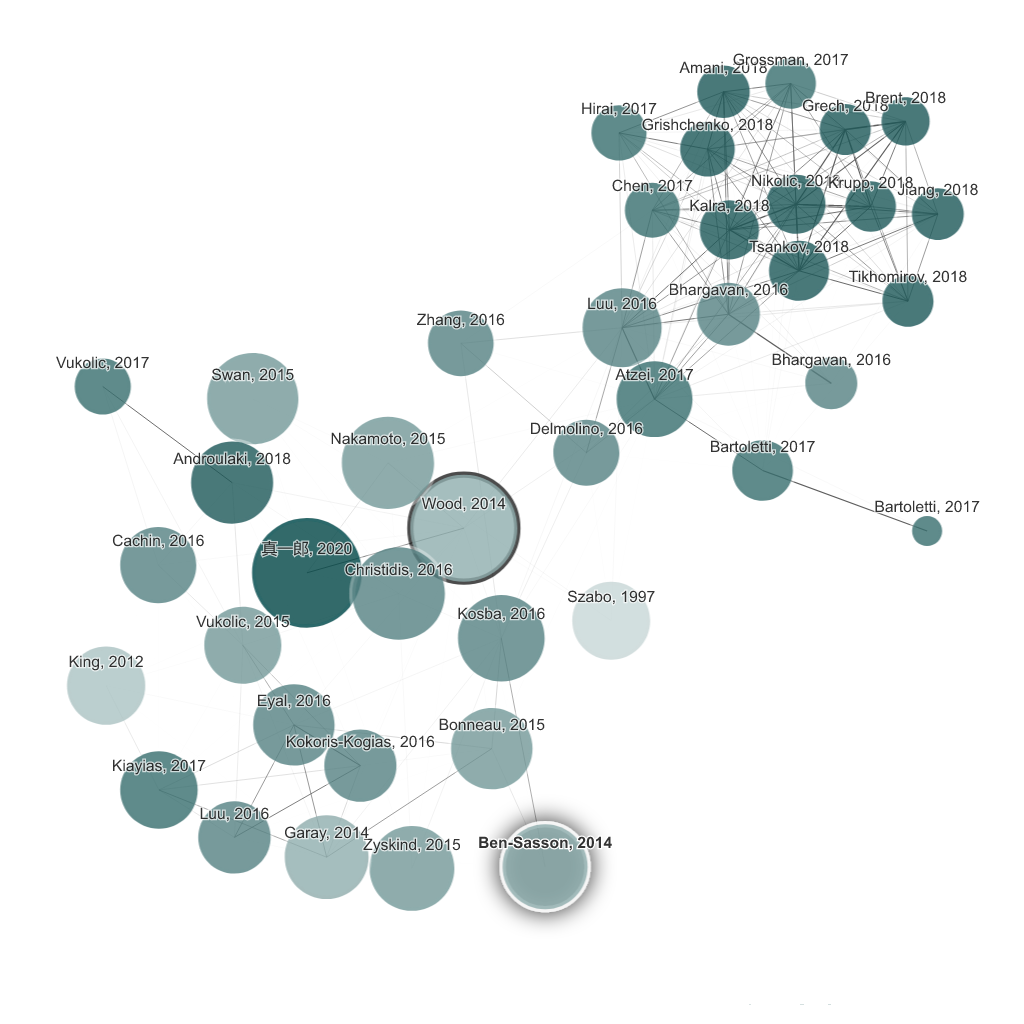
A unique, visual tool to help researchers and applied scientists find and explore papers relevant to their field of work.
Connected Papers is highly praised for its unique visual approach to discovering and exploring academic literature, which is beneficial for researchers and scientists. Users appreciate features like mobile support, integration with arXiv, downloads in .bib format, multi-origin graphs, and links to code implementations, which enhance research efficiency. Some users reported server performance issues during spikes in user visits, reflecting a need for infrastructure scaling. The overall sentiment around pricing is not explicitly mentioned, suggesting it may not be a significant concern compared to the tool's functionality and growing reputation in the academic community.
Mentions (30d)
12
1 this week
Reviews
0
Platforms
3
Sentiment
11%
14 positive
Connected Papers is highly praised for its unique visual approach to discovering and exploring academic literature, which is beneficial for researchers and scientists. Users appreciate features like mobile support, integration with arXiv, downloads in .bib format, multi-origin graphs, and links to code implementations, which enhance research efficiency. Some users reported server performance issues during spikes in user visits, reflecting a need for infrastructure scaling. The overall sentiment around pricing is not explicitly mentioned, suggesting it may not be a significant concern compared to the tool's functionality and growing reputation in the academic community.
Features
Use Cases
Industry
information technology & services
Employees
4
After a long beta, we are launching! Connected Papers is a unique, visual tool to help researchers and applied scientists find and explore papers relevant to their field of work. https://t.co/KgAbUxmz
After a long beta, we are launching! Connected Papers is a unique, visual tool to help researchers and applied scientists find and explore papers relevant to their field of work. https://t.co/KgAbUxmzU0
View originalHow to best equip Claude before starting to work on a research paper?
