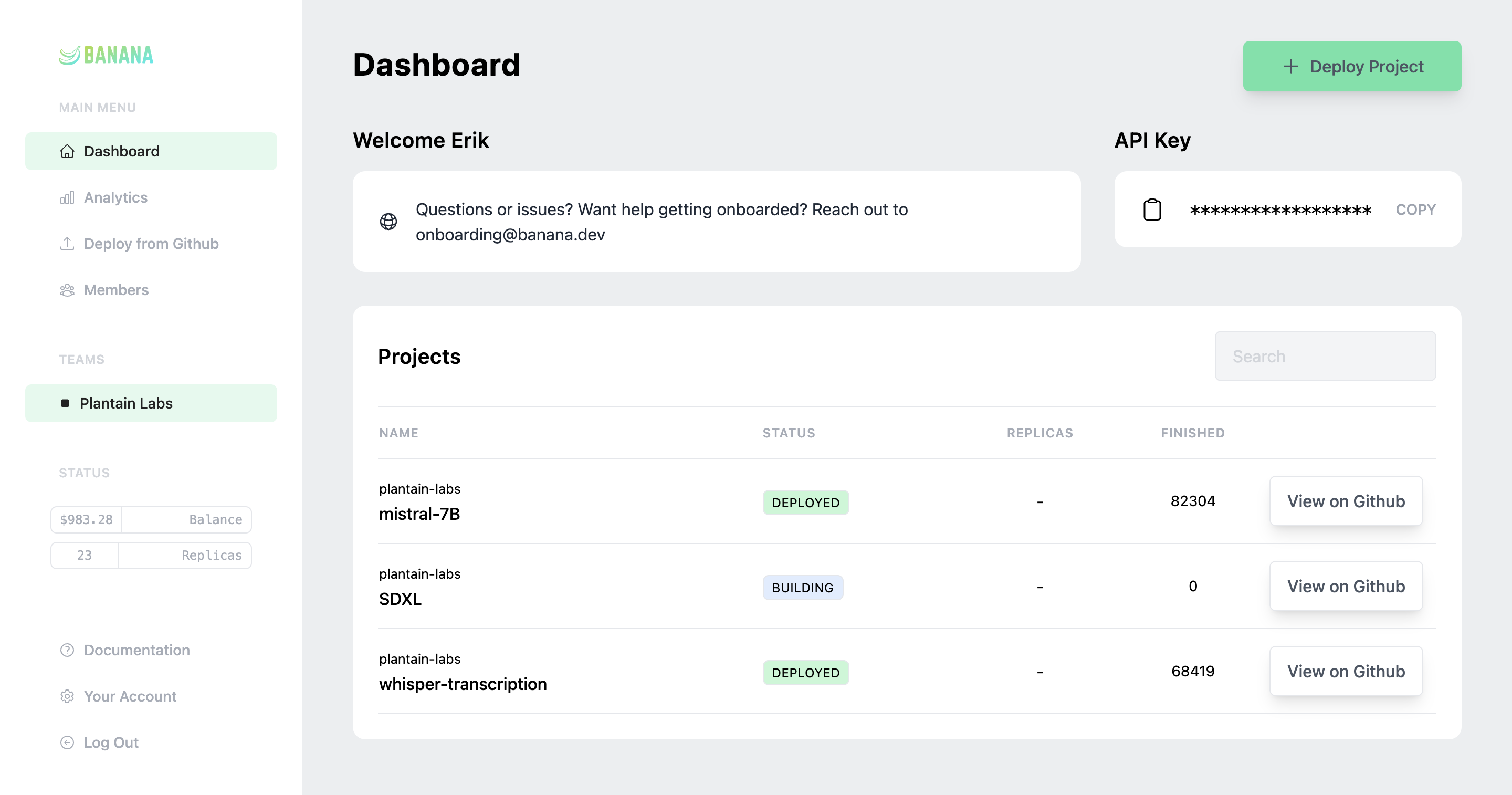
Inference hosting for AI teams who ship fast and scale faster.
