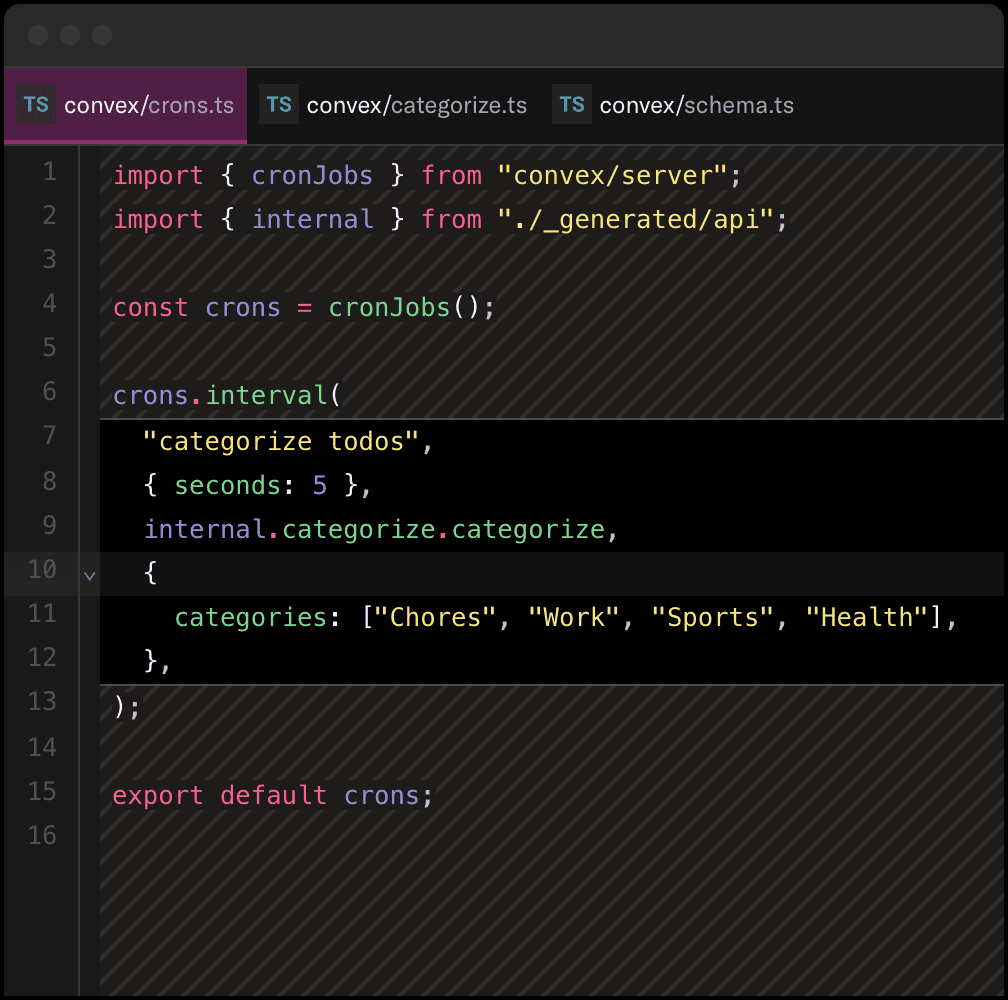
Convex provides the backend building blocks for your agents. Everything you need to build your full-stack project.
Users generally appreciate Convex for its ease of use and the ability to quickly bridge complex systems, like integrating with production databases using Python. However, a significant complaint is the limitation of its self-hosted backend being single-node only, necessitating manual code modifications for horizontal scaling. While specific pricing sentiments are not extensively mentioned, the tool tends to cater to tech-savvy individuals who are comfortable tweaking it to fit their needs. Overall, Convex is seen as a robust solution for those looking to seamlessly integrate databases with AI-driven workflows, though with some constraints that may affect scalability.