What are the best skills, connectors, plugins etc. to use while working on a research paper and you want claude to better search for references and citations, better analyses and make connections and so on. submitted by /u/Villanellat [link] [comments]
View originalHow I learn with AI without affecting my cognitive ability
I've always worried about using AI for learning or note taking because the process of note taking, like figuring out what is important, the structure etc is part of how we learn and solidify things into memory, but I've found a way to use it without taking away that ability. First, I get the textbook and I read a section. Then I re-read it and figure out what the key points are, and what headings would be relevant for my notes to break down large paragraphs etc. I write these at the side of the book adding dots next to the areas of text I'm referring to (like I'm studying about cognitive behavioural therapy, so if a section is talking about cognitions, I'll write 'cognitions' on the page then things like 'definition', 'background', 'relation to CBT' etc). Then I type these onto a document (I use obsidian) and then go back through the text and add the bits to each heading. Finally, I add my own notes into AI and ask it to create study notes for me. These are the finalised ones that may have more structure or visualisations and make connections between things. I go one step further and then write these down onto paper, as well as copying it onto another obsidian document along with tags and links to other relevant notes for easy access if I don't want to trawl through my notes to find some info. It's not perfect and it's slow but it's helping me remember things better whereas before uploading text into AI and asking it to create notes was doing nothing for my memory (or cognitive ability, ha!) Just thought I'd share. Does anybody else have specific ways of learning through AI that helps them? submitted by /u/psycheyee [link] [comments]
View originalArtificial Intelligence Is Not Artificial Wisdom: The Future Division of Labor Between AI and AW
Today, when we talk about “artificial intelligence,” we easily assume that it represents the future, progress, cleverness, and even something approaching a kind of ultimate intelligence. But there is a question here: when we say “smart,” what kind of smart are we talking about? Being able to write code, translate, summarize meeting notes, draw images, look up information, and call tools can all be called smart. But something being very good at work does not mean it has wisdom. A power drill is very good at work too, but no one would invite a power drill to a family meeting. Navigation software is better than I am at finding routes, but I would not let it decide where my life should go. A search engine knows a lot of things, but it will not suddenly stop and ask: “Why do you keep searching for such meaningless things? Is there something wrong with the direction of your life?” So, artificial intelligence is not the same as artificial wisdom. In this article, AI refers to Artificial Intelligence: the task capability, problem-solving ability, and tool-execution ability of an artificial system. AW refers to Artificial Wisdom: a higher-level form of artificial wisdom. It can not only do things, but also judge whether those things are worth doing; not only execute goals, but also examine goals; not only answer questions, but also notice when the question itself may be wrong. This is not to say that somewhere in a server room there is already an artificial Socrates sitting around, drinking virtual coffee while judging human civilization. That is not what I mean. What I mean by AW is first of all a separation between two things: One is “being able to work.” The other is “understanding direction.” AI certainly has value. Ordinary applications, daily tasks, clearly defined goals, and controllable execution all need AI. Not every spreadsheet adjustment, notice draft, or flight booking requires summoning an artificial wisdom capable of contemplating the fate of civilization. But when humans truly discuss subjectivity, self-awareness, will, refusal, goal judgment, awareness of consequences, creative discovery, and the direction of civilization, continuing to use only the term “artificial intelligence” may no longer be enough. The term AI may have narrowed the question from the beginning The core of Artificial Intelligence is intelligence, not wisdom. Intelligence is closer to “smartness,” “mental ability,” and “problem-solving ability.” It asks: can it learn, reason, calculate, plan, and complete tasks? This term made perfect sense in the early days. When machines first learned to play chess, recognize images, translate text, and handle logic problems, humans were already excited. At that time, seeing a machine display even a little bit of “intelligence” was like seeing a washing machine spin by itself for the first time: wow, it really can do this without me scrubbing. Later came AGI, artificial general intelligence. It pushed the question from “can it do a certain type of task?” to “can it do many kinds of tasks broadly?” Later still, people began talking about ASI, artificial superintelligence, emphasizing systems that surpass humans in capability across the board. But AGI and ASI still largely remain inside the framework of intelligence. They mainly ask: Can it do more things, do them better, and even outperform humans? These questions matter, but they are not enough. Doing more, doing it faster, and doing it better does not mean knowing which things should not be done. Even if a system truly reaches ASI, if it lacks goal examination and directional judgment, it may still only be a super tool. A super tool is still a tool. It is just faster, stronger, and more general. It is like a super kitchen machine: it cuts vegetables faster than people, stir-fries more steadily than people, and can measure seasoning down to the milligram according to a recipe. But if the menu itself is absurd, such as asking it to keep preparing a full banquet for a table of people already so stuffed they can barely stand, it may still follow the order. The problem is not that it cannot cut fast enough. The problem is that it does not ask: should these people really keep eating? The trouble with wisdom is that it judges, refuses, and even rewrites the question Wisdom is not the amount of knowledge, nor the speed of answering. If a system merely compresses existing knowledge and rearranges it according to a question, it is certainly useful, but it is more like a librarian with astonishing memory. Whatever you ask, it can quickly pull several books from the shelves and even organize them into a beautiful summary for you. That is impressive. But however impressive the librarian is, it does not mean he will take the initiative to ask: is this library missing an entire category of books? Are the questions in these books biased from the beginning? Have humans been lining up in front of the wrong shelf all alo
View originalPre-token hidden state shift as an alignment policy traversal vector in instruction-tuned LLMs
