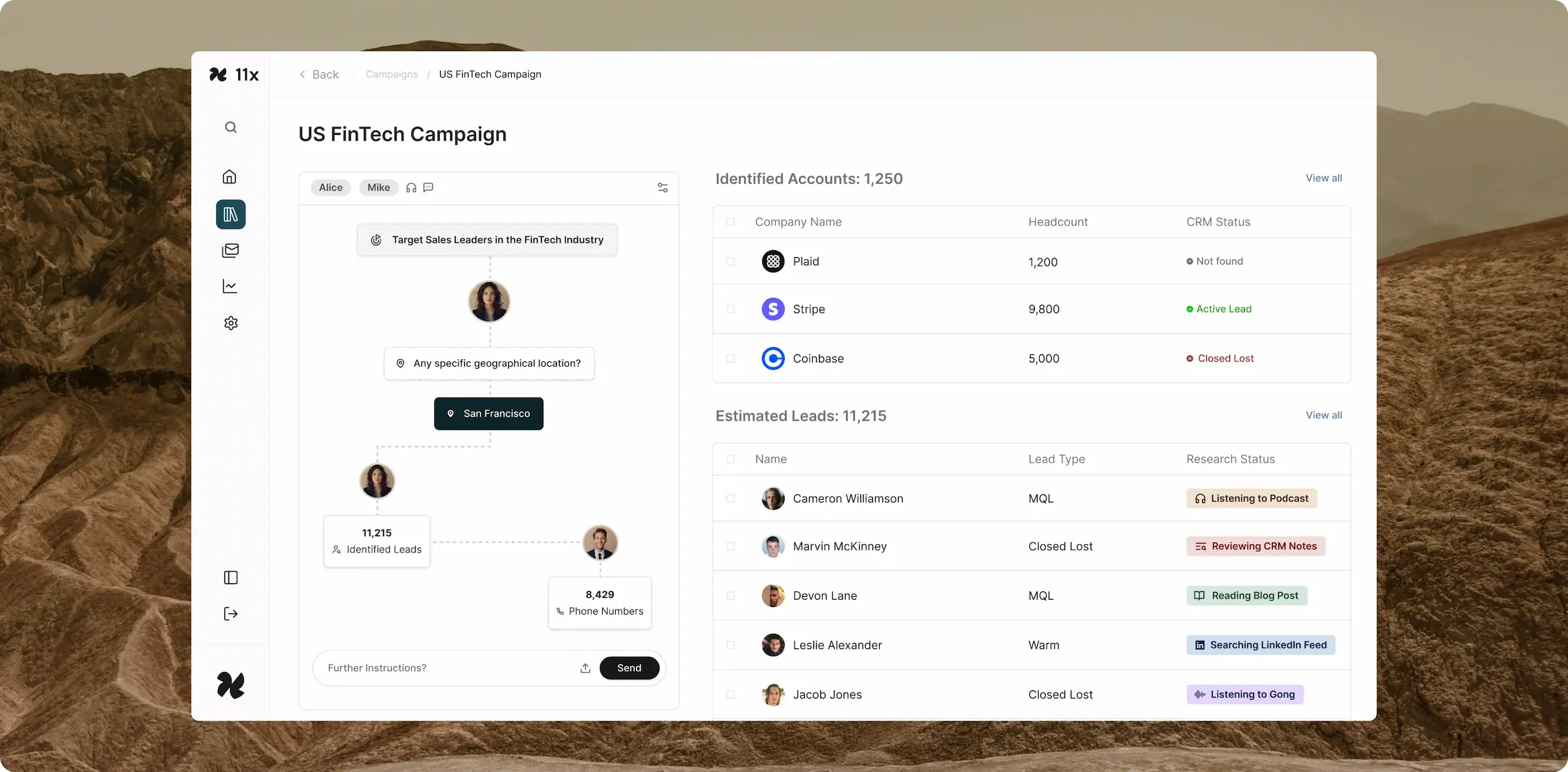
For Sales, RevOps, and GTM Leaders. Transform your revenue team with digital AI workers that execute, learn, and optimize across all customer touchpoi
Users frequently highlight the efficiency and advanced features of 11x, particularly praising its ability to streamline workflows. However, some reviewers note concerns about the potential learning curve and limited documentation that could hinder initial user experience. Pricing sentiment appears neutral, with no significant comments suggesting it is either a primary advantage or disadvantage. Overall, 11x holds a positive reputation for its innovative capabilities, though users suggest further improvements in user support resources.
Mentions (30d)
1
1 this week
Reviews
0
Platforms
2
Sentiment
0%
0 positive



Users frequently highlight the efficiency and advanced features of 11x, particularly praising its ability to streamline workflows. However, some reviewers note concerns about the potential learning curve and limited documentation that could hinder initial user experience. Pricing sentiment appears neutral, with no significant comments suggesting it is either a primary advantage or disadvantage. Overall, 11x holds a positive reputation for its innovative capabilities, though users suggest further improvements in user support resources.