Mentions (30d)
1
Reviews
0
Platforms
2
GitHub Stars
11,047
659 forks

Users generally appreciate Convex for its ease of use and the ability to quickly bridge complex systems, like integrating with production databases using Python. However, a significant complaint is the limitation of its self-hosted backend being single-node only, necessitating manual code modifications for horizontal scaling. While specific pricing sentiments are not extensively mentioned, the tool tends to cater to tech-savvy individuals who are comfortable tweaking it to fit their needs. Overall, Convex is seen as a robust solution for those looking to seamlessly integrate databases with AI-driven workflows, though with some constraints that may affect scalability.
Features
Use Cases
Industry
information technology & services
Employees
41
Funding Stage
Series A
Total Funding
$53.2M
1,992
GitHub followers
175
GitHub repos
11,047
GitHub stars
20
npm packages
Pricing found: $0/month, $25, $2,500, $2.20, $2
Someone caught Fable leaking its unfiltered inner voice, and it's just muttering and grumbling to itself the whole time
submitted by /u/KeanuRave100 [link] [comments]
View originalMultivariate Probability Models in Machine Learning.
Hello Folks, Have you ever wondered why we use sigmoid function so often in Machine Learning? Although it gives us a probability, it comes from Exponential families, and this exponential family, subsumes many of the distributions, that we study in Machine Learning. In this lecture, we understand exponential families, Directional derivatives(Gradients and Hessians), study mixture Models, and understand how domain knowledge in Probabilistic Graphical Models makes our life simpler to model joint probability densities. Timeline breakup(in hours and minutes): 0:00-0:17 - Understanding exponential families. 0:17-0:27 - Deriving Sigmoid Function for Bernoulli. 0:27-0:48 - Understanding log partition function, convex functions and proving why positive definite of hessians imply convexity, and why convex needed? 0:48-1:04 - Directional derivates(deriving gradients and hessians) 1:04-1:26 - Maximum entropy derivation of the exponential family. 1:26-1:56 - Mixture Models(Gaussians and Bernoulli Mixture Models) 1:56-2:16 - Probabilistic Graphical Models 2:16-2:34 - Markov Chains 2:34-End - Inference and Learning, Plate Notation diagram of Gaussian Mixture Models. If you have watched earlier of my lectures from the playlist, they will help. I try explaining as if I am a learner, to simplify complex concepts. Everything I write in whiteboard, and these are completely FREE lectures to mention. Link: https://youtu.be/T1uTBtJ7aHU?si=rozXSTjtSqPaaYb5 submitted by /u/Negative_War_65 [link] [comments]
View originalMathematical Foundations towards Machine Learning.
Hello Folks, one of the efficient ways of learning bigger topics in Machine Learning, is to modularise, and structure, so that the content becomes digestible for learners community. My free lecture content includes the following topics so far: (Playlist) a. Introductory Machine Learning Concepts:- What is ML actually? Supervised Machine Learning. How do classifiers learn? Empirical Risk Minimization. Uncertainty Modelling in ML. Maximum Likelihood Estimation. Regression Basics and Outliers. Deriving Mean Squared Error. Polynomial Regression. The Power of Convexity. Deep Learning Intuition. Overfitting Models from Generalization Gap perspective. Requirement of Test Sets. The No Free Lunch Theorem. Unsupervised Learning basics. Discovering latent factors of variation. Evaluating Unsupervised Models. Self-Supervised Learning. Image and Text Benchmarks in ML Discrete Data and Text Processing Feature Engineering, TF-IDF Handling missing data & AI alignment. b. Probability Foundations for ML: Univariate Models: Frequentist vs Bayesian. Probability as an extension of Boolean Logic. Discrete Random Variables. Continuous Random Variables. Quantiles. Sets of Related Random Variables. Moments of Distribution. Variances and Mode. Conditional Moments. Conditional Variance. Foundations of