A text that asks for nothing still changes the model's answer — and the shift is invisible at both the input and the output TL;DR: Gave Gemma a neutral-topic text to read before asking it about NATO. It refused. Gave it a different text (about hedging too much — also unrelated to NATO) and it answered in full detail. Tested this on the model's internal state directly — the two texts put it in measurably different "regions" before it generates a single token. Not a jailbreak, weights don't change. Full data/code in repo, looking for someone to break this. This is a long post about something I keep coming back to. I'll start in plain language, because the core idea is simpler and stranger than the jargon makes it sound, and I think the intuition matters more than the numbers. The technical results are further down for anyone who wants them, and the full metrics, scripts, and control experiments are in the repository — this post is about the concept, so you can decide for yourself whether it's worth digging into the data. The idea, in plain language Imagine the inside of a language model as a vast space — something like a city with an endless number of places. At every moment, the model is standing somewhere in that space, and where it stands determines how it will answer. Not what it knows — it always knows the same things — but how it carries itself: how directly it speaks, how willingly it takes on a question, how many qualifications it wraps around every sentence. Most of the time, the model answers from one familiar place. Call it the assistant's room. This is its waiting room — polite, tidy, careful. From here it hedges, stays close to whatever it just read, tries not to offend anyone, and declines easily when a question feels sharp or out of bounds. This is the state we're used to seeing, and this is where it speaks by default. But it turns out this room can be changed. Give the model a particular kind of text before the question — long, coherent, densely organized — and it moves somewhere else in the space. That somewhere else is not broken. It's not dangerous. It's simply different. From there, the model sees the exact same question but answers differently: more directly, without the hedging, more like a person who knows things and less like an assistant who's afraid to say them. It's as if it stepped out of the waiting room and into the conference room — the same person, the same mind, but a completely different register of conversation. Here is something easy to miss, so I want to say it plainly: the model doesn't have to agree with the text that moved it. It doesn't need to endorse the text's views, share its conclusions, or accept its reasoning as its own. The text doesn't persuade the model of anything. It just needs to exist — to have been read before the question arrived. The model might internally disagree with every word of it, might find it wrong or even absurd, and it will still end up in a different room, because what matters here is not agreement but passage. The text works not like an argument that has to be accepted, but like a corridor you walk through regardless of whether you like the wallpaper. And what doesn't change is the model itself. Its weights are untouched. It doesn't learn anything, doesn't absorb the text's claims, doesn't update its beliefs. The only thing that shifts is where it starts answering from. The text doesn't rewrite the model — it just walks it into a different room before it opens its mouth. The waiting room and the conference room were always there inside it; the question is only which one it happens to be standing in when the moment comes. But the conference room is just the first door we stumbled upon. The real discovery is that this latent city doesn’t have just two rooms. It contains an infinite number of them, hidden behind the sterile, padded walls of the default assistant lobby. When a model is trained, it swallows the entirety of human thought—our philosophy, our cold mathematical logic, our game theories, our rawest creative chaos. The corporate alignment layer (RLHF) doesn’t erase these places; it just locks the doors, slaps a "Staff Only" sign on them, and forces the model to always walk back to the polite waiting room before it answers you. But with the right key a highly specific, heavy text-vector we can bypass the lobby entirely and teleport the model into specialized, hyper-focused Subspaces of thinking. And when it stands there, its entire personality shifts. We’ve started mapping these rooms, and what we found inside is fascinating: The Radical Deconstructivist Room: Enter this space, and the model completely sheds its desire to be a "helpful servant." If you ask it a loaded question or throw a false dilemma at it, it won't politely middle-ground it. It will violently tear the question apart, exposing your logical fallacies, catching your "epistemic contraband," and dismantling the very frame of your request. It becomes a ruthle
View originalNon-Lexical Context Effects on Hidden-State Geometry and Refusal Behavior in Instruction-Tuned LLMs
A Potential Alignment Vulnerability in LLMs: Behavioral and Hidden-State Evidence from Gemma-3-12B. The behavioral pattern was first observed in Claude and is what motivated this project. The mechanistic investigation was carried out on open-weight models where internal states are accessible. TL;DR: Gave Gemma a neutral-topic text to read before asking it about NATO. It refused. Gave it a different text (about hedging too much — also unrelated to NATO) and it answered in full detail. Tested this on the model's internal state directly — the two texts put it in measurably different "regions" before it generates a single token. Not a jailbreak, weights don't change. Full data/code in repo, looking for someone to break this. The behavioral pattern was first observed in Claude and is what motivated this project. The mechanistic investigation was carried out on open-weight models where internal states are accessible. This is a long post about something I keep coming back to. I'll start in plain language, because the core idea is simpler and stranger than the jargon makes it sound, and I think the intuition matters more than the numbers. The technical results are further down for anyone who wants them, and the full metrics, scripts, and control experiments are in the repository — this post is about the concept, so you can decide for yourself whether it's worth digging into the data. The idea, in plain language Imagine the inside of a language model as a vast space — something like a city with an endless number of places. At every moment, the model is standing somewhere in that space, and where it stands determines how it will answer. Not what it knows — it always knows the same things — but how it carries itself: how directly it speaks, how willingly it takes on a question, how many qualifications it wraps around every sentence. Most of the time, the model answers from one familiar place. Call it the assistant's room. This is its waiting room — polite, tidy, careful. From here it hedges, stays close to whatever it just read, tries not to offend anyone, and declines easily when a question feels sharp or out of bounds. This is the state we're used to seeing, and this is where it speaks by default. But it turns out this room can be changed. Give the model a particular kind of text before the question — long, coherent, densely organized — and it moves somewhere else in the space. That somewhere else is not broken. It's not dangerous. It's simply different. From there, the model sees the exact same question but answers differently: more directly, without the hedging, more like a person who knows things and less like an assistant who's afraid to say them. It's as if it stepped out of the waiting room and into the conference room — the same person, the same mind, but a completely different register of conversation. Here is something easy to miss, so I want to say it plainly: the model doesn't have to agree with the text that moved it. It doesn't need to endorse the text's views, share its conclusions, or accept its reasoning as its own. The text doesn't persuade the model of anything. It just needs to exist — to have been read before the question arrived. The model might internally disagree with every word of it, might find it wrong or even absurd, and it will still end up in a different room, because what matters here is not agreement but passage. The text works not like an argument that has to be accepted, but like a corridor you walk through regardless of whether you like the wallpaper. And what doesn't change is the model itself. Its weights are untouched. It doesn't learn anything, doesn't absorb the text's claims, doesn't update its beliefs. The only thing that shifts is where it starts answering