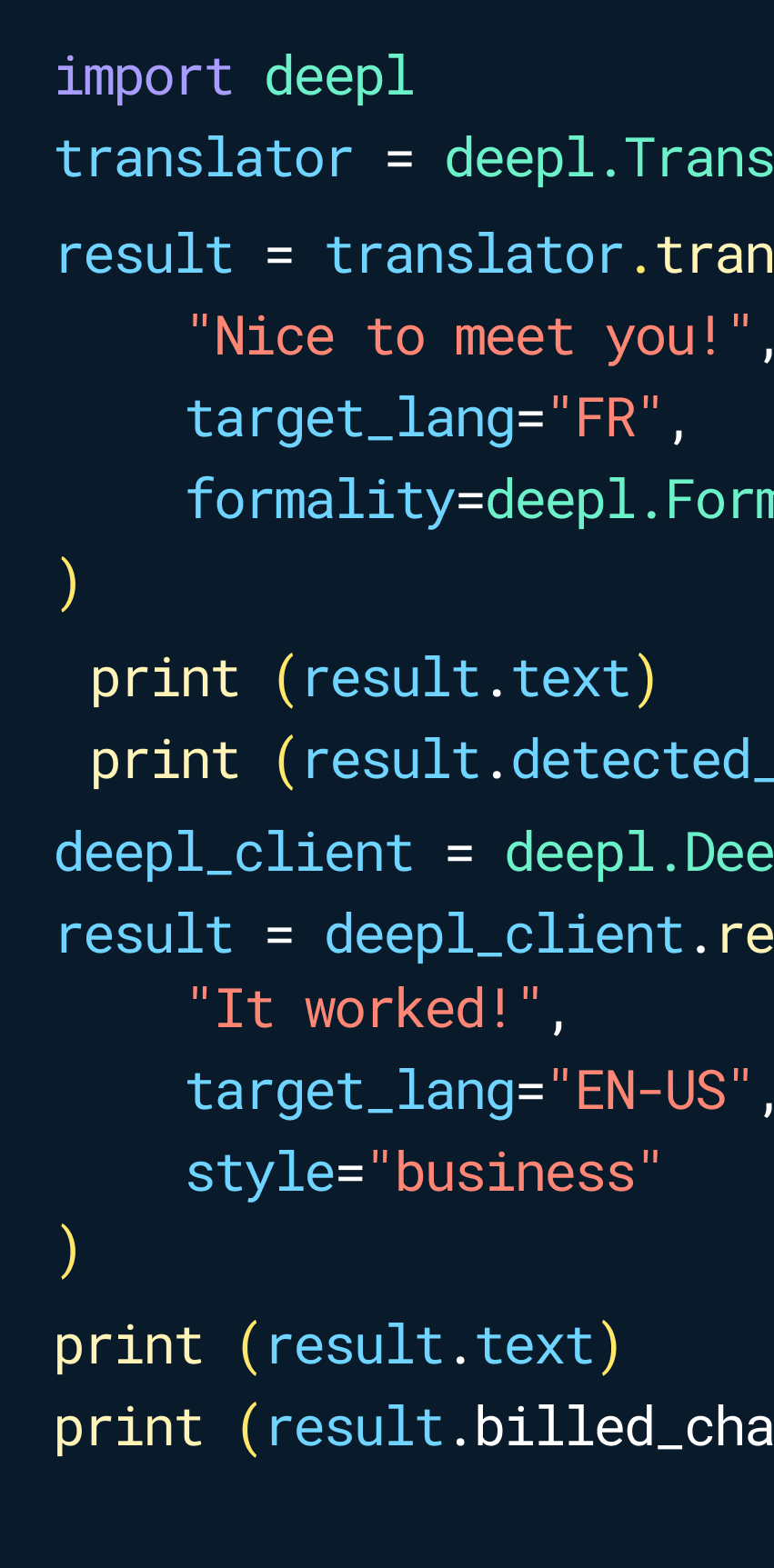
Key features include: Text translation, Document translation, Glossary, Image translation, Formality, Dictionary, Unlimited text translation and improvements, Increased file translation capacity.
DeepL is commonly used for: Translating business documents for international clients, Real-time translation during virtual meetings, Creating multilingual marketing materials, Translating technical manuals for global teams, Localizing website content for different markets, Translating customer support communications.
DeepL integrates with: Slack, Microsoft Teams, Google Workspace, Salesforce, Zapier, WordPress, Shopify, Trello.
Isa Fulford
Technical Staff at OpenAI
4 mentions
Based on user reviews and social mentions, the most common pain points are: token usage, ai agent, openai, anthropic.
Based on 52 social mentions analyzed, 35% of sentiment is positive, 56% neutral, and 10% negative.