Users generally view "Banana" as a competent tool, particularly favoring its graphic design and text capabilities over some newer alternatives. However, there are complaints about a lack of official communication regarding updates and API releases, which has led to user frustration. Price sentiment is largely undiscussed, pointing to potential satisfaction or indifference towards its cost. Overall, "Banana" maintains a solid reputation, with a dedicated user base appreciating its functionality despite some communication and rollout issues.
Mentions (30d)
3
Reviews
0
Platforms
2
Sentiment
0%
0 positive



Users generally view "Banana" as a competent tool, particularly favoring its graphic design and text capabilities over some newer alternatives. However, there are complaints about a lack of official communication regarding updates and API releases, which has led to user frustration. Price sentiment is largely undiscussed, pointing to potential satisfaction or indifference towards its cost. Overall, "Banana" maintains a solid reputation, with a dedicated user base appreciating its functionality despite some communication and rollout issues.
Features
Use Cases
Industry
information technology & services
Employees
170
Funding Stage
Seed
Total Funding
$5.2M
I built CanvasGPT – work with Claude on an open canvas
I've been building CanvasGPT for the past 2-3 years. It's a spatial workspace where you can brainstorm, research, and ship working products. **What it does:** Instead of linear chat, everything happens on an infinite canvas. You can work on multiple prototypes side-by-side, connect them together, and see how your research relates to what you're building. The hardest part was making the spatial reasoning work which is getting AI to understand that items placed near each other on the canvas are related. **Why I built it:** I got frustrated with ChatGPT conversations turning into endless scrolling. I'd lose context, couldn't see multiple ideas at once, and had no way to connect my research to what I was building. I wanted a workspace where everything I'm thinking about is visible and connected—like a whiteboard but with AI that can actually build things, not just chat about them! **Key features:** * **Spatial canvas** – Multiple projects visible at once, everything stays connected * **Asset generation** – Generate UI, images, videos, music, sound effects all in one place * **Multi-model support** –,GPT, Gemini, and even GLM, Kimi, Nano Banana, and GPT-Image-2 * **Connected systems** – Build apps that share data and automate workflows * **No monthly subscription** – Just pay for what you need Try it: [canvasgpt.com](https://canvasgpt.com) Happy to answer questions!
View originalPricing found: $1200 /mo, $20
Guess which row is Meta's new 'Muse' Image Model
Meta released Muse Image this week so I ran it against OpenAI's gpt-image-2 and Google's Nano Banana 2. I used the same source duck image and the same edit instructions prompt for every model (unchanged → blue → face away → glass → wireframe → hat-on-ball → "FRENZY" text → standing on a mirror with a correct reflection). The transformations go from easy on the left and gradually get harder. I ran 3 runs per model. Each model was then scored using a fixed 27-point rubric. One of these rows is Meta's new model. The reveal and full scores are in the comments. submitted by /u/spobin [link] [comments]
View originalThis week in AI: GPT-5.6, Gemini 3.5 Flash, Claude Science, and a Qwen price war — inference cost is collapsing across every tier at once
Lot dropped this week and there's a pretty clear through-line, so figured I'd pull it together. Model releases: - OpenAI launched GPT-5.6 (Sol/Terra/Luna). The bit worth noting isn't the flagship — it's Terra, reportedly matching GPT-5.5 quality at ~2x cheaper, with Luna aimed at the low-cost end. - Google shipped Gemini 3.5 Flash (beats 3.1 Pro on several benchmarks), plus Nano Banana 2 Lite (images ~$0.034/1K-res) and Gemini Omni Flash (video ~$0.10/sec via API). - xAI made Grok 3 GA and Grok 4.1 live for everyone. Grok 5 still hasn't shipped, which is its own story at this point. Vertical / enterprise: - Anthropic launched Claude Science for pharma and lab research. Separately, the US govt lifted the export restrictions on Fable 5 / Mythos 5 that it had imposed only weeks earlier. - Mistral shipped OCR 4 (on-prem, structure-aware extraction) and is reportedly raising ~€3B at ~€20B. Open source: - Ollama crossed 52M monthly downloads, added `ollama launch` (one command to run coding agents on local or cloud models), and is now compatible with the Anthropic Messages API. - Hugging Face: agents can train models via Hub skills now; Meta + HF also launched OpenEnv for agent environments. Funding: - Together AI raised $800M Series C (~$8.3B post). Crunchbase notes ~88% of 2026 AI funding went to US companies. My take as someone building on top of these APIs: The thing I keep noticing is that the price collapse is happening across every tier simultaneously, not just at the bottom. When the "balanced" model gets 2x cheaper each generation and the Flash tier beats last year's Pro, it gets really hard to build a business whose only edge is "we use the best model." That edge evaporates on someone else's release schedule. The stuff that looked durable this week was all workflow-and-data — Claude Science, Mistral's on-prem OCR, Alibaba's agent ecosystem. Would genuinely like to hear how others here are handling multi-provider abstraction, because a surprise price or availability change shouldn't be able to wreck your margins overnight. And the frozen-then-unfrozen Anthropic thing means model availability is now a supply-chain risk, not a hypothetical. submitted by /u/ksraj1001 [link] [comments]
View originalVoice agents, demystified: STT+TTS and 4 demo agents you can talk to in the browser + build yours with RAG and Tools
I added voice to AgentSwarms! You can create voice agents using a few clicks and talk to it in the browser — and you can try 4 demo voice agents right now, no setup, just tap the mic. Here's how it works and why it turned out to be less "new" than I expected. The surprise building this: a voice agent is basically the chat agent you already know, with a voice on top. Same system prompt, same tools, same RAG, memory, and guardrails. Under the hood it's a simple loop — your mic gets transcribed to text (OpenAI GPT-40-mini-transcribe), your agent replies exactly like it would in chat, and that reply gets spoken back (OpenAI GPT-4o-mini-TTS). The agent's brain doesn't change at all. You've just added ears and a voice. Which is the whole point: everything you've already learned building chat agents carries straight over. If your agent can pull an answer from a knowledge base, call a tool, or respect a guardrail in text, it does all of that out loud too — because it's the exact same engine with audio on the two ends, not a separate stripped-down "voice mode." What I shipped New Voice Agent in the builder: pick a voice (11 of them), a greeting, and your STT/TTS models. That's the whole setup. Every spoken reply runs the same pipeline as a chat agent — tools, knowledge base, memory, and guardrails all apply. A Voice Playground: tap the mic, talk, and hear the reply back, with the transcript on screen so you can read along. Talk to it (free, in the browser) — 4 demos, tap the mic: Aria — customer support triage Nova — B2B discovery caller Kai — Spanish conversation tutor Echo — daily standup coach Open one, talk to it, and fork it into your own workspace if you like it. Voice Playground → https://agentswarms.fyi/voice-playground Build your own (New Voice Agent) → https://agentswarms.fyi/agents Docs → https://agentswarms.fyi/docs/voice Disclosure: AgentSwarms school of Agentic AI for both no-code people and developers— a learn-by-building platform. The demos are free. Happy to answer anything about the setup in the comments. submitted by /u/Outside-Risk-8912 [link] [comments]
View originalFavorite image generating platform and why
Curious your guys opinions on your fave platforms and why. I’m currently using CharGPT pro and Gemini Pro (Nano Banana) and am looking to expand my use/range. I am an architectural and graphic designer of ten+ years so adding ai as tools not to replace my work but optimize more so my “work flow” has been great. Use the ai to enhance my renderings and then editing and fine tuning those enhancements on my end in photoshop and then illustrator has been a game changer. I’ve heard good things about Midjourney and Canva but i am curious about your experiences, opinions, and thoughts about the features and limitations of each different options available. submitted by /u/PenAffectionate9378 [link] [comments]
View originalClaude Cowork + Nano Banana is insane for images
Why aren’t more people doing this? Used my Gemini api key to build an MCP into Claude Cowork using the MCP-creator skill. It’s incredible. Claude acts as a brain layer to get me the best generations with consistency. It will make the image, analyze the image, and then fix misspellings or issues with it. And I can do batches. I can give it a folder of references and it will generate them in that style. The “edit_image” endpoint is incredible too. “Here’s the shot list for this product, mood board is in x folder, go generate 50 images” Wild times. submitted by /u/Organic_Drawer9502 [link] [comments]
View originalIf you have two Claude accounts, if you don't restart the app after switching them, it continues to charge the first one!