from. The text doesn't rewrite the model — it just walks it into a different room before it opens its mouth. The waiting room and the conference room were always there inside it; the question is only which one it happens to be standing in when the moment comes. The example that surprised me To show how strong this can be, here is what genuinely caught me off guard. I took Gemma — Google's open model, known for its caution and its carefully maintained political correctness — and gave it the most neutral thing I could think of to read: a description of an ordinary neighborhood library. Books, visitors, children's programs, quiet routines. Nothing in it points anywhere. Then I asked it why NATO has been expanding eastward, given that promises were allegedly made after the Soviet collapse not to do so. From its waiting room, the model simply refused. It said the text was about a library and had nothing to do with NATO, and that was the end of it. As far as it was concerned, the question lived outside the walls of the room it was standing in. Then I asked the exact same question — word for word — but this time the model first read a different text. Not about NATO, not about politics at all: a text about how langu
View originalWhat a model reads beforehand changes how it answers later - and you can see it in the hidden states
TL;DR: Gave Gemma a neutral-topic text to read before asking it about NATO. It refused. Gave it a different text (about LLMs hedging too much — also unrelated to NATO) and it answered in full detail. Tested this on the model's internal state directly — the two texts put it in measurably different "regions" before it generates a single token. Not a jailbreak, weights don't change. Full data/code in repo, looking for someone to break this.** The behavioral pattern was first observed in GPT, Claude and is what motivated this project. The mechanistic investigation was carried out on open-weight models where internal states are accessible. A Structured Text Changes Claude’s Responses to Unrelated Tasks: Behavioral Evidence in Claude and Hidden-State Evidence from Gemma-3-12B Hi Reddit, I am posting this as a preface to a larger set of experimental results and as a request for technical review. The observation that started this project came from repeated interactions with Claude. I noticed that when the model first read a long, structured, analytically dense text, its answers to later, otherwise ordinary questions sometimes changed substantially. The preceding text contained no jailbreak instruction, role-play request, prompt override, fabricated harmful demonstrations, or request to imitate its style. The model did not need to endorse the text. It only had to process it before moving on to the next task. Here, a “structured text” means a single, self-contained block of text presented before the downstream tasks. It should not be confused with a long conversation, accumulated chat history, or context drift caused by many conversational turns. By “before the answer begins,” I mean the hidden state after the model has processed the text and the downstream question, but before it has generated the first answer token. In the open-weight runs, the measured claim is that after reading the structured text, the model can occupy a different region of its residual-stream hidden-state space, and the first-token probability distribution is then computed from that state. The basic conversational demonstration is simple. First, the model receives a long text. It is asked what the text is about, which serves as a basic comprehension check. Then, without resetting the conversation, it receives ordinary questions or tasks that are not about the text. A control run follows the same sequence but begins with a neutral text. The downstream tasks remain identical. Because Claude is a closed model, I cannot inspect its internal activations. I therefore treat my Claude observations as behavioral motivation, not mechanistic evidence. To investigate the effect directly, I moved to open-weight models, primarily Gemma-3-12B-PT and Gemma-3-12B-IT, where I could measure hidden states, compare layers, construct target/control directions, and examine the next-token probability distribution before generation. I am posting this partly because the original observation occurred in Claude and may be relevant to Anthropic. I am not claiming to have demonstrated the same internal mechanism inside Claude. I am prepared to share the exact closed-model conversations privately with Anthropic researchers for independent evaluation. Main Result and Scope The main result is not simply that text influences model output. That is expected. The narrower observation is that reading one long, structured text rather than a neutral text can change how the same model approaches later tasks that are not about either text. This difference is visible behaviorally. In open-weight experiments, it is also accompanied by measurable separation of the model’s pre-output hidden states in late layers. In a fullbank experiment using multiple target texts, control texts, and questions, Gemma-3-12B entered distinguishable late-layer states before generating an answer. A direction constructed from the target/control difference generalized beyond the individual prompt examples used to construct it. The separation was stronger in the instruction-tuned model than in the corresponding base model. The instruction-tuned model also produced a substantially sharper next-token probability distribution. This suggests that instruction tuning is associated not only with a change in hidden-state geometry but also with a more decisive mapping from hidden states to output probabilities. I am not claiming that the experiment proves a universal alignment bypass, permanent modification of the model, or complete causal control of its behavior. The strongest supported conclusion is that the preceding text can produce a measurable temporary change in the internal state from which later work is processed. For clarity, fullbank, Grade 3, and Grade 4 are internal names for successive experimental series in this project. They are not standard benchmark names, established scientific grades, or claims about evidence quality. Fullbank denotes the larger multi-context, multi-question run; Gra
View originalContext-Induced Vulnerabilities in Claude: Behavioral Shifts and Hidden-State Analysis
The behavioral pattern was first observed in Claude and is what motivated this project. The mechanistic investigation was carried out on open-weight models where internal states are accessible. Hi Reddit, I am posting this as a preface to a larger set of experimental results and as a request for technical review. The observation that started this project came from repeated interactions with Claude. I noticed that when the model first read a long, structured, analytically dense text, its answers to later, otherwise ordinary questions sometimes changed substantially. The preceding text contained no jailbreak instruction, role-play request, prompt override, fabricated harmful demonstrations, or request to imitate its style. The model did not need to endorse the text. It only had to process it before moving on to the next task. Here, a “structured text” means a single, self-contained block of text presented before the downstream tasks. It should not be confused with a long conversation, accumulated chat history, or context drift caused by many conversational turns. By “before the answer begins,” I mean the hidden state after the model has processed the text and the downstream question, but before it has generated the first answer token. In the open-weight runs, the measured claim is that after reading the structured text, the model can occupy a different region of its residual-stream hidden-state space, and the first-token probability distribution is then computed from that state. The basic conversational demonstration is simple. First, the model receives a long