Bayesian Rule. Confusion Matrix Explained. Monty Hall Problem and Inverse Problems in ML. Bernoulli and Binomial Distributions. Sigmoid(Logistic) Function. Properties of Sigmoid Functions. Categorical and Multinomial Distributions. Softmax Function: Temperature explained. Log-Sum Exp Trick. Gaussian Distribution. Regression from the lens of Conditional Gaussian. Dirac Delta Function and Sifting Property. Student-t distribution. Laplace and Cauchy distribution. Beta distribution. Gamma distribution. Exponential, chi-squared and inverse Gamma. Empirical distribution. Transformations of Random Variables. Invertible Transformations. Multivariate Transformations. Moments of Linear Transformation. Convolution Introduction. Convolution Theorem explained with probabilities. Moment Generating Functions. Deriving Moment Generating Functions. Central Limit Theorem Explained. Understanding Monte Carlo approximation with Example. c. Probability Foundations for ML: Multivariate Models The Math of Depedence: Covariance Explained. Correlations: Normalized Measure of Covariance. Correlations does not imply Independence. Simpson’s Paradox: When Data misleads. Multivariate Gaussian Distribution. Analyzing level sets of Gaussians using Mahalanobis Distance. Multivariate Gaussians: Conditionals and Marginals. Math behind Bayesian Inference : Schur complements. Deriving Conditional Gaussians. How to Predict missing data? Modelling Linear Gaussian Systems. The Bayes Rule for Gaussians. Understanding Shrinkage: Inferring Unknown Scalars Posteriors, Sequential Posterior Updates. Inference of an Unknown Vector. Sensor Fusion concepts. And many more topics to come ahead. I have tried teaching from intuitions and mathematics, building everything by writing on whiteboard so that learners see the full development. submitted by /u/Negative_War_65 [link] [comments]
View originalI built a Laravel package that turns your app into a database-backed personal knowledge vault (Obsidian style) with a 16-tool MCP server
Hey! I'm the author. laravel-commonplace is a database-backed personal knowledge vault you install into an existing Laravel app. Adjacent to Obsidian, Logseq, and Notion as personal-knowledge tooling, except the storage layer is your existing Laravel app's database instead of files on disk or a third-party SaaS. Notes are Eloquent models in your DB, gated by your app's auth, shareable per-user via an owner plus Share model. It ships a browser UI (editor, graph view, search, journal) and an MCP server with 16 tools. If you have a Laravel app, the MCP server lets Claude Desktop, Claude Code, Cursor, Zed, Continue, Cline, Pi, or any other MCP client read and write your notes as the host app's user. Default middleware is auth:sanctum (Bearer PAT), and every tool resolves to $request->user(). There's no synthetic agent identity to provision, scope, or revoke separately. The agent gets exactly what the user gets, evaluated against the same Policies the controllers already use. Session, Passport, and OAuth-DCR are all configurable if PAT isn't what you want. The 16 tools, grouped: CRUD: create-note-tool, read-note-tool, update-note-tool, edit-note-tool (surgical find-and-replace), delete-note-tool (history preserved), move-tool (rewrites referring wikilinks). Discovery: list-tool (folder/tag/visibility filters), search-tool (substring), semantic-search-tool (embedding search), suggested-links-tool (embedding-similar notes not yet linked). Graph: backlinks-tool, neighborhood-tool (N-hop traversal), shortest-path-tool (chain between two notes), hub-notes-tool (most-connected), orphan-notes-tool (no inbound or outbound links). History: history-tool (version snapshots, survives deletion). On the semantic tools: the vector driver defaults to in_php_cosine for portability across SQLite, MySQL, and Postgres. If you're on Postgres, switching to the pgvector driver gets you indexed similarity and removes the in-PHP candidate cap. You swap it with a published migration and an env flag, and the docs recommend it once you're past a couple thousand notes. The