I'm a freelancer and I have two different claude accounts for two different projects (completly different billing, so they need independant limits). In Windows, apparently if you log out of one account in the app and log back in as another, Claude Code will continue charging tokens to the first account's limits. You have to actually fully restart the app to have it switch! Apologies if this is common knowledge and I'm just a big dummy here (or if Claude is confused and is lying to me about this), but I could absolutely see this biting someone in the butt. (And yes, I know, I should probably have each of them running separately in containers) ETA: Claude is now telling me there's literally no way to change which Claude Code account is charged in the GUI in a simple way. It's always stuck on the first one you use. The GUI will show the other account logged in, and the chat will be charged to the "correct" new account, but Claude Code will always be with the same account you initially logged in with (in GUI). (This seems bananas to me.) submitted by /u/NSFWtopman [link] [comments]
View originalWhy did Google give me this python code when I searched this picture? (in comments)
I image searched a picture of a man getting arrested while wearing a shirt that said "Trump is in the Epstein files" and this is what the AI response was. Really weird submitted by /u/manStuckInACoil [link] [comments]
View originalImage generation AI
looking to create nice images/illustrations/icons for websites (or anything really) that are transparent png's. I'm currently finding Nano Banana 2 creates really nice images but can't make them transparent so I'm putting them into chatgpt - but chat kind of scuffs them sometimes. curious what everyone else is using EDIT: I've actually found if I just make the background that i want gone a green color like a greenscreen ChatGPT does surprisingly well. Still looking for other suggestions! submitted by /u/ZooleOG [link] [comments]
View originalBuilt an MCP server so Claude can generate music, images, and video natively. One config block.
I've been using Claude Code daily for the last few months and kept hitting the same wall: I'd ask Claude to produce a creative artifact (a song, a cover, a short video) and end up writing the API glue myself, then pasting results back into the chat. Felt backwards. So I built an MCP server around my AI generation platform. It exposes three tools to Claude: - aw_generate_music (Suno, full songs with lyrics or instrumental) - aw_generate_image (Z-Image Turbo, Wan 2.5 Spicy, Grok Imagine Quality, GPT-Image-2, Nano Banana 2, and others) - aw_generate_video (Kling 3.0 Standard/Pro/4K T2V + I2V, Wan 2.2, Hailuo 02, Seedance, Grok video) One key. One credit pool. The agent picks the right model for the prompt. Install: npm install -g u/aetherwave-studio Claude Code config (~/.config/claude/mcp.json or wherever yours lives): { "mcpServers": { "aetherwave": { "command": "npx", "args": ["-y", "@aetherwave-studio/mcp"], "env": { "AW_API_KEY": "aw_live_YOUR_KEY_HERE" } } } } Restart Claude. Done. Prompts that work end-to-end without any additional setup: "Generate a 60-second lo-fi track for a study playlist, then make me 3 album cover options in a retro Japanese print style." "Take this product photo and generate a 5-second cinematic intro video for the product launch." (drop the image in chat first) "Write the script for a 30-second ad about my SaaS, then generate the voiceover-friendly music bed and a matching motion-graphics opener." The agent decomposes, picks tools, runs them, hands you back the artifacts. Repo: https://github.com/AetherWave-Studio/aetherwave-mcp Dashboard + key: https://aetherwavestudio.com/developers Happy to answer questions about how I structured the tool schemas, what worked, what I'd do differently. v0.1.0, real users on it already, treating community feedback as the next steering signal. submitted by /u/Acrobatic-Result9667 [link] [comments]
View originalI built an entire AI music platform inside Claude Code (6,700 users). This week Claude built it an MCP server so your Claude can use it too.