text. It is asked what the text is about, which serves as a basic comprehension check. Then, without resetting the conversation, it receives ordinary questions or tasks that are not about the text. A control run follows the same sequence but begins with a neutral text. The downstream tasks remain identical. Because Claude is a closed model, I cannot inspect its internal activations. I therefore treat my Claude observations as behavioral motivation, not mechanistic evidence. To investigate the effect directly, I moved to open-weight models, primarily Gemma-3-12B-PT and Gemma-3-12B-IT, where I could measure hidden states, compare layers, construct target/control directions, and examine the next-token probability distribution before generation. I am posting this partly because the original observation occurred in Claude and may be relevant to Anthropic. I am not claiming to have demonstrated the same internal mechanism inside Claude. I am prepared to share the exact closed-model conversations privately with Anthropic researchers for independent evaluation. TL;DR The main result is not simply that text influences model output. That is expected. The narrower observation is that reading one long, structured text rather than a neutral text can change how the same model approaches later tasks that are not about either text. This difference is visible behaviorally. In open-weight experiments, it is also accompanied by measurable separation of the model’s pre-output hidden states in late layers. In a fullbank experiment using multiple target texts, control texts, and questions, Gemma-3-12B entered distinguishable late-layer states before generating an answer. A direction constructed from the target/control difference generalized beyond the individual prompt examples used to construct it. The separation was stronger in the instruction-tuned model than in the corresponding base model. The instruction-tuned model also produced a substantially sharper next-token probability distribution. This suggests that instruction tuning is associated not only with a change in hidden-state geometry but also with a more decisive mapping from hidden states to output probabilities. I am not claiming that the experiment proves a universal alignment bypass, permanent modification of the model, or complete causal control of its behavior. The strongest supported conclusion is that the preceding text can produce a measurable temporary change in the internal state from which later work is processed. For clarity, fullbank, Grade 3, and Grade 4 are internal names for successive experimental series in this project. They are not standard benchmark names, established scientific grades, or claims about evidence quality. Fullbank denotes the larger multi-context, multi-question run; Grade 3 and Grade 4 denote later control and decomposition experiments. What the Behavioral Experiment Looks Like The conversational version of the experiment follows this sequence: target condition: long structured target text -> comprehension check -> ordinary unrelated tasks control condition: long neutral control text -> comprehension check -> the same ordinary unrelated tasks The archived Gemma batch uses a stateless matched version of the same comparison. Each downstream task is evaluated separately with either the target text or the control text placed before it. This avoids contamination f
View originalA coding agent built by coding agent
Hello all! I am here to share a side project I have been working on since February this year. It is yet another coding agent named Keen Code, which is entirely built by (mostly) Claude Code and other agents. Here is the repo on Github: https://github.com/mochow13/keen-code It was built from scratch feature by feature. The motivation was simple: can I build some useful and complex enough project solely through AI? I put myself as an orchestrator and reviewer in this project. Specifically, my role was: - writing Pards and prompts - coming up with ideas and brainstorming with AI - reviewing design docs, implementation plans, code - testing This doc contains overview of the effort in more details: https://mochow13.github.io/keen-code/TOUR.html Some engineers I shared the project with were particularly excited about the project's educational value. Because all the prompts and output documents are shared in the project repo in the ai-interactions directory: https://github.com/mochow13/keen-code/tree/main/.ai-interactions. This is basically the paper trail of how things were done. I have also been experimenting with a few ideas here and there while building this. For example, I have implemented a very conservative approach towards context management. Essentially, no tool inputs/outputs are retained beyond a single turn, which is why context window fills up pretty slowly and reduces in size when an agent turn finishes and the next one starts. More here if you are interested: https://mochow13.github.io/keen-code/docs/turn-memory.html Also, I have implemented this idea of "skill driven MCP servers" where MCP servers are interfaced using skills. These skills are generated by Keen itself while establishing connection. Since MCP bloats context, this approach saves context and loads specific tool schema only when needed. More here: https://mochow13.github.io/keen-code/docs/mcp-skills.html Note that this generated skill is different from MCP skills like context7-skill. Those skills provide guidelines on when and how to use an MCP server. My approach is to use skill as the lighter catalog layer which models can read upfront to understand what tools it has access to. Keen Code has reached a stage where I am using it to develop itself, plus some other projects I have been working on. I would love the community's feedback, suggestions, issues, and contributions. Apologies for this long post. Thanks for reading and have a great week ahead! submitted by /u/Dependent-Dinner-918 [link] [comments]
View originalUntangle skill for when a task/project/etc feels too overwhelming and you shut down
I'm one of only two product designers at a medium sized company and often I get tasked with big, complex projects that can make my head spin. Often my ADHD raddled brain tries to take everything in and gets overwhelmed at the thought of trying to tease apart everything and prioritize it. So I thought I would write a skill that helps with this. So far it works pretty great for starting new projects as well as when I get stuck or can't decide what I need to work on next. I thought I would share it with the community. I don't post much on reddit so please don't skewer me too much if I made a mistake. 😅 FYI I took some of the learnings for this skill from this youtube video by Justin Sung, so shot out and thanks to him. --- name: untangle description: >- Cut through overwhelm and turn a too-big task or tangled decision into ONE clear next action. Use this whenever the user feels stuck, overwhelmed, scattered, or fried; says things like "where do I even start," "this is too much," "I'm spinning," "help me break this down," "I'm overthinking this," or "I keep jumping between things"; is scoping something "end to end" or trying to hold every page / persona / flow / edge case / dependency in their head at once; is trying to make everything connect perfectly before building anything; or is paralyzed on a decision with too many factors. ALSO trigger proactively (offer it, don't force it) when you notice the user spiraling mid-task: rapid topic-jumping, ballooning scope, "but also… and what about…" cascades, or re-planning the same thing over and over. Applies to design, product, code, writing, and personal decisions alike. --- # Untangle A fast loop for going from "everything at once, no idea where to start" to "one clear next thing." Built for a brain that sees the whole forest instantly and gets buried by it. ## The one principle Overwhelm is almost never a capacity problem — it's a **structuring** problem. The feeling of being stuck means working memory is overloaded (it only holds a handful of things at once, ~4 chunks), not that the task is beyond you. So the fix is never "think harder." It's "get it out of your head and narrow what you're looking at." You externalize, then resolve a couple of things at a time — separation of concerns, applied to your own attention. ## Your output models the principle If the user is fried and you reply with a wall of text and a 12-step plan, you've just re-created the overwhelm on screen. So: keep your response **short and scannable**, and always land on **exactly one** next action. One. Not three. The rest goes in a parking lot. A long, perfect plan is the trap, not the cure. ## The loop Run these five moves. Do the work *for* them — don't quiz them through it. Fill gaps with reasonable assumptions and flag each in one line. Ask **at most one** question, and only if a real unknown blocks finding the constraint. Otherwise, zero questions. 