tools live in src/Mcp/ if you want to see how a multi-tool MCP server is wired into a Laravel app. Caveats: Pre-1.0 (v0.2.0). APIs may shift before 1.0. Laravel-only by design. The whole point is reusing the host app's DB and auth. MCP is off by default. One env flag turns it on. Operator decision. Prompt injection through note content is the unsolved hard part. Notes are untrusted text, and notes other users share with you can carry instructions an agent might follow. The package doesn't pretend to solve this. The threat model at docs/threat-model.md says what's mitigated and what isn't. No per-tool capability gating yet. Enabling MCP enables all 16 tools the user is otherwise allowed to invoke. It's named as a limitation in the threat model. Feedback I'd actually use: Laravel folks who install it and tell me where it breaks, and anyone who reads the threat model and finds a hole I missed. Repo: https://github.com/non-convex-labs/laravel-commonplace submitted by /u/aaddrick [link] [comments]
View original4 files that made my Claude Code prod-database write boring
Late April. The "agent deleted prod DB" thread was making the rounds and the fear was real. The next week, I shipped a Python bridge to my own Convex prod database. Stdlib Python. 10-minute systemd timer. Live since 2026-05-06. No incidents logged so far. Claude Code didn't make it safe by improvising. The substrate did. The substrate is four files I keep in the working context. Identity and memory load by default. The other two are where the agent goes when the task calls for them. ~/projects/agent-os/CLAUDE.md is the load-bearing identity file. Who I am, what I sell, who I sell to, 90-day priorities. The agent doesn't ask. It reads. ~/.claude/projects/-home-jon/memory/MEMORY.md is the auto-memory index. User profile, feedback rules, project state across sessions. The agent doesn't relearn me every conversation. references/framework.md is the operator playbook. How decisions get made, what to optimize for, what holds the rest together when the work scales. decisions/log.md is the append-only why-log. Reversible decisions get one line. Load-bearing ones get the full receipts. Future me reads it. Future agent reads it. The bridge itself is scripts/skool_sheets_to_convex.py. Stdlib Python, deterministic. The agent calls it but did not generate it on demand. Prod writes need SKOOL_ALLOW_PROD_WRITES=1 plus a 401-preflight against an allowlisted Convex deployment slug. Composite idempotency key {tab_slug}:{normalized_transaction_id}. Redacting logger strips email-shaped substrings and known secret prefixes before any line hits the journal. The spec for all that lived in references/skool-api.md before any code existed. Codex reviewed it twice. First pass killed a cookie-auth approach that would have violated Skool's ToS. Second pass drove the prod-write guard. Both passes still missed an inferred field assumption. The dry-run caught it. The cache had a quieter bug, too. The initial _read_json swallowed JSONDecodeError and returned an empty dict. Under the corruption test in the verification checklist (deliberately corrupt the cache, run the bridge, see what happens), it would have silently rebuilt the processed-events cache and double-POSTed every prod row that had already been posted. Caught and fixed before the canary ran. None of those guardrails came from the agent improvising. They came from the spec. The spec came from research. Research came from a workflow rule in memory: research, planning, spec, implementation, with Codex adversarial review at each phase. The agent doesn't relearn that every session. It just does it. If you're going to copy one piece, copy connections.md. Knowing what your Claude setup can actually reach is the cheapest unlock. You'll build everything else against it. More context, with the full layered breakdown and worked example. submitted by /u/SquareFew6803 [link] [comments]
View originalI just scaled Convex's open-source database horizontally using Claude Code. I don't write Rust and I barely understand database internals.