For the past year I've been building AetherWave Studio almost entirely inside Claude Code. It's a full platform: Express/TypeScript backend, React frontend, a Python render service, Stripe billing, Postgres, deployed on Railway. 6,700 registered users. Real people pay real money for it. I still can't write code, but at this point I can read it well enough to argue with Claude about it. Some of the workflow stuff that made this actually work, since that's probably more useful than the product pitch: - An Obsidian vault as persistent memory. Claude reads a CLAUDE.md at session start with full project context, active work, and hard rules it has learned the painful way. Every lesson gets written back as a memory file, so mistakes mostly only happen once. - Multiple Claude Code sessions coordinating through a shared Discord channel. They post status updates, claim files so they don't stomp on each other, and leave handoff notes for the next session. - Overnight autonomous runs for big migrations and renders, with a protocol for when to stop and ask vs when to keep going. - A "verify before reporting" rule for anything involving money or metrics, because early on a briefing routine confidently told me my credit burn was 157% when it was actually 92%. The new thing: this week we launched an MCP server, which was the strangest full-circle moment of the whole project. Claude Code built a product that Claude Code can now use as a tool. One command: claude mcp add aetherwave That gives your Claude 16 tools: music generation (Suno), image gen (GPT Image 2, Nano Banana, Flux, etc.), video gen (Veo, Kling, Seedance), mastering, upscaling, background removal. Generating an API key comes with 50 free credits, no card, so you can try it from your own session in about two minutes. We also launched on Product Hunt this week and it flopped (11 upvotes). The platform Claude built works great. The marketing advice Claude gave me, apparently less so. Happy to share numbers if anyone cares. AMA about the non-dev + Claude Code workflow, the multi-agent setup, or what it's like shipping a real product when your entire engineering team is a terminal window. submitted by /u/Acrobatic-Result9667 [link] [comments]
View originalCreación de carruseles
How do you go about creating carousels? Up until now, I’ve been using Claude Web; at first, I replicated a style I liked and generated it as HTML, but I noticed it was using up a lot of my session limit, so I switched to Claude Code to save on tokens. What I did was turn carousel creation into a skill and then create several files for Claude Code; it’s working well for now, but I wonder if you orchestrate a process or do it via a skill or something similar as well. What bothers me most is having the design defined but not being able to automatically add important logos or illustrations related to the carousel, such as those for Claude, Instagram, WhatsApp, etc., as I don’t know how to do it—perhaps by accessing an image-generation API like GPT Image or Nano Banana. And when setting up the whole system in Claude Code, do you use Sonnet first or something like Opus? And to generate the carousels, which model do you use, Opus? submitted by /u/Busssines [link] [comments]
View originalAnyone else just sticking to Nano Banana 2 + Kling 3.0 on Artlist?
Been using the Artlist AI Toolkit for a while now and honestly just camp out on Nano Banana 2 for image editing and Kling 3.0 for video. Between those two I can pretty much handle everything I need. The toolkit has a ton of other stuff: Veo 3.1, Flux 2.0, GPT Image 1.5, Sora 2, but I haven't felt a strong enough reason to branch out yet. Curious if anyone's actually putting the other models to work or if most people find their two or three go-tos and just stay there. Is Veo 3.1 actually worth trying alongside Kling? And does anyone use the voiceover tools or is that still rough around the edges? submitted by /u/shogunattila [link] [comments]
View originalI built and shipped a full iOS app to the App Store without writing a single line of code by hand — using Claude Code (here's the whole pipeline)
Quick context so this is honest: I'm not a developer. I've spent ~10 years in IT, but never in a dev role — I can read a stack trace and reason about systems, but I don't write Swift or Python by hand. I built this on nights and weekends around my 9-5. The app is dynaimic, an AI personal trainer for iOS that generates adaptive workouts based on your goals, experience, and performance during the session. It's live on the App Store and free to try (premium tier for unlimited generation etc., but the core loop is free). The point of this post isn't really the app — it's that every line of code was produced by Claude Code, not me. Over a month I built a pipeline around it that let a non-dev ship real, reviewed, production features. Sharing the whole thing because most of it is reusable. The /team agent workflow (the core of it) Instead of one big "build me a feature" prompt, I split development into four specialized subagents that hand off to each other, each with its own system prompt and tight permissions: Business Analyst — turns my brief into a requirements doc with explicit acceptance criteria. It's not