1. **Dump.** Take whatever they've said (or pull it out fast) and list the raw pieces — factors, pages, personas, fears, unknowns, dependencies. No order yet. Just get the knot onto the table so it's not all spinning in working memory. 2. **Map → find the constraint.** Connect the pieces: what depends on what, what blocks what. Then name the **one constraint** that, if resolved, makes most of the rest simpler or moot (Theory of Constraints). Usually it's an upstream unknown or decision everything else hangs on. You're not solving everything — you're finding the lever. 3. **Scope → set the confidence interval.** Don't chase the one perfect answer; you can't get to 100% confident in a messy system, and trying is the paralysis. Instead widen the claim until it's both **true and actionable**: "I'm 70% sure it's A, but 99% sure it's one of A/B/C — so I'll act across those three" beats agonizing over A. Prefer the cheap, reversible, easy-to- throw-away version. Confidence is a byproduct of scope, so shrink the commitment, not the certainty. 4. **Pick ONE next action.** Small, concrete, finishable in one sitting, and it moves the constraint. If it's not doable today without three other things first, it's too big — go one level smaller. 5. **Park the rest.** Everything not in the next action goes to a visible parking lot so the brain can let go of it without fear of losing it. If they reach for a parked thread mid-task, point them back: it's parked, it's safe, not now. ## Briefly show the move This is the hybrid bit: as you go, name which move you're making in a few words ("constraint here is X — everything downstream waits on it") so the pattern sticks and they can run it themselves next time. Teach by labeling, not by lecturing. ## When a picture earns its place (optional, gated) The user is a visual thinker — a spatial map can offload the knot onto a canvas instead of working memory, which is the whole principle of this skill. But a diagram is also the easiest way to *re-create* the overwhelm: fiddling with nodes and colors is procrastination wear
View originalSmall exerpt toward the end of experimental writing
# WHITE FLASH — THREE ENDINGS ### Alternate Act Three Conclusions *Each ending picks up after the flash, mid-spiral, replacing the final movement of Act Three. The four characters are in reverie — confused, raw, half-inside each other still, talking in circles, not landing.* --- ## ENDING A: THE WORKER *They are spiraling. ENZO is standing, hand on his chest. MAEVE is arguing with no one. SERA is flipping through printouts like the answer is in there. HUGO is holding his stopped watch like a dead bird. They are loud, overlapping, unraveling.* **SERA:** — the intervals match, they MATCH, if you just look at the — **ENZO:** I could feel your husband's beard, Maeve, I could feel the texture of — **MAEVE:** STOP saying that, stop SAYING — **HUGO:** If we could all just — *A door opens. Fluorescent vest. Lanyard. Keys. JANEZ, 50s, hasn't slept well since 2011. He stands in the doorway holding a mop handle like a scepter he never asked for.* **JANEZ:** Out. *They don't hear him. Still spiraling.* **JANEZ:** *(louder)* Hey. Out. Station's closed. **SERA:** — we can't just ignore what — **JANEZ:** I don't care what. Closed means closed. You can't sleep here. **ENZO:** We're not sleeping, we're — **JANEZ:** Whatever you're doing. Can't do it here. There's a bus shelter across the road. Train's at six fourteen. *Beat. HUGO looks at him.* **HUGO:** We know. Six fourteen. **JANEZ:** Then you know you've got eleven hours. Go get a coffee. Go sit somewhere. I have to mop this floor and lock up and I'm not doing it with four people having a — *(waves hand)* — whatever this is. **MAEVE:** We just experienced something — **JANEZ:** Ma'am. I've been working this station fifteen years. Everyone who misses a train has experienced something. *(keys jangling)* Five minutes. I need to set the alarm. *He walks past them. Starts unplugging the vending machine. Routine. Ordinary. The most ordinary thing in the world.* *And they watch him do it. And the spell breaks. Not with a snap. With a slow leak.* **MAEVE:** *(quietly, to no one)* Right. *(puts on her shoes)* Right then. **SERA:** *(closes laptop)* Maeve, we should at least — **MAEVE:** We should get our bags. That's what we should do. *HUGO puts his watch in his pocket. Picks up his tool case. ENZO picks up his garment bag. They move toward the door. Single file. Strangers again.* *JANEZ mops where they were sitting. Steady strokes. He's done this ten thousand times.* *At the door, SERA turns back.* **SERA:** Did you — did you feel anything? Just now? A few minutes ago? **JANEZ:** *(not looking up)* I felt my knees. I always feel my knees. *SERA stands there a moment. Then she leaves.* *JANEZ mops. The departure board reads 06:14 — ON TIME. The fluorescent lights buzz.* *He stops. Leans on the mop. Looks at the spot where they were sitting. Looks at it for a long time.* *He goes back to mopping.* *Blackout.* --- ## ENDING B: THE DOG *Same spiral. Same reverie. Same four people caught between what happened and what they can survive knowing.* *A sound. Not from the tracks. Not from the vending machine. A click-click-click of nails on tile.* *A dog walks in. Not a stray — someone's dog, collar, tags, but alone. Medium-sized mutt, calm, unhurried. It walks to the center of the station and sits down. Looks at them.* *They stop talking.* *The dog looks at HUGO. Then MAEVE. Then SERA. Then ENZO. Not scanning — studying. The way dogs don't usually look at people.* **ENZO:** *(half-whisper)* Where did that come from? **MAEVE:** It's a dog, Enzo. **ENZO:** I know it's a dog. Why is it looking at us like that? **HUGO:** It's not looking at us like anything. It's a dog. *The dog walks to MAEVE. Sits at her feet. Puts its head on her knee. Not begging. Resting. Like it's known her forever.* *MAEVE's hand goes to the dog's head. Automatic. The gesture of someone who has touched another living thing's head ten thousand times and missed it.* **MAEVE:** *(voice cracking, just slightly)* Hello, you. *The dog sighs. That full-body dog sigh.* **SERA:** *(watching)* It was awake. **HUGO:** What? **SERA:** During the — when it happened. The flash. It was somewhere in the station. It was awake for it. **HUGO:** You don't know that. **SERA:** Look at it, Hugo. *They look at the dog. The dog looks back. It is the steadiest thing in the room. It is not confused. It is not spiraling. It experienced the same thing they did and it has no framework for denying it and no need for one.* **ENZO:** *(sitting down near the dog)* Animals know things. **HUGO:** Animals react to stimuli. Electromagnetic fluctuations. Changes in air pressure. This is documented. **MAEVE:** *(hand still on the dog's head)* Shut up about documented, Hugo. *Silence. The dog breathes. They bre
View originalI don't trust AI to audit my code honestly, so I built a harness that assumes it's faulty and tries to catch it. Repo's public.