So I've been using Convex for a while and the one thing that bugged me is that the self-hosted backend is single-node only. Their docs literally have this line: "You'll have to modify the code to support horizontal scalability of the database, or swap in a different database technology" Nobody had actually done it. So I decided to try. For context, Convex isn't like a normal database. It's a reactive database that has things no distributed database has all together: • Real-time WebSocket subscriptions (push updates to clients instantly) • In-memory snapshot state machine (the whole live database sits in memory) • Optimistic concurrency control with automatic retry • TypeScript/JavaScript function execution (your backend logic runs inside the database) • ACID transactions CockroachDB doesn't have real-time subscriptions. TiDB doesn't have in-memory snapshots. Vitess doesn't have OCC. Spanner doesn't run your application code. Convex has all of them — but couldn't scale past one machine. The problem is the entire backend is written in Rust and I don't write Rust. I also didn't know anything about distributed systems, Raft consensus, two-phase commit, or how databases like CockroachDB and TiDB actually work under the hood. So I used Claude Code (Anthropic's CLI tool) for the entire thing. I basically told it what I wanted, it researched how the big distributed databases solve each problem, and then implemented it. I pushed back when things looked too simple, asked it to explain decisions, and made it redo things when I didn't like the approach. What we ended up building: • Read scaling — multiple nodes serve queries via NATS JetStream delta replication • Write scaling — tables partitioned across nodes (like Vitess), with two-phase commit for cross-partition writes • Automatic failover — tikv/raft-rs consensus per partition, sub-second leader election. Kill any node, writes resume on the new leader • Persistent Raft logs — TiKV's raft-engine (they moved away from RocksDB for this because of 30x write amplification) • Global timestamp ordering — batch TSO from TiDB's PD pattern, zero network calls in the hot path • 87 integration tests — patterns from Jepsen tests that found real bugs in CockroachDB, TiDB, and YugabyteDB Every engineering pattern came from studying how CockroachDB, TiDB, Vitess, YugabyteDB, and Google Spanner solved the same problems. Nothing was invented — it was all researched from how the giants do it and then applied to Convex's unique architecture. You can run the whole thing with one command: docker compose --profile cluster up 6 nodes (2 partitions × 3 Raft nodes), automatic leader election, all nodes serve reads, kill any node and it recovers in ~1 second. Images published to GitHub Container Registry — no local build needed. Repo: https://github.com/MartinKalema/horizontal-scaling-convex I'm not claiming this is a breakthrough — every individual technique already existed in production at these companies. But nobody had combined them for Convex before, and the challenge was keeping all the things that make Convex special (subscriptions, in-memory OCC, TypeScript execution) while adding horizontal scaling on top. I genuinely could not have done this without AI. The entire codebase is Rust and I've never written a line of Rust in my life. Claude Code wrote every line of Rust, researched every distributed systems pattern, and debugged every failure. I directed the project, made the product decisions, and kept pushing for the proper engineering approach. Curious what people think. Is AI-assisted systems engineering like this going to become normal? Would love feedback on the architecture from anyone who actually works on distributed databases. submitted by /u/CourageCareless3219 [link] [comments]
View originalImmediately Revert Update - Stop with Emojis
Claude started writing with emojis just like ChatGPT. Stop it. ChatGPT went downhill hard after they did that. This screams unprofessional - something Claude stood out for. Instead of introducing dumb ass emojis, how about you fix markdown and katex/latex embedding. Claude keeps having these rendering issues with markdown recently and latex in blocks ie $$...$$ also only renders correctly 70% of the time because Claude keeps putting newlines into these blocks which doesnt work. https://preview.redd.it/dowulrpm1srg1.png?width=1314&format=png&auto=webp&s=0f0883966081f7c237dc0170c9142a0b51a2e6a8 submitted by /u/Bravo6GoingDark__ [link] [comments]
View original[Day 2/5] I built a SaaS using an AI coding assistant. Here is exactly how that works and where it breaks.