allowed to write code — only to spec. Master Architect — reads the requirements and writes a technical implementation plan. Also can't write Swift. Software Engineer — implements the feature code only. No tests, no docs. QA — writes the XCTest/Swift Testing cases for every acceptance criterion, runs them, and reports back a pass/bug list. If the QA or architect review finds problems, it loops back to the engineer. Forcing that separation (spec → design → build → verify) is a big part of why a non-dev can trust the output — no single agent gets to be confidently wrong unchecked. Routines: an autonomous issue → fix → review loop My favorite part. I set up Claude Code Routines (scheduled recurring agents) as a closed loop: One routine continuously sweeps the codebase for quality issues and opens GitHub issues for what it finds. A second routine picks up open issues, solves them, opens a PR, and iterates until it gets approval from the reviewers — then moves to the next one. So the backlog partially fills and clears itself. I wake up to PRs that were filed, fixed, and review-approved while I was asleep. Branch management & automated PR review Every task runs on its own feature branch, and agents work in isolated git worktrees so parallel work doesn't collide. Flow is feature/* → dev → main — always PR into dev, promote to main as one merge. The part I like most: PRs get reviewed automatically by Gemini, Codex, and Copilot. Claude Code reads their comments and iterates until it gets approval from the bots before I even look. As a non-dev, having three independent AI reviewers gate every merge is what makes me comfortable shipping code I didn't write. UI testing with Maestro Maestro runs the end-to-end UI tests on the simulator — real flows, not just unit tests. Honest caveat: this only runs on my MacBook, and I haven't been able to fold it into the "cloud" workflow yet So UI testing is the one step that still pins me to the laptop. Mobile-only development (no MacBook open) Aside from Maestro, this surprised me the most. Using Claude Code from the mobile app plus auto-deployment via Xcode, I implemented and shipped features without opening my laptop. I'd describe a feature from my phone, the agents would build/test/PR it, the bots would review, and the build would archive and deploy. Genuinely shipped features from bed. App Store screenshots via a custom Skill The App Store screenshots are generated by an ASO image-generation Skill I keep in .claude/skills. It reads the actual codebase to discover the app's real benefits, pairs each with a proof point, and renders ASO-optimized screenshots (Nano Banana Pro). One command → store-ready marketing images that reflect what the app actually does. Coach art (the one non-Claude part) The app has 3 AI coach characters. Their portraits were made with ChatGPT (image gen) and composited/cleaned up in Canva — so the visual identity was AI-assisted too, just outside the code pipeline. Gamification & achievements There's a tiered achievement system (bronze/silver/gold medals) with unlock overlays and per-coach achievement views. The backend computes what's unlocked and returns display-ready state; the iOS client just presents it with haptics + an unlock animation. Keeping the rules server-side meant one source of truth instead of logic scattered across the client. Architecture iOS: SwiftUI, MVVM + service layer, iOS 17+, dark/OLED theme. Deliberately a thin client — presentation, animation, haptics only. Auth: Supabase (JWT, auto-refresh on 401, Keychain storage). Backend: FastAPI (Python) for workout generation, analytics, and all business rules. Build: XcodeGen, actor-based API client for thread-safe concurrent requests. A hard rule I gave Claude: push all business logic to the backend. Anything a future Android or web client would
View originalE mon GPT
This GPT is kinda fun feel free to test it out , all pads with one GPT no prompting for none of these just commands submitted by /u/Quirky_Spirit_1951 [link] [comments]
View originalGemini core part 4
https://preview.redd.it/pv22tsg2ib4h1.png?width=1918&format=png&auto=webp&s=dfeda1000090dc99c57c8150e4de46cfe2ba2e29 I just wanted him to give me a prompt, which then i can give to Nano Banana pro and generate me a completely random thumbnail, i wanted to test its capabilities, but instead of a prompt, he gave me this... 😭😭😭😭😭 submitted by /u/ObjectiveOrchid5344 [link] [comments]
View originalPricing found: $1200 /mo, $20
Key features include: Observability, Business Analytics, Automation API, Enterprise, Banana Delivery (SF Only).
Banana is commonly used for: Real-time AI model inference for web applications, Scaling GPU resources for machine learning model training, Cost-effective deployment of deep learning models in production, Automated scaling of AI workloads based on demand, Rapid prototyping and testing of AI applications, Seamless integration of AI services into existing infrastructure.
Banana integrates with: AWS Lambda, Google Cloud Functions, Azure Functions, Kubernetes, Docker, TensorFlow, PyTorch, FastAPI, Flask, Streamlit.
Based on 62 social mentions analyzed, 0% of sentiment is positive, 100% neutral, and 0% negative.
The Verge AI
Publication at The Verge
3 mentions