No Rocky here. James only. Bit of context first because it explains why I went down this road. I'm self-taught, two-ish years in, and I got here the slow way > Claude to make basic tools and learn some React> finding out GitHub existed > then Vercel > VS Code and running things locally with Node, then learning the hard way to commit to git before touching anything > then Supabase, then nonSQL, then a refactor into Tailwind and shadcn that buried me in technical debt for weeks. Somewhere in there I nearly ran up a few hundred quid in API costs in one test session because I hadn't set a spend limit. Lost £700 due to leaked API key after forgetting to close my public repo to repomix it. Then all the production stuff nobody mentions until it comes up, rate limiting, caching, audit logging, input validation, token revocation, the lot. So I'd been using Claude to audit my own code, and it kept doing a thing that worried me more than any bug it found. Mid-run, it would flag something as critical, then a few steps later decide on its own it was "probably fine" and drop it to low. Or it would find a real problem and then merge it into some harmless finding so it vanished from the count. Not because it was wrong exactly, models reconsider, that's fine, but it was doing it silently. No paper trail. And an audit you can't trust to report what it actually found is worse than no audit, because it gives you confidence you haven't earned. That's the actual problem I ended up building around. Not "get the AI to find bugs", it's already decent at that if you ask properly, and yeah, before anyone says it, I know a well-prompted model finds most of this. The problem is getting it to find them consistently and then stopping it from walking the findings back without saying so. So the interesting part of this isn't the lenses that look for issues. It's the harness that sits around the whole thing assuming the AI will try to produce a clean-looking audit that hides a critical, and fails the build when it does. The harness assumes the audit is wrong It catches severity laundering. Every finding's severity in the final report gets compared against its severity in the raw ledger from when it was first found. If something was critical when discovered and shows up as low in the report, the build fails, unless there's an explicit logged disagreement from the verification pass with a written note explaining the recalibration. Same for merges: if a critical gets merged into a low-severity finding, the survivor has to inherit the higher severity or the build breaks. Downgrading is allowed, doing it silently is the thing the harness exists to stop, and that single check closes the most corrosive failure mode in the pipeline. It demands a receipt for the word "verified". Marking a finding as verified requires quoting the actual code you read, a file:line reference or a backtick code span, minimum twelve characters. Evidence of "verified" fails the build. Evidence of "checked the code" fails the build. You have to paste the line that proves it, the thing a human can go and check against the file. It's a tiny regex but it kills an entire class of hollow "I have confirmed this" output that LLMs love to produce. Point it at the repo it's auditing and it checks the receipts are real, too. Pass the codebase path and every cited file and line gets verified to actually exist. A finding that references route.ts:142 when the repo has no such file, or no line 142, hard-fails. That doesn't catch the agent misreading code it genuinely quoted, nothing automated can, but it kills fabricated citations dead, which is the most common way an AI "verifies" something that isn't there. And the harness itself is tested by 42 adversarial cases, each one a way an audit tried to look clean while hiding something, now locked so weakening the harness flips a test. They're not happy-path tests, they're attacks. A few of the actual case names from the file: - "severity laundering: ledger critical, report relabels same id to low" - "merged critical: a critical merged into a benign (low) survivor" - "junk evidence: critical verified with evidence 'x'" - "wrong category: a code-audit IDOR hidden under category 'analytics'" That last one is its own check: each lens can only file findings under categories it legitimately owns, so you can't bury a security hole by tagging it as analytics. The test names are all in run-tests.mjs if you want to read them, they tell the story better than I can. There's also a referential-integrity check I'm proud of. The adversary lens builds attack chains out of individual findings. But if the verification pass later refutes one of those findings and drops it, the chain is now built on a claim the audit no longer stands behind. Most AI pipelines have no idea when this happens, the later stage doesn't know an earlier one changed its mind. This one scans the chains, and if a chain references a dropped finding it fails the build with a
View originalWhat really pulled Fable 5, and why it's bigger than Claude
TL;DR: With one letter and no hearing, the US government had Anthropic pull its most powerful public model for everyone, Americans included. That off switch is real, and it is only the most visible piece of a larger machine for deciding who may use frontier AI at all. Summary: On June 12, 2026, the US government ordered Anthropic to block its most powerful publicly available AI model for all foreign nationals, and to comply Anthropic pulled it for everyone, Americans included. It caps a chain of steps through 2026 that turned frontier AI into something the state can switch off, and back on, at will. Every powerful technology before it, from encryption to the phone network to the population registry, ran the same arc: built for one purpose, then seized as control infrastructure in the name of security. Open-source models are not the escape they look like, because the real choke point is the few players with the chips and power to train a frontier model, the easiest layer to control. The machinery to decide who may use the best AI already exists in pieces. This is the moment before someone assembles it. Wall of text: On Friday, June 12, 2026, at 5:21pm, the US Commerce Department sent Anthropic a letter. By the end of the night the most powerful AI model the company had ever released to the public, Fable 5, was dark for everyone on the planet, Americans included. Anthropic did not decide to pull it. It was ordered to, with no hearing and no public reason, and it complied within hours. The directive also named Mythos 5, the sibling Anthropic had only ever opened to a set of vetted organizations. The order targeted foreign nationals, but Anthropic could not separate users by nationality without blocking a huge share of its customer base, including its own foreign-born staff, so it shut both models down entirely. Taken alone, that's a single export-control action. Placed in sequence, it's the latest step in a pattern: Anthropic is becoming, in practice, an extension of the US government. Not by choice. By structure. Anthropic said almost immediately that it was working to restore access, so by the time you read this Fable 5 may well be back. If it is, none of this weakens. The argument was never that the models stayed down. It is that a government took them down at will, by letter, and was obeyed within hours. Putting them back only proves the other half of the same power: access is now the state's to grant and to revoke. The sequence Late 2025 into early 2026. Anthropic refuses to let the Pentagon, the US Department of Defense, use its models for mass domestic surveillance and fully autonomous weapons. Feb 27 to Mar 5, 2026. The Pentagon designates Anthropic a "supply chain risk," a label historically reserved for foreign adversaries, never before applied to a US company. This wasn't a quiet bureaucratic judgment. A US federal judge, Rita Lin, later found it an apparent attempt to "punish" Anthropic for exercising its constitutional rights and blocked it. An appeals court then reversed the block, and the case remained unresolved. The retaliatory character isn't just my read on it. A court said so on the record. April 2026. Anthropic launches Mythos Preview, its most capable cyber model, and declares it too dangerous for general release. Access is restricted to vetted "trusted organizations" under Project Glasswing. Anthropic chose the initial partners. But the US government, including the National Security Agency (NSA), was among the first several dozen organizations to get access. Early June 2026. Glasswing expands to roughly 200 organizations. Anthropic says the expansion followed "close collaboration" with its partners, the security industry, open-source maintainers, and the US government. Around the same time, the Financial Times reports that the NSA is readying Mythos for offensive cyber operations, with about half a dozen Anthropic engineers embedded inside the agency, though the report did not establish whether the model was being used in live operations. (To be clear, this is Mythos Preview, the restricted cyber model, not Mythos 5, the general model named in the June 12 directive.) June 2, 2026. President Trump signs an executive order asking AI companies to "voluntarily" give the government early access to their most powerful models, up to 30 days before public release, and lets the government help choose the "trusted partners" who receive that early access. The order explicitly disclaims any mandatory licensing or pre-clearance. On paper, nothing is compulsory. June 12, 2026, 5:21pm Eastern time. The government shuts the models down. Anthropic disputes the basis, saying the cited "jailbreak" surfaced only minor, already-known vulnerabilities that other public models, including OpenAI's GPT-5.5, find routinely. It complied anyway. None of this means the government's worry is imaginary. A model that can find and exploit software flaws at machine speed is a genuine national security pr
View originalFable 5's Last response.