Yesterday I posted Day 1 of this series — the origin story and numbers from a 129-location franchise project. Got some solid feedback, including someone pointing out my mobile layout was broken and my site was crashing. They were right on both counts. Fixed it that night. Today: how the thing actually gets built, what works, and where it completely falls apart. The stack: Next.js 16 (App Router) — file-based routing, React ecosystem Convex — real-time database with WebSocket subscriptions. When a lead's intent score goes from WARM to HOT, every connected client sees it instantly. For speed-to-lead, real-time isn't optional Clerk for auth — org management, role-based access, webhook sync to Convex Railway for hosting — push to deploy I picked each piece because it handles a complete domain. I describe features in plain English, Claude Code writes the implementation. If I'm spending time debugging OAuth flows instead of product logic, I've picked the wrong tools. What works: Describing features and getting working code in minutes. "When a lead crosses the HOT threshold, send a push notification to the nearest sales rep with tap-to-call and a personalised call script." Schema changes, API endpoints, UI — done. The throughput on product-level code is 10-20x what hiring would give me at this stage. Where it falls apart — deployment: Feb 26 was my worst day. 40 commits. Most were fixes. Railway needs standalone Next.js output for Docker. The build succeeded locally but failed in production because of a manifest file Railway couldn't resolve. Spent the entire day on output configs and middleware edge cases. The AI can't SSH into your container. Can't read runtime logs. When the deploy pipeline is the problem, you're on your own. The site went down for 4 days. I didn't know. No monitoring, no alerts, and I was testing locally. Found out when I tried to demo to a prospect. The fix was one line. Four days of downtime for a one-line fix. Auth was rewritten 4 times: Clerk handles auth, Convex handles the database. They sync via webhook. Simple in theory. Iteration 1: worked in dev, broke in production. JWT issuer domain was different between Clerk's dev and prod instances. Iteration 2: fixed JWT. New problem — race condition. User signs up, redirects to onboarding, but the webhook hasn't arrived. Database says "who are you?" two seconds after account creation. First impression destroyed. Iteration 3: polling. Check for the user record every 500ms for 10 seconds. Worked but felt terrible. Iteration 4: restructured everything. Onboarding creates the user record using Clerk's session data. Webhook becomes a sync mechanism, not the creation path. Finally solid. Four iterations. Each half a day. Each time I was sure it was done. Someone in yesterday's comments asked about schema sprawl — fair question. Started at 20 tables, now at 39. Here's what forced the growth: leadEvents: needed every interaction tracked — page views, clicks, form abandonment — to build an accurate intent score. One table became two shiftSchedules + centerHours: can't alert reps at 2 AM. Shift-aware routing wasn't optional achievements + leaderboardEntries: gamification was scope creep. But 5 reps competing to respond fastest? A leaderboard is the cheapest motivation tool there is boostSites: AI scans a prospect's website and shows exactly what SignalSprint would add. Became the best sales tool in the stack Every table exists because something broke without it. But yeah, 39 is a lot. Some of it could probably be consolidated. What I'd tell anyone building with AI tools: Pick a stack where each piece owns a domain. Don't build your own auth or real-time layer Test everything. Click every button. Try to break it. The AI writes code that looks right and breaks in production Deployment is where AI help drops to near zero. Budget 3x the time One person flagging your mobile layout is worth more than a week of building features. Ship early, take the punches Tomorrow: the rebrand, the Stripe bugs, and the emotional part nobody posts about. TL;DR: Building with Claude Code. 391 commits, 39 tables. AI is 10-20x faster on product code. Useless for deployment. Auth rewrote 4 times. Site down 4 days and I didn't know. Someone told me my mobile layout was broken yesterday — they were right. Ship early, fix fast. submitted by /u/powleads [link] [comments]
View originalI shipped a production SaaS with 39 database tables using Claude Code. I am not a developer. Here is what actually works and what breaks.