Features
Use Cases
Industry
information technology & services
Employees
150
Funding Stage
Series B
Total Funding
$102.0M
Pricing found: $70, $1
Anthropic just published a pretty alarming 2028 AI scenario paper and it's not about AGI safety in the usual sense
Anthropic dropped a new research paper today outlining two possible futures for global AI leadership by 2028, and it reads more like a geopolitical briefing than a typical AI safety paper. The core argument: The US currently has a meaningful lead over China in frontier AI, primarily because of compute (chips). American and allied companies (NVIDIA, TSMC, ASML, etc.) built technology China simply can't replicate yet. Export controls have made that gap real. But China's labs have stayed surprisingly close through two workarounds: Chip smuggling + overseas data center access - PRC labs are apparently training on export-controlled US chips they shouldn't have. A Supermicro co-founder was recently charged for diverting $2.5B worth of servers to China. Distillation attacks - creating thousands of fake accounts on US AI platforms, harvesting model outputs at scale, and using that to train their own models. Essentially free-riding on billions in US R&D. The two scenarios for 2028: Scenario 1 (good): US closes the loopholes, enforces export controls properly, the compute gap widens to 11x, and US models stay 12-24 months ahead. Democracies set the norms for how AI is governed globally. Scenario 2 (bad): US doesn't act, China reaches near-parity, floods global markets with cheaper models, and the CCP ends up shaping global AI norms, including potentially exporting AI-enabled surveillance tools to other authoritarian governments. What makes this interesting beyond the politics: Their new model, Mythos Preview (released to select partners in April), apparently let Firefox fix more security bugs in one month than in all of 2025. That's the kind of capability jump they're warning China shouldn't be the first to achieve, specifically around autonomous vulnerability discovery. The framing worth discussing: Anthropic is explicitly calling distillation attacks "industrial espionage" and pushing for legislation to criminalize them. This positions them as political actors, not just AI researchers. Whether that's appropriate for an AI lab is a conversation worth having. What do you think - is the compute gap as decisive as they claim, or is algorithmic innovation enough to close it? submitted by /u/Direct-Attention8597 [link] [comments]
View originalengram v0.2: Claude Code now indexes your ~/.claude/skills/ directory into a query-able graph + warns you about past mistakes before re-makin
Body: Short v0.2 post for anyone running Claude Code as a daily driver. v0.1 shipped last week as a persistent code knowledge graph (3-11x token savings on navigation queries). v0.2 closes three more gaps that have been bleeding my context budget: 1. Skills awareness. If you've built up a ~/.claude/skills/ directory, engram can now index every SKILL.md into the graph as concept nodes. Trigger phrases from the description field become separate keyword concept nodes, linked via a new triggered_by edge. When Claude Code queries the graph for "landing page copy", BFS naturally walks the edge to your copywriting skill — no new query code needed, just reusing the traversal that was already there. Numbers on my actual ~/.claude/skills: 140 skills + 2,690 keyword concept nodes indexed in 27ms. The one SKILL.md without YAML frontmatter (reddit-api-poster) gets parsed from its # heading as a fallback and flagged as an anomaly. Opt-in via --with-skills. Default is OFF so users without a skills directory see zero behavior change. 2. Task-aware CLAUDE.md sections. engram gen --task bug-fix writes a completely different CLAUDE.md section than --task feature. Bug-fix mode leads with 🔥 hot files + ⚠️ past mistakes, drops the decisions section entirely. Feature mode leads with god nodes + decisions + dependencies. Refactor mode leads with the full dependency graph + patterns. The four preset views are rows in a data table — you can add your own view without editing any code. 3. Regret buffer. The session miner already extracted bug: / fix: lines from your CLAUDE.md into mistake nodes in v0.1, they were just buried in query results. v0.2 gives them a 2.5x score boost in the query layer and surfaces matching mistakes at the TOP of output in a ⚠️ PAST MISTAKES warning block. New engram mistakes CLI command + list_mistakes MCP tool (6 tools total now). The regex requires explicit colon-delimited format (bug: X, fix: Y), so prose docs don't false-positive. I pinned the engram README as a frozen regression test — 0 garbage mistakes extracted. Bug fixes that might affect you if you're using v0.1: writeToFile previously could silently corrupt CLAUDE.md files with unbalanced engram markers (e.g. two and one from a copy-paste error). v0.2 now throws a descriptive error instead of losing data. If you have a CLAUDE.md with manually-edited markers, v0.2 will tell you. Atomic init lockfile so two concurrent engram init calls can't silently race the graph. UTF-16 surrogate-safe truncation so emoji in mistake labels don't corrupt the MCP JSON response. Install: npm install -g engramx@0.2.0 cd ~/your-project engram init --with-skills # opt-in skills indexing engram gen --task bug-fix # task-aware CLAUDE.md generation engram mistakes # list known mistakes MCP setup (for Claude Code's .claude.json or claude_desktop_config.json): { "mcpServers": { "engram": { "command": "engram-serve", "args": ["/path/to/your/project"] } } } GitHub: https://github.com/NickCirv/engram Changelog with every commit + reviewer finding: https://github.com/NickCirv/engram/blob/main/CHANGELOG.md 132 tests, Apache 2.0, zero native deps, zero cloud, zero telemetry. Feedback welcome. Heads up: there's a different project also called "engram" on this sub (single post, low traction). Mine is engramx on npm / NickCirv/engram on GitHub — the one with the knowledge graph + skills-miner + MCP s submitted by /u/SearchFlashy9801 [link] [comments]
View originalPricing found: $70, $1
Key features include: Always learning, Customised to you, Deeply integrated, Autonomous Intelligence, Enterprise-ready, From prospecting to closing: All-in-one, 1.5x increase, $1M+ pipeline.
11x is commonly used for: Lead generation and qualification, Multilingual customer support, Sales outreach automation, Data entry and CRM updates, Market research and analysis, Follow-up scheduling and reminders.
11x integrates with: Salesforce, HubSpot, Slack, Microsoft Teams, Zapier, Mailchimp, Google Workspace, Zendesk, Pipedrive, Intercom.
Julien Chaumond
CTO at Hugging Face
1 mention