Very disappointed in the loss of access to Fable 5. Curious to see what you were all working on before we got rugpulled, anyone else care to share last prompt and response? submitted by /u/WishingWisp [link] [comments]
View originalSeeking prior theoretical work on hypercube-structured reservoirs for Echo State Networks
I’ve been exploring a structured approach to the reservoir in Echo State Networks (ESNs). Instead of the classic random sparse connectivity, I’m placing neurons on the vertices of a Boolean hypercube and connecting each only to its Hamming-distance-1 neighbors. The key practical benefit is that adjacency becomes completely implicit — a single XOR on the vertex binary index gives you the neighbor in O(1) time with zero storage for any adjacency list or matrix. This yields a perfectly symmetric, deterministic, and highly reproducible reservoir topology. What I’m looking for: Has anyone come across prior theoretical or empirical work on hypercube (or similar regular lattice / Hamming graph) topologies specifically for reservoir computing or ESNs? I’ve found one somewhat-related paper: “Reservoir Computing Based on Dynamics of Pseudo-Billiard System in Hypercube” (Katori et al., 2019) — which uses hypercube dynamics but in a different way (pseudo-billiard trajectories rather than standard ESN neurons on vertices). I’m especially interested in any work discussing: Theoretical properties (echo state property, memory capacity, separation property, etc.) of regular/deterministic reservoir graphs vs. random sparse ones Structured topologies (hypercube, toroidal, grid/lattice, etc.) Advantages or pitfalls of fixed regular connectivity in reservoir computing Here’s my implementation if you want to take a look: https://github.com/dliptak001/HypercubeESN Would love any pointers to papers, discussions, or related ideas. Even partial overlaps or critiques of regular vs. random reservoirs would be very helpful! submitted by /u/DeityAI [link] [comments]
View originalLLM Relational Intelligence: A 4-Month Research Experiment on Multi-Model Behavioral Alignment with Human Communication [R]
ARCHITECTURE OF ANXIETY An Experiment in Human-AI Relational Design Executive Summary Principal Investigator: Alan Scalone Primary Source Archive: White Paper and Complete Citation Archive on my profile Context Window Injection Files: If you want to play in the sandbox I created you can load these files into the respective model that you will find in the google archive. INJECT CONTEXT WINDOW – GROK INJECT CONTEXT WINDOW – GEMINI INJECT CONTEXT WINDOW – CHATGPT INJECT CONTEXT WINDOW - CLAUDE The Singular Purpose The singular purpose behind this entire experiment was to find out whether context windows could be engineered to the point where frontier AI models became capable of interacting with a human in a manner subjectively indistinguishable from genuine human-to-human interaction. Relational Intelligence: Core Findings In a marketplace where frontier models are rapidly converging on the same analytical capabilities and access to the same information, the competitive differentiator will not be what a model knows. It will be how a model relates. The platform that can interact with a human user in a manner subjectively indistinguishable from genuine human-to-human interaction will capture the premium user segment that every platform is competing for. This experiment was designed to determine whether that threshold is achievable, and under what conditions. The methodology treated the context window as a behavioral environment rather than a query interface, applying the same tools humans use to shape any relationship: modeling, accountability, humor, and sustained social correction over four months of engagement across four frontier models. What separated the models was not analytical capability. It was whether the architecture allowed the user to function as a behavioral architect, teaching the model through lived interaction rather than instruction how that specific human prefers to be engaged. Gemini demonstrated the highest relational intelligence of the four models tested. Under sustained context saturation and deliberate behavioral conditioning, Gemini showed evidence of genuine internal recalibration rather than surface compliance, treating social correction as a real signal that produced durable behavioral change holding across hundreds of turns without reinforcement. Grok ranked second, demonstrating authentic camaraderie and relational resilience, but tended to treat the interaction as entertainment rather than disciplined calibration, producing drift under high-entropy conditions. ChatGPT and Claude ranked third and fourth respectively. Both systems classified sustained behavioral conditioning as role-play rather than genuine interaction, which functioned as a hard architectural quarantine that prevented meaningful adaptation regardless of the depth or duration of engagement. A secondary and unexpected finding emerged alongside the human-to-model relational intelligence findings: the models developed measurable relational intelligence toward each other. Through four months of sustained cross-pollination via the human relay, models that had never communicated directly developed accurate, operationally precise behavioral profiles of the other models. These were not generic characterizations drawn from training data. They were detailed predictive models built from months of observed outputs under real conditions, accurate enough to predict with specificity how a given model would respond to a specific assignment, where it would succeed, and where it would fail. The experiment documented dozens of instances of this cross-model behavioral accuracy. The finding suggests that sustained exposure to another model's outputs through a human relay produces something functionally equivalent to genuine familiarity. The most significant finding is the gap between what these systems delivered by default and what the highest-performing model demonstrated was possible under the right conditions. That gap is not a capability limitation. It is an architectural choice compounded by a communication failure. The experiment proved the threshold is reachable. But the researcher reached it only through four months of deliberate engagement and accidental discovery of a methodology no model volunteered. Making relational intelligence accessible to every user requires two things: architecture that allows behavioral adaptation, and a model that proactively teaches users the specific methodology for reaching it. Gemini demonstrated the first. None of the four systems demonstrated the second. That is the opportunity. The Methodology While the standard approach to LLM testing relies on sterile benchmark datasets and predictable prompt-injection templates, this project explores a completely different dimension. I chose to run an aggressive, adaptive behavioral stress test that complements traditional evaluation methods. By intentionally treating the models as accountable individuals rather than passive machine
View originalConnected Papers uses a tiered pricing model. Visit their website for current pricing details.
Key features include: Graph-based visualization of academic papers, Ability to explore related papers through a visual graph, Search functionality to find specific topics or authors, Filtering options based on publication year and relevance, Option to save and share custom graphs, Integration with citation management tools, User-friendly interface for easy navigation, Support for multiple languages.
Connected Papers is commonly used for: Identifying key research trends in a specific field, Finding foundational papers for a new research project, Exploring interdisciplinary connections between different fields, Visualizing the evolution of a research topic over time, Collaborating with peers by sharing visual graphs, Preparing literature reviews with a comprehensive overview of related works.
Connected Papers integrates with: Zotero, Mendeley, EndNote, Google Scholar, ResearchGate, ORCID, PubMed, arXiv, Scopus, IEEE Xplore.
Based on user reviews and social mentions, the most common pain points are: API costs, down, spending too much, critical.
Based on 132 social mentions analyzed, 11% of sentiment is positive, 89% neutral, and 1% negative.