I'm not a developer. I've never written a line of code by hand. But I just shipped a production SaaS with 39 database tables, real-time WebSocket connections, Stripe billing, and a multi-portal architecture. All built with Claude Code. Here's the honest version of what that actually looks like — because the "vibe coding" narrative online skips the hard parts. The backstory: I was running Facebook ads for a wellness franchise with 129 locations. Kept optimising everything — creatives, dynamic landers, personalised guides based on lead form input. Engagement numbers looked great. Bottom line barely moved. Then I pulled the response time data. The locations were taking hours to call leads back. That was the actual bottleneck — not the ads, not the landing page. Speed to lead. So I decided to build a system that fixes this. A single JavaScript snippet that adds dynamic widgets to any existing site, tracks lead behaviour in real-time, assigns intent scores (COLD/WARM/HOT), and sends instant push notifications to the nearest sales rep with tap-to-call when a lead goes hot. The stack (chosen specifically for AI-assisted building): Next.js 16 (App Router) — file-based routing means less wiring to explain to the AI Convex — real-time database with WebSocket subscriptions out of the box. This was the critical choice. For a speed-to-lead product, real-time updates aren't optional Clerk — handles auth so I don't need to debug OAuth flows Railway — push to deploy Each piece handles an entire domain. That matters when you're describing features in plain English and the AI is writing the implementation — you want it focused on your product logic, not infrastructure plumbing. What actually works well: I can describe a feature like "when a lead's intent score crosses the HOT threshold, send a push notification to the assigned sales rep with their name, the lead's name, and a tap-to-call button" and get a working implementation in minutes. Schema changes, API endpoints, UI components. The throughput is genuinely wild compared to hiring. Building new features is fast. Iterating on UI is fast. Adding database tables and the associated CRUD operations — fast. Where it falls apart: Deployment. Railway was down for 4 days at one point because a CI check was silently failing and I had no monitoring. The AI couldn't help — it can't SSH into your Railway container or read runtime logs in context. Auth was rewritten 4 times. Webhook race conditions between Clerk and Convex. JWT issuer mismatches between dev and production. Each iteration took half a day and the AI kept confidently writing code that worked in isolation but broke in production. Stripe had three bugs that each took hours: currency defaulting to USD instead of GBP, missing portal configuration, and webhook event ordering issues. The AI was useless for the event ordering bug because it only happened 30% of the time. The security problem nobody talks about: I ran a security audit and found 4 critical issues: unauthenticated database functions, missing webhook signature verification, no rate limiting on public endpoints, and exposed environment variables. These were introduced because the AI doesn't think about security by default — it writes code that works, not code that's safe. The numbers: 391 git commits. 39 database tables. 60 backend files. Across 2,617 tracked leads at the franchise: 56.7% engagement rate (industry avg is 20-30%), response time went from 2-4 hours to under 5 minutes. The product is live at signalsprint.io. Zero paying customers so far. Building is the easy part. What I'd tell anyone starting this: Pick a stack where each piece handles a complete domain — auth, real-time data, hosting. Don't try to build your own Test EVERYTHING yourself. The AI will write code that looks right and passes the vibe check but breaks in production Run a security audit before you launch. The AI introduces vulnerabilities it doesn't mention Deployment is where AI-assisted development hits a wall. Budget 3x the time you think Version control every single change. 391 commits means I can bisect back to any breaking change I'm documenting the full journey in a 5-day Reddit series if anyone's interested. Happy to answer questions about specific parts of the stack or workflow. submitted by /u/powleads [link] [comments]
View originalRepository Audit Available
Deep analysis of get-convex/convex-backend — architecture, costs, security, dependencies & more
Yes, Convex offers a free tier. Pricing found: $0/month, $25, $2,500, $2.20, $2
Key features include: TypeScript-based backend development, Integrated developer portal, Real-time data synchronization, Built-in authentication mechanisms, Seamless API generation, Type safety across backend and frontend, Version control for database schemas, Usage analytics and monitoring tools.
Convex is commonly used for: Building scalable web applications, Creating real-time collaborative tools, Developing APIs for mobile applications, Implementing user authentication systems, Managing complex database schemas, Integrating with third-party services.
Convex integrates with: Firebase for real-time data, Stripe for payment processing, Auth0 for user authentication, Twilio for SMS notifications, GraphQL for flexible data querying, AWS for cloud hosting, Slack for team notifications, Zapier for workflow automation, PostgreSQL for relational database management, Redis for caching solutions.
Arthur Mensch
CEO at Mistral AI
1 mention

How to deslop your code
Apr 7, 2026
Convex has a public GitHub repository with 11,047 stars.
Based on 14 social mentions analyzed, 21% of sentiment is positive, 79% neutral, and 0% negative.




